ACID Properties:
Introduction to ACID Properties in DBMS
ACID Properties in DBMS ensure consistency and reliability in transactions. For example, when two users try to book the same train ticket, the user who clicks the 'Book Now' button first is given preference. Without ACID Properties, both users could end up with a confirmed ticket, causing problems. ACID Properties prevent errors and maintain consistency, which is crucial when multiple users are trying to book/purchase the same thing
What are ACID Properties in DBMS?
ACID properties are a set of properties that guarantee reliable processing of transactions in a database management system (DBMS). Transactions are a sequence of database operations that are executed as a single unit of work, and the ACID properties ensure that transactions are processed reliably and consistently in a DBMS.
The Atomicity property ensures that a transaction is either executed completely or not at all. The Consistency property ensures that the database remains in a consistent state before and after a transaction. The Isolation property ensures that multiple transactions can run concurrently without interfering with each other. The Durability property ensures that the results of a committed transaction are permanent and cannot be lost due to system failure.
Together, these properties ensure that transactions are processed reliably and consistently in a DBMS, which is essential for the integrity and accuracy of data in a database.
1. Atomicity in DBMS
The term atomicity is the ACID Property in DBMS that refers to the fact that the data is kept atomic. It means that if any operation on the data is conducted, it should either be executed completely or not at all. It also implies that the operation should not be interrupted or just half completed. When performing operations on a transaction, the operation should be completed totally rather than partially. If any of the operations aren’t completed fully, the transaction gets aborted.
Sometimes, a current operation will be running and then, an operation with a higher priority enters. This discontinues the current operation and the current operation will be aborted.
In the example above, if we consider the case that both users get notified that the seat is booked and neither of them is allowed to be seated because only one seat is available on the train, that is a half-fulfilled transaction. The transaction would be complete if they were able to be seated as well. Instead, according to atomicity, the person who clicks the button first books the seat and gets the notification of having purchased a ticket, and the seats left are updated. The second person’s transaction is rolled back and they are notified that no more seats are available. Let us consider an easier example where one person is trying to book a ticket. They were able to select their seat and reach the payment gateway. But, due to bank server issues, the payment could not go through. Does this mean that their booked seat will be reserved for them?
No. This is because one full transaction means reserving your seat and paying for it as well. If any of the steps fail, the operation will be aborted and you will be brought back to the initial state.
Atomicity in DBMS is often referred to as the ‘all or nothing’ rule.
2. Consistency in DBMS
This ACID Property will verify the total sum of seats left in the train+sum of seats booked by users=total the number of seats present in the train. After each transaction, consistency is checked to ensure nothing has gone wrong.
Let us consider an example where one person is trying to book a ticket. They are able to reserve their seat but their payment hasn’t gone through due to bank issues. In this case, their transaction is rolled back. But just doing that isn’t sufficient. The number of available seats must also be updated. Otherwise, if it isn’t updated, there will be an inconsistency where the seat given up by the person is not accounted for. Hence, the total sum of seats left in the train + the sum of seats booked by users would not be equal to the total number of seats present in the train if not for consistency.
3. Isolation in DBMS
Isolation is defined as a state of separation. Isolation is an ACID Property in DBMS where no data from one database should impact the other and where many transactions can take place at the same time. In other words, when the operation on the first state of the database is finished, the process on the second state of the database should begin. It indicates that if two actions are conducted on two different databases, the value of one database may not be affected by the value of the other. When two or more transactions occur at the same time in the case of transactions, consistency should be maintained. Any modifications made in one transaction will not be visible to other transactions until the change is committed to the memory.
Let us use our example of 2 people trying to book the same seat to understand this ACID Property. Two transactions are happening at the same item on the same database, but in isolation. To ensure that one transaction doesn’t affect the other, they are serialized by the system. This is done so as to maintain the data in a consistent state. Let us consider that the two people that click ‘Book Now’, do so with a gap of a few seconds. In that case, the first person’s transaction goes through and he/she receives their ticket as well. The second person will not know of the same until the first person’s transaction is committed to memory. When the second person clicks on ‘Book Now’ and is redirected to the payment gateway, since the first person’s seat has already been booked, it will show an error notifying the user that no seats are left on the train.
4. Durability in DBMS
The ACID Property durability in DBMS refers to the fact that if an operation is completed successfully, the database remains permanent in the disk. The database’s durability should be such that even if the system fails or crashes, the database will survive. However, if the database is lost, the recovery manager is responsible for guaranteeing the database’s long-term viability. Every time we make a change, we must use the COMMIT command to commit the values.
Imagine a system failure or crash occurs in the railway management system and all the trains that everyone had booked have been removed from the system. That means millions of users would have paid the money for their seats but will not be able to board the train as all the details have been destroyed. This could lead to huge losses for the company as users would lose trust in them. In addition, it would create a lot of panics as these trains would be needed for important reasons as well.
CAP Theorem:
CAP Theorem is very imorantant while working with distributed environment.
Distributed enviroment:
a collection of independent components located on different machines that share messages with each other in order to achieve common goals.
The CAP theorem, originally introduced as the CAP principle, can be used to explain some of the competing requirements in a distributed system with replication. It is a tool used to make system designers aware of the trade-offs while designing networked shared-data systems.
The three letters in CAP refer to three desirable properties of distributed systems with replicated data: consistency (among replicated copies), availability (of the system for read and write operations) and partition tolerance (in the face of the nodes in the system being partitioned by a network fault).
The CAP theorem states that it is not possible to guarantee all three of the desirable properties – consistency, availability, and partition tolerance at the same time in a distributed system with data replication.
Consistency –
Consistency means that the nodes will have the same copies of a replicated data item visible for various transactions. A guarantee that every node in a distributed cluster returns the same, most recent and a successful write. Consistency refers to every client having the same view of the data. There are various types of consistency models. Consistency in CAP refers to sequential consistency, a very strong form of consistency.Availability –
Availability means that each read or write request for a data item will either be processed successfully or will receive a message that the operation cannot be completed. Every non-failing node returns a response for all the read and write requests in a reasonable amount of time. The key word here is “every”. In simple terms, every node (on either side of a network partition) must be able to respond in a reasonable amount of time.Partition Tolerance –
Partition tolerance means that the system can continue operating even if the network connecting the nodes has a fault that results in two or more partitions, where the nodes in each partition can only communicate among each other. That means, the system continues to function and upholds its consistency guarantees in spite of network partitions. Network partitions are a fact of life. Distributed systems guaranteeing partition tolerance can gracefully recover from partitions once the partition heals.
JOINS :
What are JOINS in SQL?
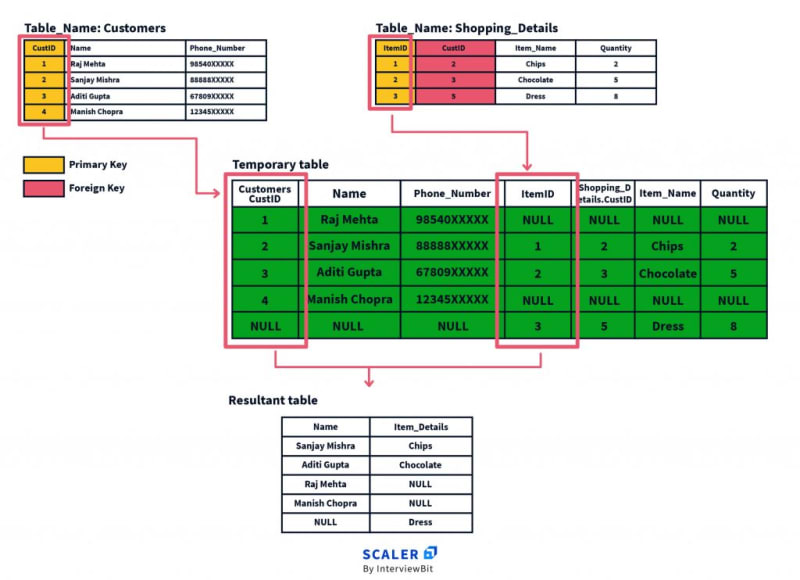
SQL Joins are mostly used when a user is trying to extricate data from multiple tables (which have one-to-many or many-to-many relationships with each other) at one time. The join keyword merges two or more tables and creates a temporary image of the merged table. Then according to the conditions provided, it extracts the required data from the image table, and once data is fetched, the temporary image of the merged tables is dumped.
Types of JOINS in SQL
INNER JOIN in SQL
SQL Inner Join or Equi Join is the simplest join where all rows from the intended tables are cached together if they meet the stated condition. Two or more tables are required for this join. Inner Join can be used with various SQL conditional statements like WHERE, GROUP BY, ORDER BY, etc.

General Syntax
SELECT column-name
FROM table-1 INNER JOIN table-2
WHERE table-1.column-name = table-2.column-name;
We can alternately use just the “JOIN” keyword instead of “INNER JOIN”.
Example
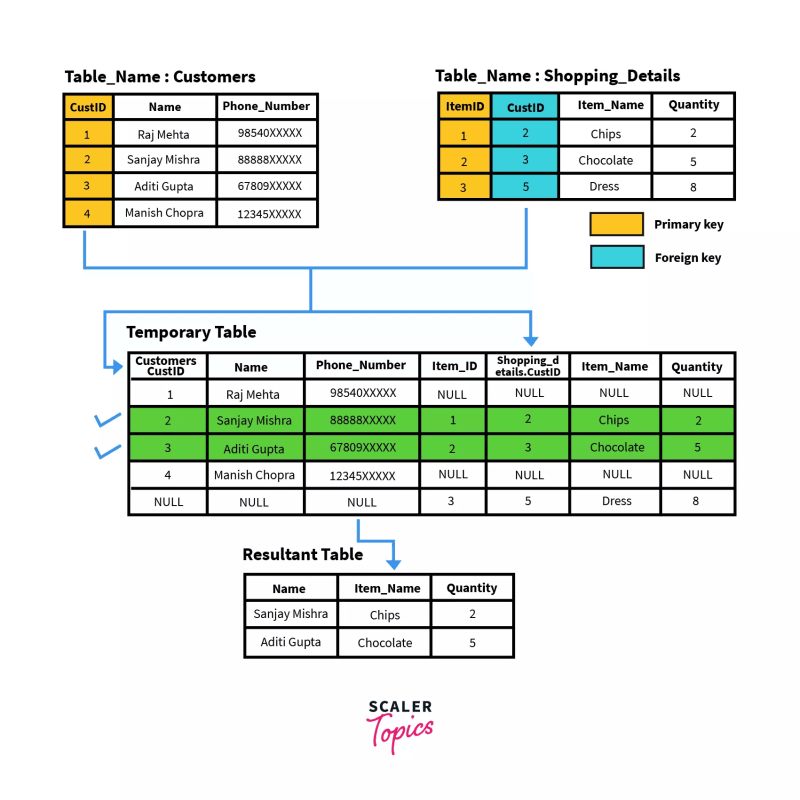
Special Case of INNER JOIN: NATURAL JOIN
SQL Natural Join is a type of Inner join based on the condition that columns having the same name and datatype are present in both the tables to be joined.
General Syntax
SELECT * FROM
table-1 NATURAL JOIN table-2;
OUTER JOINS in SQL
SQL Outer joins give both matched and unmatched rows of data depending on the type of outer joins. These types are outer joins are sub-divided into the following types:
- Left Outer Join
- Right Outer Join
- Full Outer Join
1. LEFT OUTER JOIN
In this join, a.k.a. SQL Left Join, all the rows of the left-hand table, regardless of following the stated conditions are added to the output table. At the same time, only matching rows of the right-hand table are added.
Rows belonging to the left-hand table and not having values from the right-hand table are presented as NULL values in the resulting table.

General Syntax
SELECT column-name(s)
FROM table1 LEFT OUTER JOIN table2
ON table1.column-name = table2.column-name;

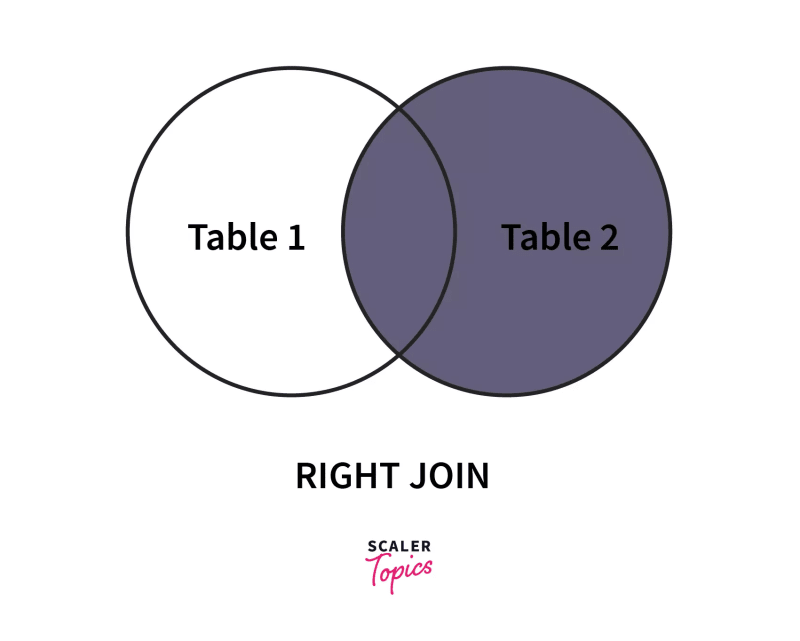
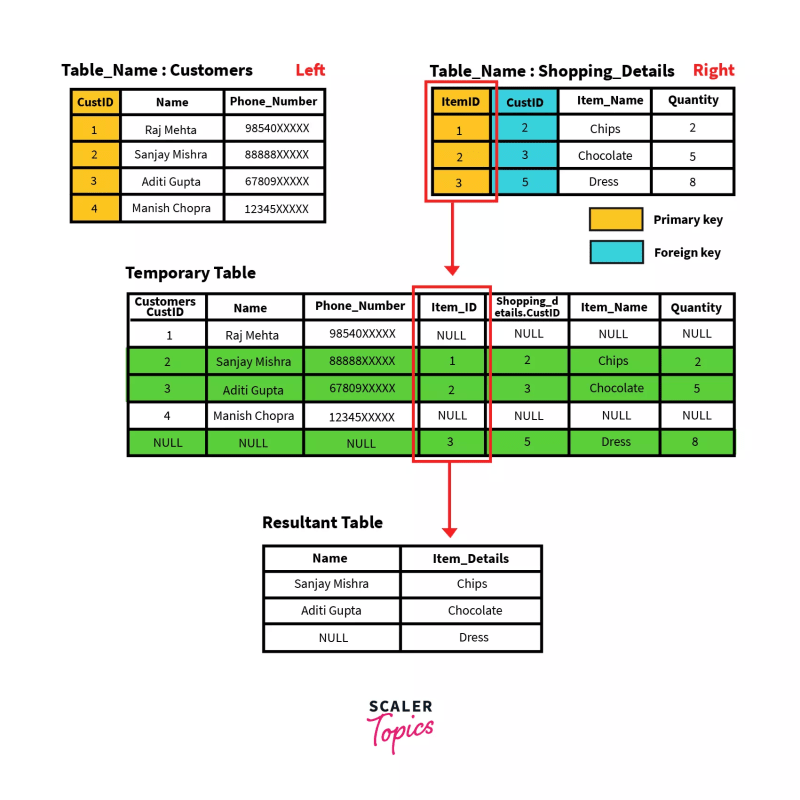
2. RIGHT OUTER JOIN
Similar to the left outer join, in the case of the Right Outer Join, a.k.a. SQL Right Join, all the rows on the right-hand table, regardless of following the stated conditions, are added to the output table. At the same time, only matching rows of the left-hand table are added.
Rows belonging to the right-hand table and not having values from the left-hand table are presented as NULL values in the resulting table.
General Syntax
SELECT column-name(s)
FROM table1 RIGHT OUTER JOIN table2
ON table1.column-name = table2.column-name;
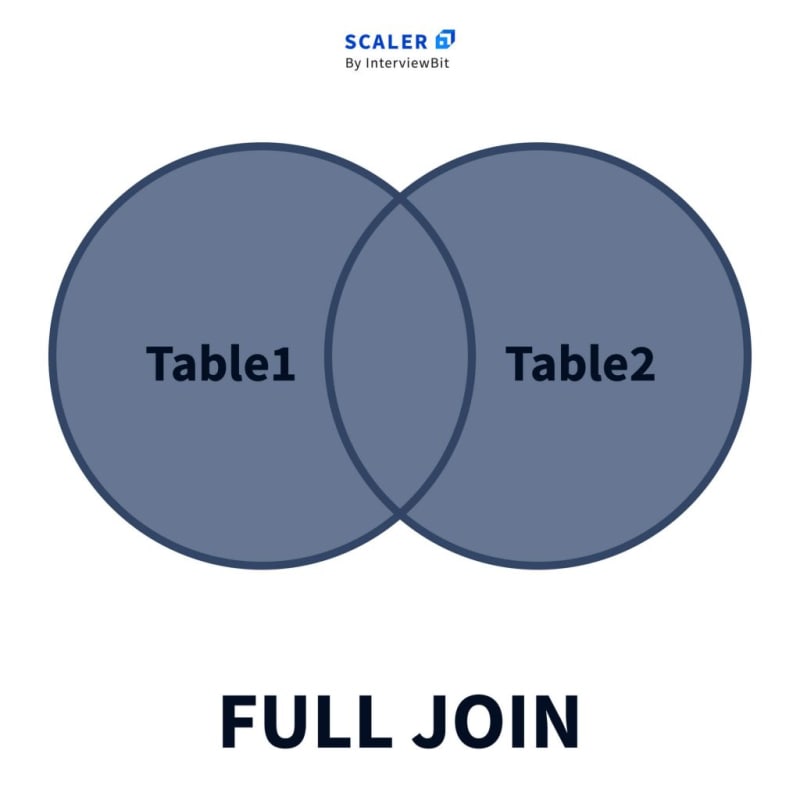
3. FULL OUTER JOIN
The full outer join (a.k.a. SQL Full Join) first adds all the rows matching the stated condition in the query and then adds the remaining unmatched rows from both tables. We need two or more tables for the join.
After the matched rows are added to the output table, the unmatched rows of the left-hand table are added with subsequent NULL values, and then unmatched rows of the right-hand table are added with subsequent NULL values.
General Syntax
SELECT column-name(s)
FROM table1 FULL OUTER JOIN table2
ON table1.column-name = table2.column-name;
- Aggregations, Filters in queries:
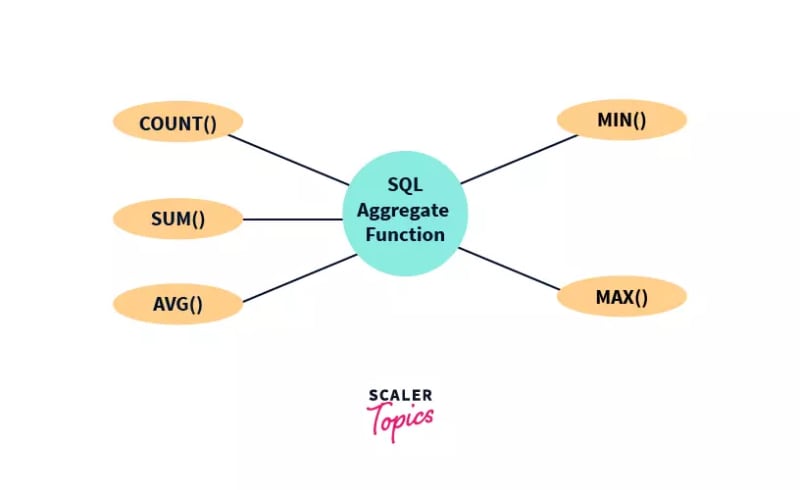
Aggregate functions in SQL are used to perform operations on multiple rows of a table and return a single value. A single function can be used to compute multiple values and return the required result.
Types of Aggregate Functions in SQL
Aggregate functions in SQL can be of the following types as shown in the figure. We will be understanding the working of these functions one by one.
1. COUNT() Function
The COUNT() aggregate function returns the total number of rows from a database table that matches the defined criteria in the SQL query.
Syntax:
COUNT(*) OR COUNT(COLUMN_NAME)
COUNT(*) returns the total number of rows in a given table. COUNT(COULUMN_NAME) returns the total number of non-null values present in the column which is passed as an argument in the function.
Let’s take a look at a few examples to understand the function better.
Example:
Suppose you want to know the total number of employees working in the organization. You can do so by the below-given query.
SELECT COUNT(*) FROM EMP_DATA;
As COUNT() returns the total number of rows and the table named EMP_DATA provided above consists of 10 rows, so the COUNT() function returns 10. The output is printed as shown below.
Output:
COUNT(*)
10
2. SUM() Function
The SUM() function takes the name of the column as an argument and returns the sum of all the non NULL values in that column. It works only on numeric fields(i.e the columns contain only numeric values). When applied to columns containing both non-numeric(ex - strings) and numeric values, only numeric values are considered. If no numeric values are present, the function returns 0.
Syntax:
The function name is SUM() and the name of the column to be considered is passed as an argument to the function.
SUM(COLUMN_NAME)
3.AVG() Function
The AVG() aggregate function uses the name of the column as an argument and returns the average of all the non NULL values in that column. It works only on numeric fields(i.e the columns contain only numeric values).
Note: When applied to columns containing both non-numeric (ex - strings) and numeric values, only numeric values are considered. If no numeric values are present, the function returns 0.
Syntax:
The function name is AVG() and the name of the column to be considered is passed as an argument to the function.
AVG(COLUMN_NAME)
4. MIN() Function
The MIN() function takes the name of the column as an argument and returns the minimum value present in the column. MIN() returns NULL when no row is selected.
Syntax:
The function name is MIN() and the name of the column to be considered is passed as an argument to the function.
MIN(COLUMN_NAME)
To understand this better, let’s take a look at some examples.
Example:
Suppose you want to find out what is the minimum salary that is provided by the organization. The MIN() function can be used here with the column name as an argument.
SELECT MIN(Salary) FROM EMP_DATA;
5. MAX() Function
The MAX() function takes the name of the column as an argument and returns the maximum value present in the column. MAX() returns NULL when no row is selected.
Syntax:
The function name is MAX() and the name of the column to be considered is passed as an argument to the function.
MAX(COLUMN_NAME)
FILTER CLAUSE
The filter clause is another tool for filtering in SQL. The filter clause is used to, as the name suggests, filter the input data to an aggregation function. They differ from the WHERE clause because they are more flexible than the WHERE clause. Only one WHERE clause can be used at a time in a query. While on the other hand, multiple FILTER clauses can be present in a single query.
Syntax
EXPRESSION
AGGREGATION FUNCTION 1
FILTER(WHERE CLAUSE)
AGGREGATION FUNCTION 2
FILTER(WHERE CLAUSE)
.
.
.
EXPRESSION
Example
SELECT COUNT(ID)
FILTER(WHERE ID!=2),
AVG(LENGTH(NAME))
FILTER(WHERE LENGTH(NAME)>4)
FROM TEST;
Input table:
MariaDB [db]> SELECT * FROM TEST;
+----+------------------+----------+
| ID | NAME | EMPLOYED |
+----+------------------+----------+
| 1 | Drake Maverick | 1 |
| 2 | Nancy Peloski | 0 |
| 3 | Anakin Skywalker | 0 |
| 4 | Uchiha Obito | 1 |
| 5 | Anakin Skywalker | 1 |
| 6 | Uchiha Obito | 1 |
+----+------------------+----------+
Output:
+-------+-----------------------+
| COUNT | AVG |
+-------+-----------------------+
|5 | 13.8333333333333333 |
+-------+-----------------------+
In the above query, the number of rows that have an ID other than two is five. We are also printing the average length of names of length greater than 4.
Noramalization:
What is Normalization in SQL?
Let’s begin with why normalization in SQL was introduced originally by discussing the problem it solves. As we know, we’ve relations (or tables) where we store our data, and if you remember one part of DBMS talks about management, we need to manage this data efficiently. Let’s see the wrong way first.
.
The Three Problems Or Would Say Anomalies Are:
Insertion Anomaly
Deletion Anomaly
Modification Anomaly
Insertion anomaly means cases where you can’t insert data unless you have another dependent piece of information. To see this from the above example, we can’t insert teacher’s data unless we have student data (assuming the key is student_id).
Deletion anomaly means cases where deleting a record can mistakenly delete other prominent information which is in reality independent in nature. In the above example, deleting a student record will also delete the corresponding teacher’s record and that’s not what we want. That’s because let’s say if a student leaves the school and we’ve to delete their data then doing it would also delete corresponding teacher’s data and that’s not what we want because it doesn’t mean the teacher also left the school.
Modification anomaly means cases when instead of updating a single piece of information at one place we’ve to update it at multiple places. For example, student 1 and student 3 have the same subject, and that’s why they are allotted the same teacher. If we ever want to change this teacher name (for some reason) we’ve to do it at 2 places. Assume if they’re duplicated at tons of places then we’ve to do it at every place to provide consistent data. and this you can guess is really difficult here.
So, that’s why normalization. So let’s see now what normalization really is and how it solves these anomalies.
Normalization and Solving Anomalies
Normalization in SQL is nothing but a technique that prevents above-mentioned anomalies, i.e., insertion, deletion, and modification anomalies to happen and reduces data redundancy. It has some set of rules through which it makes this happen. It divides a big table into smaller tables until it doesn’t follow a set of rules and this process is called normalization.
Note: Data redundancy is nothing but a form of data that is duplicated at multiple places inside the database.
Normal Form
Please note the last line from the above paragraph “It divides a big table into smaller tables until it doesn’t follow a set of rules ”. What are these rules? Actually, we divide the normalization process into a set of normal forms. A normal form is nothing but a form of a table that follows some norms (rules) that prevent the above anomalies to some extent. We have a list of normal forms,
- 1NF
- 2NF
- 3NF
- BCNF
- 4NF
- 5NF
- 6NF
Complexity to divide tables into a particular normal form increases as we go down. Also, as we go down, all tables should also follow all the normal forms mentioned above. Please read the above line once more. It’s important!
Also, in real-life databases that contain multiple tables, they all must be normalized and all the tables should follow the norms, not just one.
Indexes :
- An Index is a special lookup table, built from one or more columns in the database table that speeds up fetching rows from the table or view. There are two types of indexes, Clustered and Non-Clustered Indexes.
- A Clustered index is a type of index in which the data is physically sorted in a table. In the Database, there can be only one clustered index per table.
- A Non-Clustered Index is a type of index in which a separate key-value structure from the actual data table is created, in which the key contains the column values (on which a Non-Clustered Index is declared) and each value corresponding to that key contain a pointer to the data row that contains the actual value.
- There can be one or more Non-Clustered Indexes per table.
- In a Clustered Index, the index is the main data and in a non-clustered index, the index is the copy of the main data.
- Primary Keys of the table by default are the clustered index, to change the clustered index we have to remove the previous index, and then we can explicitly create a new clustered index.
- Indexes can be created or dropped with no effect on the actual data table.
Transactions:
Introduction
You might have encountered a situation when your system got crashed due to some hardware or software issues and got rebooted to ensure that all the data is restored in a consistent state. This protection of user's data even in case of a system failure marks as one of the major advantages of database management system. Various transactions are done as a part of manipulating the data in a database, these transactions can be seen as a set of operations that are executed by the user program in DBMS. Execution of a similar transaction multiple times will lead to the generation of multiple transactions. For example, Withdrawing some amount of money from the ATM can be seen as a transaction that can be done multiple times also.
Operations in Transaction
A certain set of operations takes place when a transaction is done that is used to perform some logical set of operations. For example: When we go to withdraw money from ATM, we encounter the following set of operations:
- Transaction Initiated
- You have to insert an ATM card
- Select your choice of language
- Select whether savings or current account
- Enter the amount to withdraw
- Entering your ATM pin
- Transaction processes
- You collect the cash
- You press finish to end transaction
The above mentioned are the set of operations done by you. But in the case of a transaction in DBMS there are three major operations that are used for a transaction to get executed in an efficient manner. These are:
1. Read/ Access Data 2. Write/ Change Data 3. Commit
Let's understand the above three sets of operations in a transaction with a real-life example of transferring money from Account1 to Account2.
Initial balance in both the banks before the start of the transaction
Account1 - ₹ 5000 Account2 - ₹ 2000
This data before the start of the transaction is stored in the secondary memory (Hard disk) which once initiated is bought to the primary memory (RAM) of the system for faster and better access.
Now for a transfer of ₹ 500 from Account1 to Account2 to occur, the following set of operations will take place.
Read (Account1) --> 5000 Account1 = Account1 - 500 Write (Account1) --> 4500 Read (Account2) --> 2000 Account2 = Account2 + 500 Write (Account2) --> 2500 commit
The COMMIT statement permanently saves the changes made by the current transaction. When a transaction is successful, COMMIT is applied. If the system fails before a COMMIT is applied, the transaction reaches its previous state after ROLLBACK.
After commit operation the transaction ends and updated values of Account1 = ₹ 4500 and Account2 = ₹ 2500. Every single operation that occurs before the commit is said to be in a partially committed state and is stored in the primary memory (RAM). After the transaction is committed, the updated data is accepted and updated in the secondary memory (Hard Disk).
If in some case, the transaction failed anywhere before committing, then that transaction gets aborted and have to start from the beginning as it can’t be continued from the previous state of failure. This is known as Roll Back. :::
Transaction States in DBMS
During the lifetime of a transaction, there are a lot of states to go through. These states update the operating system about the current state of the transaction and also tell the user about how to plan further processing of the transaction. These states decide the regulations which decide the fate of a transaction whether it will commit or abort.

The ROLLBACK statement undo the changes made by the current transaction. A transaction cannot undo changes after COMMIT execution.
Following are the different types of transaction States :
Active State: When the operations of a transaction are running then the transaction is said to be active state. If all the read and write operations are performed without any error then it progresses to the partially committed state, if somehow any operation fails, then it goes to a state known as failed state.
Partially Committed: After all the read and write operations are completed, the changes which were previously made in the main memory are now made permanent in the database, after which the state will progress to committed state but in case of a failure it will go to the failed state.
Failed State: If any operation during the transaction fails due to some software or hardware issues, then it goes to the failed state . The occurrence of a failure during a transaction makes a permanent change to data in the database. The changes made into the local memory data are rolled back to the previous consistent state.
Aborted State: If the transaction fails during its execution, it goes from failed state to aborted state and because in the previous states all the changes were only made in the main memory, these uncommitted changes are either deleted or rolled back. The transaction at this point can restart and start afresh from the active state.
Committed State: If the transaction completes all sets of operations successfully, all the changes made during the partially committed state are permanently stored and the transaction is stated to be completed, thus the transaction can progress to finally get terminated in the terminated state.
Terminated State: If the transaction gets aborted after roll-back or the transaction comes from the committed state, then the database comes to a consistent state and is ready for further new transactions since the previous transaction is now terminated.
Locking mechanism:
We are using MySQL database to execute the Lock mechanism. If you do not have MySQL, download it from here for your respective operating system.
1. Creating a Database
Syntax for creating a database:
CREATE DATABASE <database_name>;
USE <database_name>;
Creating a database named LOCKS in the MySQL database.
-- creating a LOCKS database in MySQL
CREATE DATABASE LOCKS;
-- activating the LOCKS database for use
USE LOCKS;
MySQL Workbench illustration of the above SQL commands:

2. Table Creation
Syntax for creating a table:
CREATE TABLE <table_name> (
<column_name1> <data_type>,
<column_name2> <data_type>,
<column_name3> <data_type>,
...
);
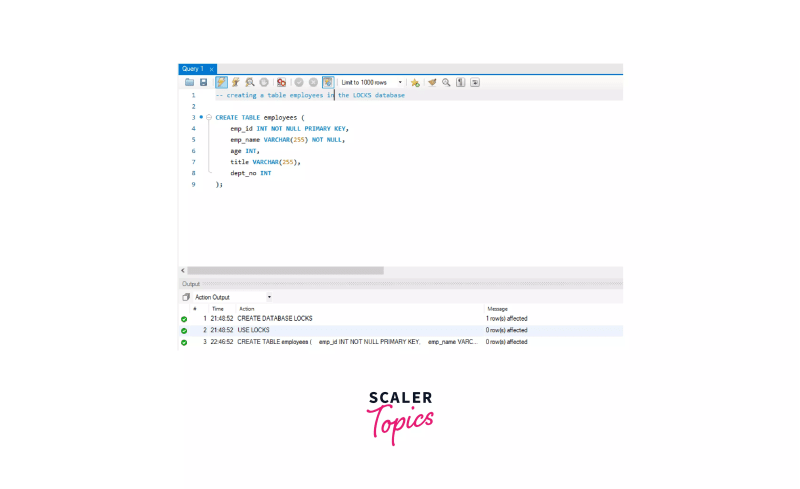
Creating a table named employees in the LOCKS database.
CREATE TABLE employees (
emp_id INT NOT NULL PRIMARY KEY,
emp_name VARCHAR(255) NOT NULL,
age INT,
title VARCHAR(255),
dept_no INT
);
3. Inserting Data into the Table
Syntax for inserting a row into the table:
INSERT INTO <table_name> VALUES (column1_value, column2_value, column2_value, ...);
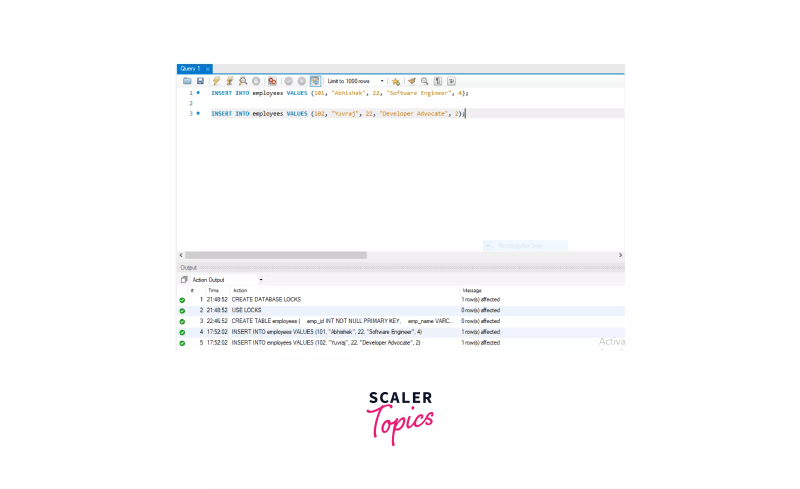
Inserting values in the employees table.
INSERT INTO employees VALUES (101, "Abhishek", 22, "Software Engineer", 4);
INSERT INTO employees VALUES (102, "Yuvraj", 22, "Developer Advocate", 2);
4. View Table
Syntax to view table in the output:
SELECT * FROM <table_name>
Viewing the employees table.
SELECT * FROM employees;

5. Applying and Removing Locks
Two types of Lock can be placed on MySQL database resources:
- READ Lock
- WRITE Lock
These locks are discussed below:
READ LOCK in MySQL
- In a READ lock (also known as a shared lock), the user can only read data from a table, and cannot modify the data.
- Multiple sessions can obtain a READ lock for a table simultaneously. Other sessions can also read data from the table without having to acquire the lock.
- The MySQL session with a READ lock in place can only read data from the table and cannot write anything until the READ lock is freed. Also, other sessions will not be unable to write data to the table. Write operations from another session will be kept in a running... state until the READ lock is freed.
Syntax to apply a READ lock:
LOCK TABLE <table_name> READ;
Syntax to remove lock:
UNLOCK TABLES;
This statement will remove the locks from the table of the active database.
Let's see how we can apply and remove a READ lock from the employees table.
First, create a MySQL connection in the MySQL workbench, connect to the MySQL database using your password, then use the below syntax to get your current MySQL session id.
SELECT connection_id();
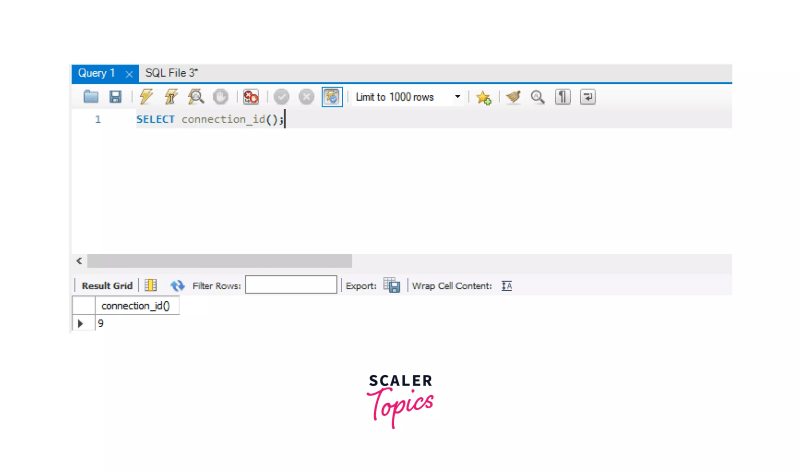
Let's place a READ lock on the employees table now.
LOCK TABLE employees READ;
Now, let's try to UPDATE the title of emp_id = 101 to "Advanced Software Engineer".
UPDATE employees SET title="Advanced Software Engineer" where emp_id = 101;
MySQL throws an error as follows:
Error Code: 1099. Table 'employees' was locked with a READ lock and can't be updated

We can see that, we can't write/modify our table contents once we have applied a READ lock on the employees table. Let's try to modify the content of the table from a different session.
Let's create another MySQL connection in the MySQL workbench, again connect to the MySQL database using your password, then use the below syntax to get your current MySQL session id.
SELECT connection_id();

Again, let's try to run the same query.
UPDATE employees SET title="Advanced Software Engineer" where emp_id = 101;
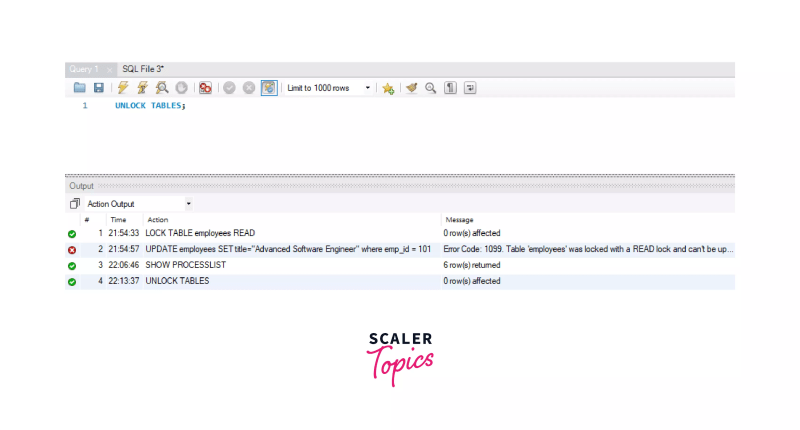
As the first session already has a READ lock in place on the employees table, MySQL keeps the above update query in the running... state on this second session. We can't modify the employees table until and unless the lock is removed from the table from session 1.

We can use SHOW PROCESSLIST; to get detailed information about the query. We can see this in the image below.

Let's remove the READ lock from the table so that the session 2 query will be executed:
UNLOCK TABLES;

Let's check session 2, we can see that the update query which was in running state is executed now.
WRITE LOCK in MySQL
- In WRITE lock (also known as an exclusive lock), the user can only write/modify and read the data of a table of the current session only.
- Other sessions can't write or read the data until the WRITE lock is freed.
Syntax to apply a WRITE lock:
LOCK TABLE <table_name> WRITE;
Syntax to remove lock:
UNLOCK TABLES;
This statement will remove the locks from the table of the active database.
Now, let's see how we can apply a WRITE lock on the employees table.
Create two MySQL connections in the MySQL workbench, and connect to the MySQL database using your password.
Let's place a WRITE lock on the employees table now in session 1.
LOCK TABLE employees WRITE;
Now, let's try to INSERT a value into the table.
-- writing data into the table session 1
INSERT INTO employees VALUES (103, "Rohan", 24, "Application Engineer", 3);
-- reading data from the table session 1
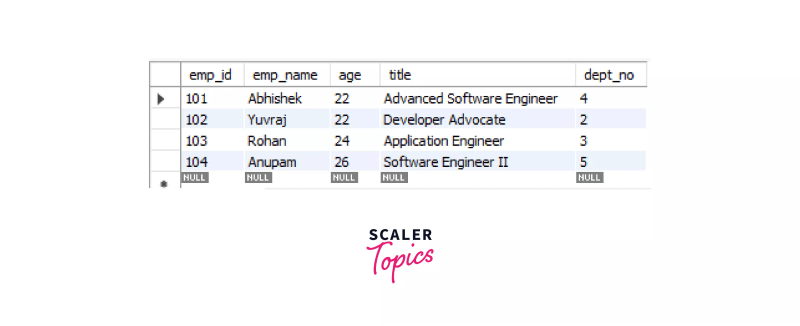
SELECT * FROM employees;

We can see that, we can write/modify and read data from the employees table from session 1.
Let's try to INSERT another value from session 2 of MySQL.
-- writing data into the table session 1
INSERT INTO employees VALUES (104, "Anupam", 26, "Software Engineer II", 5);
-- reading data from the table session 1
SELECT * FROM employees;

We can see that, we can't read or write data into the table from session 2 of the MySQL database once we have applied a WRITE lock on the employees table.
Let's remove the WRITE lock from the table so that the session 2 query will be executed:
UNLOCK TABLES;
Let's check session 2, we can see that the update query which was in running state is executed now and a row is inserted into the table.
Conclusion
- Locks are placed on SQL resources to avoid several transactions to access the same resource simultaneously, such as rows accessed or manipulated by a transaction by two users at the same time.
- Locks in SQL are used to adhere to the ACID properties in DBMS during a transaction.
- Locks are applied to the database resources like RID, Key, Page, Extent, Table, and Database.
- Locks are of 6 types, Extent (X), Shared (S), Update (U), Intent (I), Schema (Sch), and Bulk Update (BU) lock.
Database Isolation Levels:
Transaction Management is an essential mechanism of relational Database Management Systems. They allow for concurrency whilst maintaining the ACID properties: Atomicity, Consistency, Isolation and Durability. They are used to control and maintain the integrity of each action in a transaction, despite errors that may occur in the system.
Understanding the various isolation levels and choosing the one that fits your project and allows to achieve better performance or/and guarantee data consistency. Let’s take a look at them and how to define them on a Play 2 with PostgreSQL environment.
Isolation Levels
A Transaction consists of a series of read and write operations of database objects that are meant to be atomic: either all actions are carried out or none are. [Raghu p.523]
For performance reasons a DBMS might interleave transactions, sacrificing the isolation of a transaction from other concurrently executing transactions. They can run of different levels of isolation, each one having a bigger toll on performance although offering a more isolated execution context. DBMS manage transaction concurrency by applying Locks to the required objects. The more elevated isolation level the more locks the transaction will have to acquire in other to execute, thus preventing other concurrent transactions from using the same resources.
Let’s go over the major JDBC levels:
- TRANSACTION_NONEIn this mode, all read and write operations can execute concurrently.
- TRANSACTION_READ_COMMITTEDAn operation will only be able to read values that were committed, i.e written by a terminated transaction, before it started. This prevents the problem know as ‘Dirty Read’ (or Write-Read Conflict) which happens when a transaction T1, reads a value written by a another transaction T2, that is not yet committed. If T2 aborts, the value that T1 read will be wrong, thus causing an inconsistency.
- TRANSACTION_REPEATABLE_READAll operations within the transaction will only be able to read values that were commit previous to the start of the transaction. Adding this limitation solves the ‘Non-repeatable Read’ problem (or Read-Write Conflict). Assume that a transaction T1 reads a given value. If another transaction T2 overwrites that value, and T1 tries to read it again, T1 will get a different value without having changed it.
- TRANSACTION_SERIALIZABLEThis is the stricter mode. Transactions execute as they would in a serial execution mode. They still execute concurrently but if a transaction T1 tries to access any object that was used by another transaction T2, this will cause T1 to abort. In this mode, as well as preventing the previous issues, also the ‘Phantom Read’ is prevented. A ‘Phantom Read’ occurs when, during the course of a transaction T1, when another transaction T2 inserts or deletes rows. The same operation running on T1 context may yield a different result if executed before and after T2.
Isolation level on Play 2
To set the isolation level of the transactions on a Play 2 project use the following config:
db.default.isolation="VALUE"
The allowed values are NONE, READ_COMMITTED_, _READ_UNCOMMITTED, REPEATABLE_READ and SERIALIZABLE. If you get a Configuration Error for an “Unknown isolation level” try adding a space after the value. This is due to a bug in the Play DB API.
Optionally, you can set the level per transaction, if you’re writing plain SQL, by defining the isolation level in the BEGIN TRANSACTION statement, like for example:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Or if you using the Slick framework you can set the level in a wrapper for the withTransaction method:
CodacyDB.database.withTransaction { session =>
session.conn.setTransactionIsolation(
java.sql.Connection.TRANSACTION_READ_COMMITTED
)
...
}
We’ve seen and understood different database isolation levels applied to transactions. We’ve specified how this can be achieved in Play using Slick. We’ve used this internally in the process of scaling Codacy to thousands of projects under analysis. Would love to hear what you’re currently using for your application!
Triggers:
What are the Triggers in SQL?

You might have encountered situations where you have to constantly check a database table for a particular column to get updated, where, once updated, you have some tasks to do.
Here the first solution which comes to mind is making a select statement (to check for a specific condition) on the table in an interval of a few seconds or minutes. But this doesn’t seem to be a good choice, right? Instead of us asking the database whether the data has been updated or not, the database should tell us when the data gets updated. This is what exactly triggers do. Triggers, as the name tells us, are stored procedures (procedures are functions that contain SQL statements stored in the database and can return some output) that are executed or fired when some events occur. The user defines these events. The trigger may be set on a row insertion in a table or an update to an existing row and at other points, which we will discuss here. Before moving forward, it is important to discuss what DDL and DML operations are.
DDL stands for Data definition language, which is used in changing the structure of a table, i.e., creating a table, adding a column to an existing table, or deleting the whole table. However, DML stands for Data manipulation language, which is used to manipulate the data, i.e., insert some new data into the table or update existing data. Also, for deleting some rows, we make use of DML operations.
Types of Triggers
The following are the different types of triggers present in SQL.
DML Triggers
These triggers fire in response to data manipulation language (DML) statements like INSERT, UPDATE, or DELETE.
Display Triggers in SQL
If someone creates a trigger but forgets the trigger's name, then you can find the trigger by running a simple command.
Query 6:
SHOW TRIGGERS LIKE 'stu%'\G;
This command will show you the list of all available triggers matching with the string ‘stu’. Note that the \G tag ends the statement just like a semicolon (;). However, since the output table is wide, the \G rotates the table visually to vertical mode.
mysql> SHOW TRIGGERS LIKE 'stu%'\G
********************* 1. row *********************
Trigger: student_name
Event: INSERT
Table: student
Statement: SET full_name = first_name || '' || last_name
Timing: AFTER
Created: NULL
sql_mode: NO_ENGINE_SUBSTITUTION
Definer: me@localhost
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: latini_swedish_ci
Drop Triggers in SQL
The deletion of a trigger is quite straightforward. You need to run a simple query to delete a trigger from the database.
So in our case, as per the example above, the query will be
Query 5:
DROP TRIGGER student_name;
This will erase the trigger from the database.
Advantages of Triggers in SQL
- Using triggers, you can eliminate the use of schedulers mostly. Schedulers are applications that keep running in the background and help run a task at a specific time. These timely checks can be removed and instead checked immediately whenever a particular data changes using triggers. It is basically a better replacement for schedulers.
- These are useful in having additional security checks. There are many critical components in business software, and some of them might risk highly sensitive data if not taken care of properly. Many developers work on a critical component, so some security checks must be done for the data being inserted, updated, or deleted. Here triggers help in maintaining a healthy system by warning about security issues if they exist.
- One can eliminate the risk of inserting invalid data into a column by having a check for that column or a simple update. Let’s say in the student_name table (where first_name and middle_name are both nullable, i.e., both the columns can accept null values), someone has inserted a row with middle_name keeping the first_name as null. Here the insertion will be successful, but the data is invalid. We can log the error, or also we can move the middle_name value to first_name.
- These are useful in cleaning activities since we can run some cleanup procedures on listening to deletion events. For example, there are two tables, students and parents. Ideally, if we deleted some students' data from the student's table, the corresponding data from parents (entries of those parents whose children are getting removed) also should get deleted. Since we are prone to such mistakes where we forget to delete data from parent's tables deleting from students, we can handle this very easily using triggers. We can have a trigger on students deletion, wherein on each DELETE operation, we may proceed to remove the corresponding entry from the parents' table.
Disadvantages of Triggers in SQL
- These are difficult to troubleshoot because they are run automatically, and improper logging will result in unknown updates, which could be very time-consuming to debug in large-scale projects.
- Triggers increase the overhead of database DML queries. Since for every row we insert, update or delete, it may either do an update or an insertion – say into a new table, or even a row deletion altogether further that might not be required at the moment.
- Only limited validation can be done at triggers like Not Null checks, Equality checks, Unique checks, etc. Though we can use triggers to handle most of our business use cases, it doesn’t give a full proof solution for every case. Since SQL is a data manipulation language, we cannot expect it to replace programming language dependency for validations. We still need to depend on other validation along with this. Also, in some scenarios, data validation on SQL is costly compared to validation on the service side.

Top comments (1)
Very true as understanding the ACID properties—Atomicity, Consistency, Isolation, and Durability—is fundamental in database management systems. These principles ensure transactions are reliably processed, maintaining data integrity and reliability. By adhering to ACID, DBMSs guarantee that database operations occur accurately and consistently, crucial for robust and dependable data management in various applications. Do check out the Best Data Science training institute for more information on SQL!