
Author: Pier Bover
Date: Oct 01, 2020
Today we're going to explore some of the aggregate functions of FQL and a number of techniques for data aggregation.
This series assumes you have a grasp on the basics. If you're new to FaunaDB and/or FQL here's my introductory series on FQL.
In this article:
- Introduction
- Basic aggregate functions
- Retrieving data for aggregation
- Grouping results
- Ultimate robots report
Introduction
The basic idea of data aggregation is to perform one or more calculations over a set of values. Common aggregation tasks include computing the total, average, range, standard deviation, etc. In other words, you can answer questions such as "How many spaceships are currently stationed in our Moon base?" or "What's the average duration of spaceship repairs?".
Before we get into the nuts and bolts, let's prepare some data that we can aggregate.
First, let's create a collection and a simple index to retrieve all of the references of its documents:
> CreateCollection({
name: "Robots"
})
> CreateIndex({
name: "all_Robots",
source: Collection("Robots")
})
Also, let’s create some documents:
> Create(
Collection("Robots"),
{
data: {
name: "R3-D3",
type: "ASTROMECH",
weightKg: 20
}
}
)
> Create(
Collection("Robots"),
{
data: {
name: "BB-9",
type: "ASTROMECH",
weightKg: 10
}
}
)
> Create(
Collection("Robots"),
{
data: {
name: "David",
type: "ANDROID",
weightKg: 90
}
}
)
> Create(
Collection("Robots"),
{
data: {
name: "T1000",
type: "ANDROID",
weightKg: 150
}
}
)
> Create(
Collection("Robots"),
{
data: {
name: "ASIMO",
type: "HUMANOID",
weightKg: 48
}
}
)
Basic aggregate functions
Count
To be able to count the elements in an array, we use the Count() function:
> Count(["A", "B", "C"])
3
Many functions in FQL that accept arrays as input also work with other types. For example, Count() also works with a SetRef returned by Documents() or Match():
> Count(Documents(Collection("Robots")))
5
> Count(Match(Index("all_Robots")))
5
Documents() is a helper function that performs exactly the same function as the all_Robots index, and returns the set of references for all documents in a collection.
We can also count how many items are returned in a page by the Paginate() function:
> Count(Paginate(Match(Index("all_Robots"))))
{
data: [5]
}
You might be wondering why the result is not exactly a number but an object with a data property. FaunaDB is actually returning a Page because we used the Page returned by Paginate() instead of an array.
Many FQL functions that use arrays as inputs behave this way when receiving a page. Consult the docs for more information on this.
Min/max values
To determine the max value in an array we use the Max() function:
> Max([22, 4, 63])
63
It also works with strings or dates:
> Max(["A", "B", "C"])
C
> Max([
Date("2000-01-01"),
Date("2010-01-01"),
Date("2020-01-01")
])
Date("2020-01-01")
As you probably have guessed, we use Min() to determine the minimum value and it works in the exact same fashion:
> Min([22, 4, 63])
4
On top of numbers, strings, and dates, both Min() and Max() work with other FaunaDB types. Check the documentation for more information.
Summing values
To sum a list of values we use the Sum() function:
> Sum([1,2,3,4,5])
15
Obviously, it only works with numbers. If you want to concatenate strings, you would use the Concat() function.
Unique values
Another useful FQL function for aggregation queries is Distinct() which returns the unique values in an array:
> Distinct(["A", "B", "A", "C", "C"])
["A", "B", "C"]
As we'll see later, this becomes quite handy for grouping results.
Retrieving data for aggregation
In relational databases, aggregate functions are used on a column of data (either from a table or the results of a query). FaunaDB uses documents as its underlying storage, so these calculations are done over arrays. The approach is very similar to what you'd do in regular programming using functional style techniques, which FQL naturally lends itself to.
Let's answer the following question: what's the total weight of all our robots?
Using indexes
The first approach to getting data for aggregation is using indexes. This is the most cost-effective approach as it consumes a single read operation per page returned. Indexes do not read every document they index on every query. Instead, they return data that has been pre-written, so to speak.
You can check how many operations a query has performed by hovering over the little icon on the sidebar of the shell results:
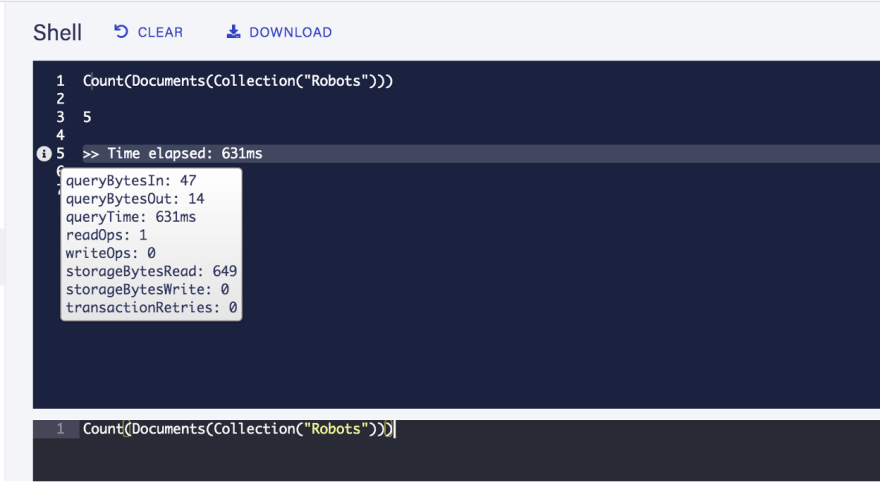
First, let's create an index that returns all of the weights of all our robots:
> CreateIndex({
name: "Robots_weights",
source: Collection("Robots"),
values: [
{field: ["data", "weightKg"]}
]
})
By default, this is what our index returns:
> Paginate(Match(Index("Robots_weights")))
{
data: [10, 20, 48, 90, 150]
}
So now can just use Sum() with the results of the index:
> Sum(Paginate(Match(Index("Robots_weights"))))
{
data: [318]
}
Aggregating the result of Map/Get
The second approach is to iterate over a number of documents and extract the relevant data into an array.
This approach is certainly more flexible, as you won't need to create a new index for every value that you want to aggregate, but it consumes a read operation every time you Get() a document. You should evaluate which approach fits your use case better and choose between efficiency and flexibility.
Before we actually sum all of the weights, let's see how to collect those values into an array:
> Let(
{
docs: Map(
Paginate(Documents(Collection("Robots"))),
Lambda("ref", Get(Var("ref")))
),
weights: Map(
Var("docs"),
Lambda("doc", Select(["data", "weightKg"], Var("doc")))
)
},
Var("weights")
)
{
data: [20, 10, 90, 150, 48]
}
- First we get all of the documents and put them into the docs binding. Again, we could have used our all_Robots index instead of the Documents() helper.
- Then we create a weights array by iterating over those documents with Map() and selecting the weightKg value.
We can now just use Sum() to calculate the total weight:
> Let(
{
docs: Map(
Paginate(Documents(Collection("Robots"))),
Lambda("ref", Get(Var("ref")))
),
weights: Map(
Var("docs"),
Lambda("doc", Select(["data", "weightKg"], Var("doc")))
)
},
Sum(Var("weights"))
)
{
data: [318]
}
Grouping results
How many robots of each type are there?
To be able to answer that question, we first need to find out which robot types there are in our collection. To avoid reading all of the documents, we create an index that returns all of the types:
> CreateIndex({
name: "Robots_types",
source: Collection("Robots"),
values: [
{field: ["data", "type"]}
]
})
This is what this index returns:
> Paginate(Match(Index("Robots_types")))
{
data: ["ANDROID", "ANDROID", "ASTROMECH", "ASTROMECH", "HUMANOID"]
}
We can now use Distinct() to get only the unique types:
> Distinct(Paginate(Match(Index("Robots_types"))))
{
data: ["ANDROID", "ASTROMECH", "HUMANOID"]
}
Great. Now we need to find a way to be able to count how many robots there are for each of those types.
One way to do that could be using another index that filters robots per type:
> CreateIndex({
name: "Robots_by_type",
source: Collection("Robots"),
terms: [
{field: ["data", "type"]}
]
})
If we now combine everything into a single query, we get this:
> Let(
{
types: Distinct(Paginate(Match(Index("Robots_types"))))
},
Map(
Var("types"),
Lambda(
"type",
Let(
{
refs: Match(Index("Robots_by_type"), Var("type"))
},
{
type: Var("type"),
total: Count(Var("refs"))
}
)
)
)
)
{
data: [
{ type: 'ANDROID', total: 2 },
{ type: 'ASTROMECH', total: 2 },
{ type: 'HUMANOID', total: 1 }
]
}
We got our answer and used four read operations, one for each index that we queried.
What is the average weight of each robot type?
To answer this question, we won't be able to get away by counting elements on an array. We'll need a new index to be able to get the weights for each robot type:
> CreateIndex({
name: "Robots_weights_by_type",
source: Collection("Robots"),
terms: [
{field: ["data", "type"]}
],
values: [
{field: ["data", "weightKg"]}
]
})
Which returns this:
> Paginate(Match(Index("Robots_weights_by_type"), "ASTROMECH"))
{
data: [10, 20]
}
We can now compose the query to answer our question:
> Let(
{
types: Distinct(Paginate(Match(Index("Robots_types"))))
},
Map(
Var("types"),
Lambda(
"type",
{
type: Var("type"),
averageWeight: Mean(
Match(Index("Robots_weights_by_type"), Var("type"))
)
}
)
)
)
{
data: [
{ type: 'ANDROID', averageWeight: 120 },
{ type: 'ASTROMECH', averageWeight: 15 },
{ type: 'HUMANOID', averageWeight: 48 }
]
}
In this query, we're returning an array of weights for each type using the Robots_weights_by_type index, and then using Mean() to calculate the average weight.
Just as before, we are only using 4 read operations (one for each index), which works for any number of documents in the collection.
Ultimate robots report
So let's combine everything that we've learned so far to create the ultimate robots report:
> Let(
{
types: Paginate(Match(Index("Robots_types"))),
uniqueTypes: Distinct(Select(["data"], Var("types"))),
weights: Paginate(Match(Index("Robots_weights"))),
},
{
totalRobots: Count(Select(["data"], Var("types"))),
totalWeight: Sum(Select(["data"], Var("weights"))),
types: Map(
Var("uniqueTypes"),
Lambda(
"type",
Let(
{
typeWeights: Paginate(
Match(Index("Robots_weights_by_type"), Var("type"))
),
},
{
type: Var("type"),
total: Count(Select(["data"], Var("typeWeights"))),
totalWeight: Sum(Select(["data"], Var("typeWeights"))),
averageWeight: Mean(Select(["data"], Var("typeWeights")))
}
)
)
)
}
)
{
totalRobots: 5,
totalWeight: 318,
types: [
{ type: 'ANDROID', total: 2, totalWeight: 240, averageWeight: 120 },
{ type: 'ASTROMECH', total: 2, totalWeight: 30, averageWeight: 15 },
{ type: 'HUMANOID', total: 1, totalWeight: 48, averageWeight: 48 }
]
}
Conclusion
So that's it for today. Hopefully you learned something valuable!
In the following article we will do a deep dive into advanced index queries.
If you have any questions don't hesitate to hit me up on Twitter: @pierb




Top comments (0)