Data Modelling
Basically Before understanding the wide columnar stores, we have to first look at the way that how cassandra stores the data.
So if you are coming from RDBMS background. Then please hold your horses and i request you to forget everything about it.
Let's get to bottom up approach of understanding the Data modelling in Cassandra.
So if you have to store the information say information of user, then in that case you will have an array of String in which you have to store the data.
eg.
String[] information = new String[3];
["Gaurav","25","Post Graduation"]
but as you can see that storing information in such a way is waste. Since first you have to maintain a record of what information[0] represents and so on.
and next time you have to insert the data in the same approach.
Here comes your saviour called MAPS.
So we will assign each values with names, and then we will fetch the values by name so now ordering is not so important. Let's see how?
Going with same above example:
Map<String, String> information = new HashMap<>();
information.put("name","gaurav");
information.put("age","25");
information.put("education","Post graduation");
NAME AGE Education
| | |
gaurav 25 PG
So now what do you think?
Is it looking ok?
Let's say i now need to store other information of user, then?
It means there is no way of unify some collection of name/value pairs.
and no way to repeat the same column name.
Because if you again do
information.put("names","joshua");
then the previous name will be lost.
So we need something that will group some of the column
values together in a distinctly addressable group.
We need a key to refer this group of columns.
We need rows.
Then if we get single row then we can get the entire column family.
So now what we need is something like this.
Map<Row(Primary Key), ColumnarClass> cassandraDataModelling = new HashMap<>();
class ColumnarClass<T>{
Dynamic column names;
TimeStamp; (necessary field)
}
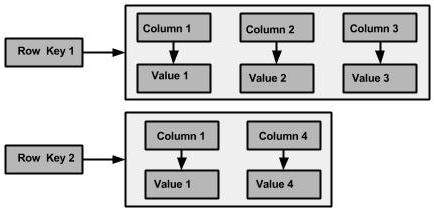
and now the image of above data structure is:
Cassandra defines a column family to be a logical division that associates similar data.
For example, we might have a User column family, a Hotel column family, an
AddressBook column family, and so on. In this way, a column family is somewhat
analogous to a table in the relational world.
To make it more easy and visually appealing.
User: ColumnFamily 1
Josh: RowKey
email: josh@ssd.com, ColumnName:Value
age: 22 ColumnName:Value
Gaurav: RowKey
email: gaurav@mailcom ColumnName:Value
Vehicle: ColumnFamily 2
Bike: RowKey
Period: 1968-2010 ColumnName:Value
Similarly you can have a super columnar family, which is nothing but a maps of map i.e
Map<RowKey, Map<RowKey, ColumnarClass>> = new HashMap<>();
Where a row in a column family holds a collection of name/value pairs, the super
column family holds subcolumns, where subcolumns are named groups of columns.
So the address of a value in a regular column family is a row key pointing to a column
name pointing to a value, while the address of a value in a column family of type
“super” is a row key pointing to a column name pointing to a subcolumn name
pointing to a value. Put slightly differently, a row in a super column family still contains
columns, each of which then contains subcolumns.
(This text Source came from Cassandra The definitive guide.)
So that’s the bottom-up approach to looking at Cassandra’s data model.
There is many more to this. But again you have to hold your horses and stay tuned for next Awesome Cassandra article.
If you have any suggestions or something that you feel is wrong. Feel free to drop your comments.
Thank you

{kind=link}
{kind=link}
Top comments (0)