
We’re building more and more complex platforms, at the same time that we are trying to address ever-changing business requirements, and delivering them on time to an increasingly large number of users.
What we deliver is inherently unique. A combination of different services, technologies, features, and teams with their own contexts and competing priorities.
Sometimes it just feels like you’re designing and building an aircraft carrier, while navigating in rough ocean, occupied, and under attack.
Eduardo Romero@foxteck"Writing software is like designing and building a new type of aircraft carrier while it is in rough ocean, occupied, and under attack."21:14 PM - 26 Apr 20170
1




Continuously delivering quality software fast is a core business advantage for our clients. Accelerating the development process with modern architectures, frameworks, and practices is strategic.
The serverless paradigm it’s great at enabling fast, continuous software delivery. You don’t have to think about managing infrastructure, provisioning or planning for demand and scale.
And with the Function as a Service model we structure our code in smaller, simpler units, that are easy to understand, change and deploy to production. Allowing us to deliver business value and iterate quickly.
Serverless is a great enabler for experimenting, learning, and out-experimenting your competition.
Architectural Patterns are powerful way to promote best practices, robust solutions, and a shared architectural vision across our engineering organization.
Working on different projects leveraging serverless, I’ve seen patterns that we can adopt to solve common problems found in modern cloud architectures. While this is not an exhaustive collection, but it can be used as a catalog of architectural level building blocks for the next platform we build.
Serverless Architectural Patterns Catalog
- Simple Web Service.
- Decoupled Messaging.
- Robust API.
- Aggregator.
- Pub/Sub.
- Strangler.
- Queue-based Load Leveling.
- Read-heavy reporting engine.
- Streams and Pipelines.
- Fan-in and Fan-out.
Simple Web Service
“A client needs to consume a service via a Public or Internal API.”
A simple web service is the most standard use-case for AWS Lambda as a backend service. It represents the logic or domain layer of a n-tiered or layered architecture.

For Public APIs, API Gateway is exposing lambda functions via HTTPs. API Gateway can handle authorization, authentication, routing, and versioning.
For internal APIs, clients invoke lambda functions directly from within the client app using AWS’ SDK.
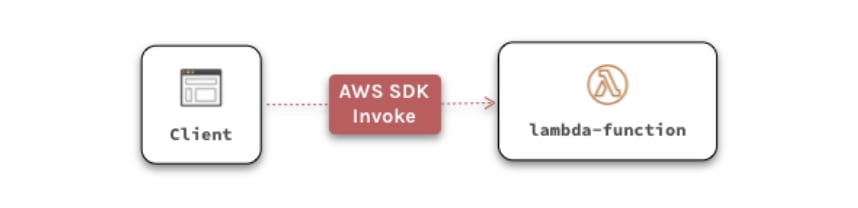
AWS Lambda scales automatically, and can handle fluctuating loads. Execution time is limited to the maximum allowed by API Gateway (29 seconds), or the hard limit of 15 minutes if invoked with the SDK.
It’s highly recommended that functions are stateless, sessions are cached and connections to downstream services are handled appropriately.
Decoupled Messaging
“As break out the monolith or continue to build services for our platform, different services have to interact. We want to avoid bottlenecks, synchronous I/O, and shared state.”
Asynchronous messaging is the foundation for most service integrations. It’s proven to be the best strategy for enterprise architectures. It allows building loosely-coupled architectures that overcome the limits of remote service communication, like latency and unreliability.
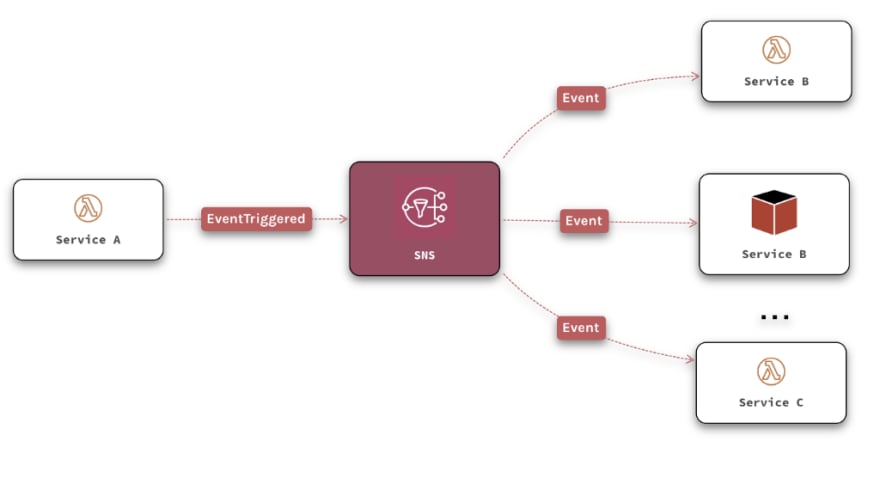
In the example above Service A is triggering events and SNS distributes these events to other services. When new services are deployed they can subscribe to the channel, and start getting messages as events happen.
Messaging infrastructure is reliable. Offering better encapsulation than a shared database. Perfect for asynchronous, event-based communication.
Different technologies have different constraints and offer specific guarantees. It’s important to be aware of these trade-offs. The most common services for messaging on AWS are SNS, SQS and Kinesis.
Considerations : Besides the known limitation and guarantees of each messaging service there should be conscious considerations for message duplication, message ordering, poisonous messages, sharding, and data retention. Microsoft’s “Asynchronous Messaging Primer” article discuses these topics in detail.
Robust API
“As the number of services of a platform grows clients need to interact with more and more services. Because each service might have different endpoints, belong to different teams, and have different release cycles, having the client manage these connections can be challenging.”
In a this pattern we have a single point of entry that exposes a well defined API, and routes requests to downstream services based on endpoints, routes, methods, and client features.

The downstream services could be lambda functions, external third-party APIs, Fargate containers, full-blown microservices, even internal APIs.
API Gateway, App Load Balancer or AppSync can be leveraged to implement it as the routing engine.

Having an abstraction layer between clients and downstream services facilitates incremental updates, rolling releases, and parallel versioning. Downstream services can be owned by different teams, decoupling release cycles, reducing the need for cross-team coordination, and improving API lifecycle and evolvability.
This pattern is also known as the API Gateway or Gateway Router.
Considerations : The Gateway can be a single point of failure. Managing resources and updating the client-facing interface can be tricky. It could become a cross-team bottleneck if it’s not managed via code automation.
Aggregator
“A client might need to make multiple calls to various backend services to perform a single operation. This chattines impacts performance and scale.”
Microservices have made communication overhead a common problem. Applications need to communicate with many smaller services, having a higher amount of cross-service calls.
A service centralizes client requests to reduce the impact of communication overhead. It decomposes and makes the requests to downstream services, collects and stores responses as they arrive, aggregates them, and returns it to the caller as one response.

Microsoft calls this pattern Gateway Aggregation. It can be implemented as a service with some business logic, that is able to cache responses and knows what to do when downstream services fail.
Considerations : Calls to the API should work as one operation. The API of the aggregator should not expose details of the services behind it to the client. The aggregator can be a single point of failure, and if it’s not close enough other services it can cause performance issues. The aggregator is responsible for handling retries, circuit breaking, cache, tracing, and logging.
Pub/Sub
“Services rarely live in isolation. The platform grows and services proliferate. We need services to interact without creating interdependency.
Asynchronous messaging enables services to announce events to multiple interested consumers without coupling.”
In Publisher-Subscriber services publish events through a channel as messages. Multiple interested consumers listen to the events by subscribing to these channels.
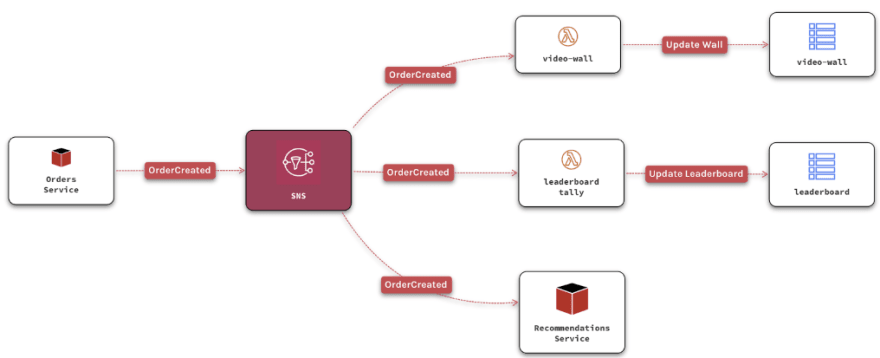
In the example the Orders service will publish an event when an order is created in the mobile application.
The VideoWall service is listening to OrderCreated events. It will take the order, break apart the items in the order — what needs preparation like a v60, or does not like cookies, and update the screen so our Baristas see which coffee to start brewing next.
The Leaderboard service will receive the same event, and will update the tally — Who is the Coffee Afficionado of the month, and what are the Top Selling Coffee Origins, Methods and Goodies.
The Recommendations service will keep track of who is drinking what, things that seem to go great together, and which is the next method you should try. — Hint, try the Japanese Syphon:
https://medium.com/media/c5ae351f5c6bbf46de15cc3c5fa8f498/href
Services are decoupled. They work together by observing and reacting to the environment, and each other — like rappers freestyling.
When new services and features are available they can subscribe, get events, and evolve independently.
Teams can focus on delivering value improving their core capabilities, without having to be focus on the complexity of the platform as a whole.
Considerations: Publisher / Subscriber is a great match for event-driven architectures. With lots of different options for messaging: SNS, Kinesis, Azure’s Service Bus, Google’s Cloud Pub/Sub, Kafka, Pulsar, etc. These messaging services will take care of the infrastructure part of pub/sub, but given the asynchronous nature of messaging all the issues discussed previously — message ordering, duplication, expiration, idempotency, and eventual consistency, should be considered in the implementation.
Strangler
“Systems grow and evolve over time. As complexity increases adding new features can be challenging. Completely replacing a system can take time, and starting from scratch is almost universally a bad idea.
Migrating gradually to a new system, while keeping the old system to handle the features that haven’t been implemented is a better path.
But clients need to know about both systems, and update every time a feature has been migrated.”
The Strangler pattern is a technique to gradually migrate legacy systems that was popularized with the exponential popularity of microservices. In this pattern a service acts as a façade that intercepts requests from the clients, and routes them to either the legacy service or new services.
Clients continue to use the same interface, unaware of the migration minimizing the possible impact — and the risk of the migration.

An Application Load Balancer routes clients’ requests to the Orders Service, the first microservice the team implemented. Everything else continues to go to the Legacy application.
Orders has its own data store, and implements all the business logic for Orders. Because some of the features on the legacy app use orders, we need to push the data back to the legacy app to stay in sync (an Anti-corruption Layer of sorts).
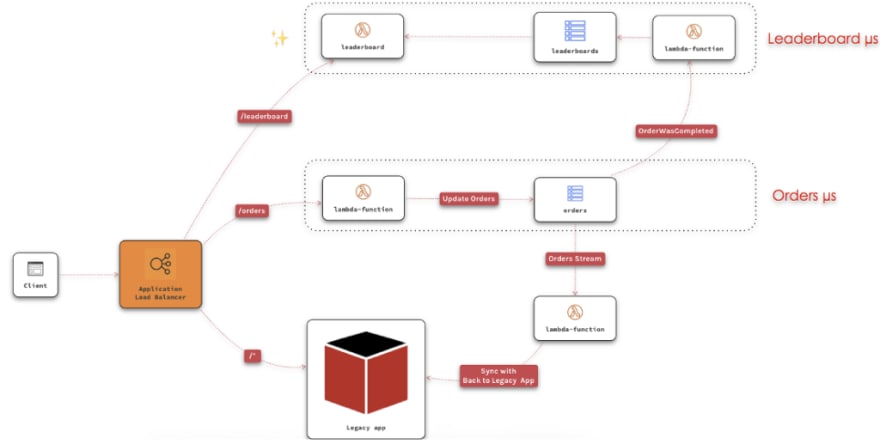
As the project evolves, new features come in and we create new services.
The Leaderboard Service is now available. It’s a completely new feature that the brand new Engagement Team created so there’s no need to interact with the Legacy app.
Teams will continue to create new features and port existing features to new services. When all the required functionality has been phased out of the legacy monolithic app it can be decommissioned.
Considerations: The façade keeps evolving side by side with the new services. Some data stores can potentially be used by both new and legacy services. New services should be structured in a way that they can be intercepted easily. At some point the migration should be complete, and the strangler façade should either go away, or evolve into a gateway or an adaptor.
Queue-based Load Leveling
“Load can be unpredictable, some services cannot scale when there’s an intermittent heavy load. Peaks in demand can cause overload, flooding downstream services causing them to fail.
Introducing a queue between the services that acts as a buffer can alleviate the issues. Storing messages and allowing consumers to process the load at their own pace.”
Buffering services with the help of a queue is very common. In Microsoft’s Cloud Architecture Patterns it’s called the queue-based load leveling pattern, Yan Cui calls it Decoupled Invocation, and Jeremy Daly calls it the Scalable Webhook.
A queue decouples tasks from services, creating a buffer that holds requests for less scalable backends or third-party services.
Regardless of the volume of requests the processing load is driven by the consumers. Low concurrency and batch size can control the workload.

In the example we have a Migration worker process that reads the content of an Elasticsearch index. Elasticsearch it’s fast. The worker can read thousands of Articles and fetch their dependencies (Authors, Categories, Tags, Shows, Assets, etc.) in less than a second.
On the right side we have a service that needs to ingest all the content, but before we can create an Article we have to create all its relationships in a specific order, double-checking if they exist, and need to be updated which is slower. Even if we scale horizontally the service — and we did — the relational database behind it becomes the bottle neck.
After a point (~100k to 500k Articles) querying the database slows down to a crawl because there’s some locking on the Has-and-Belongs-to-Many relationship tables.
By limiting the batch size and the number of workers running concurrently we can maintain a slow but steady flow that reduces lock contention in the database.
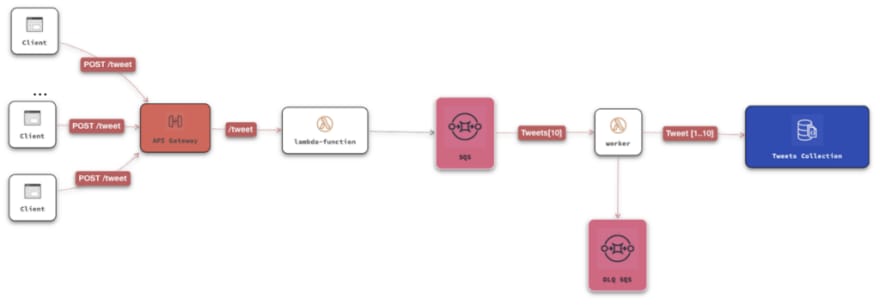
Another common example is using a SQS to buffer API requests to amortize spikes in traffic— like in the diagram above.
The endpoint returns 202 — Accepted to the client, with a transaction id and a location for the result. On the client-side the UI can give feedback to the user emulating the expected behavior.
The service can process the requests on the background at its own peace. Even if there are long running process involved an increase in the load on the client-side will never affect the throughput and responsiveness of the system.
Considerations: This pattern is not helpful when services require a synchronous response (waiting for a reply). It’s important to note that not using concurrency limits can diminish the effectiveness of the pattern: AWS Lambda and Kinesis can scale quickly, overwhelming downstream services that are less elastic or slower to scale. Zalando’s API Guidelines includes a full section about Events that talks about this some important considerations for this pattern.
Read-heavy reporting engine
“It’s very common with read-heavy applications to hit the limits of downstream data engines that are not specialized for the different querying patterns that clients use.
Caching data and creating specialized views of the most queried data can help mitigate the load impact of a read-heavy service.”
Previous patterns help address pushing data and events from one service to others, optimizing scale for write-heavy services. This pattern optimizes the data for different accessing and querying patterns that clients need, optimizing scale for read-heavy services.
Most applications are read-intensive. This is particularly true for our Big Media clients where there are far less users generating content than users consuming the content. The ratio between them can be huge like 1:100000.
Caching data and creating specialized views of the most frequent access patterns help services scale effectively.
Caching means temporarily copying frequently used into memory or a shared repository. Caching data is one of the most frequently used strategies to improve performance and scale reads.
In Materialized views the data is replicated and transformed in a way that is optimized for querying and displaying. Materialized views can be new tables or completely different data stores where the data is mapped to be displayed in a new format or limited to a specific subset of the data.
Materialized views are also useful to “bridge” different stores to take advantage of their stronger capabilities.
With Index Tables the data is replicated in a new table using specialized indexes specific to common queries. Specialized indexes can be composite keys, secondary keys, and partially denormalized that.

Dynamo streams and lambda functions are the perfect tools to create specialized views. In the example we have three endpoints — search, tweet and timeline. Each one needs a slightly different querying pattern where the data needs to be optimized in a particular way.
/search queries the Tweets Index in Elasticsearch. Providing things like phonetic search, typos, related terms, and suggestions. There is no need to index all the data from the original tweet, maybe it only includes the text, location, media url — for a pretty preview, and hashtags. We use the stream to trigger a lambda on TweetCreated that strips all the data we don’t need and indexes the tweet.
/timeline is created from the most interesting tweets on the network, and the activity of my connections.
We use a Dynamo table to keep the Top Tweets — an indexed table limited to the 1000 most viewed items. Tweets are updated via the stream on theTweetViewed event. A lambda function receives the event, queries the Tweets Collection, and saves the result.
Getting the activity of someone’s connection is easier on a Graph Database like Neptune. Another lambda triggered by the TweetCreated event creates a record on Neptune maintaining activities for our connection’s streams of tweets.
In Microsoft’s Cloud Architecture this is a mix of different patterns — Data pipeline, Cache-aside, Materialized views, and Index Table.
Considerations: Handling cache can be hard, remember to follow industry best practices. Maintaining materialized views, and index tables can be complicated. Duplicating the data will add cost, effort, and logic. With very large datasets it can be very difficult to maintain consistency, and keeping the data in sync could slow down the system. Views and Index tables are not fully consistent.
Streams and Pipelines
“A continuous stream processor that captures large volumes of events or data, and distributes them to different services or data stores as fast as they come.”
An important feature we see often is processing streams of data, as fast as the data is being generated and scaling quickly to meet demand of large volumes of events. Downstream services receive the stream and apply business logic to transform, analyze or distribute the data.
Common examples are capturing user-behavior like clickstreams and UI interactions. Data for analytics. Data from IoT sensors, etc.

In the example a Kinesis Stream receives events from Service A. The data is transformed with lambda functions, stored in DynamoDB for fast reading, and indexed in Elasticsearch for a good search user-experience.
Kinesis Analytics provides fast querying data in the stream in real time. With the S3 integration all the data is stored for future analysis and real insight. Athena provides querying for all the historical data.
Considerations: Stream processing can be expensive, it might not be worth it if there dataset is small or there are only a few events. All cloud providers have offerings for Data pipelines, Stream processing, and Analytics but they might not integrate well with services that are not part of their ecosystem.
Fan-out and Fan-in
“Large jobs or tasks can easily exceed the execution time limit on Lambda functions. Using a divide-and-conquer strategy can help mitigate the issue.
The work is split between different lambda workers. Each worker will process the job asynchronously and save its subset of the result in a common repository.
The final result can be gathered and stitched together by another process or it can be queried from the repository itself.”
Fan-out and Fan-in refers to breaking a task in subtasks, executing multiple functions concurrently, and then aggregating the result.
They’re two patterns that are used together. The Fan-out pattern messages are delivered to workers, each receiving a partitioned subtask of the original tasks. The Fan-in pattern collects the result of all individual workers, aggregating it, storing it, and sending an event signaling the work is done.

Resizing images is one of the most common examples on using serverless. This is the fan-out approach.
A client uploads a raw image to the Assets S3 Bucket. API Gateway has an integration to handle uploading directly to S3.
A lambda function is triggered by S3. Having one lambda function to do all the work can lead to limit issues. Instead, the lambda pushes an Asset Created event to SNS so our processing lambdas get to work.
There are three lambda functions for resizing — on the right. Each creates a different image size, writing the result on the Renditions bucket.
The lambda on the bottom reads the metadata from the original source — location, author, date, camera, size, etc. and adds the new asset to the DAM’s Assets Table on DynamoDB, but doesn’t mark it as ready for use. Smart auto-tagging, text extraction and content moderation could be added to processing lambdas with Rekognition later.
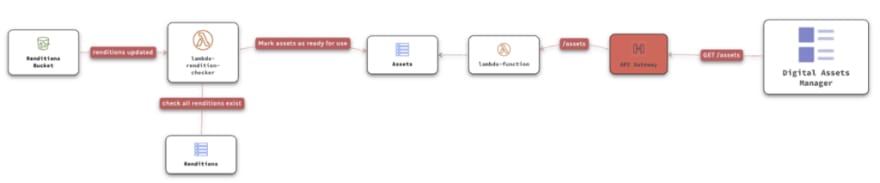
For the Fan-in part of the DAM, we have a lambda function that’s listening to the renditions bucket, when there’s a change on the bucket it checks if all renditions are ready, and marks the assets ready for use.
With the event-driven nature of serverless, and given the resource limits of lambda functions we favor this type of choreography over orchestration.
Considerations : Not all workloads can be split in small enough pieces for lambda functions. Failure should be considered on both flows, otherwise a task might stay unfinished forever. Leverage lambda’s retry strategies and Dead-Letter Queues. Any task that can take over 15 minutes should use containers instead of lambda functions, sticking to the choreography approach.
More resources 📚
- Microsoft’s Azure Architecture Center has an extensive list of Cloud Patterns, a solid guide for best practices, a very good overview of performance anti-patterns and some examples.
- AWS also has great resources on Distributed Systems Components, Serverless in general, examples in the Serverless Application Repository, and several webinar videos.
- Jeremy Daly has an extensive list of Serverless Patterns. He’s the author of Lambda API a lightweight API framework, and the Serverless MySQL module for managing connections on your lambda functions.
- Yan Cui has a tonne of content about serverless. Including Design patterns, performance, lots of points of view, and the best training on serverless. He’s must-follow on the serverless scene.
- Mike Roberts writes and talks about serverless in depth.
- Sascha ☁ Möllering talks about Serverless Architectural Patterns and Best Practices.
- Rob Gruhl’s Event-sourcing at Nordstrom, the post about Hello Retail!, and the video about their architecture.
- swardley and Forrest Brazeal discussion about Containers vs Serverless.
- Gregor Hohpe’s Enterprise Integration Patterns is a catalog of 65 technology-independent patterns, some of which he’s ported serverless in Google’s cloud.
- Twitch’s Design Patterns for Twitch Scale touches on several interesting points about patterns that can apply for scale.
- Capital One Tech “When to React vs. Orchestrate” is an excellent post about choreography vs orchestration.

Top comments (0)