In this blog we will learn the basics for undestaning concurrency control in PostgreSQL but before that lets see what concurrency conrol is and what is it used for.
Concurrency Control
Concurrency control is a mechanism used to maintain ACID properties when multiple transactions are running concurrently in a database. Three main techniques are used: Multi-version Concurrency Control (MVCC), Strict Two-Phase Locking (S2PL), and Optimistic Concurrency Control (OCC). MVCC creates a new version of a data item when it's written, while retaining the old version. This ensures isolation of individual transactions, and readers and writers don't block each other. PostgreSQL and some RDBMSs use a variation of MVCC known as Snapshot Isolation (SI).
Right now this might look complex but dont worry in this blog we will only learn the basic knowledge required to understand concurrency control.
Transaction ID
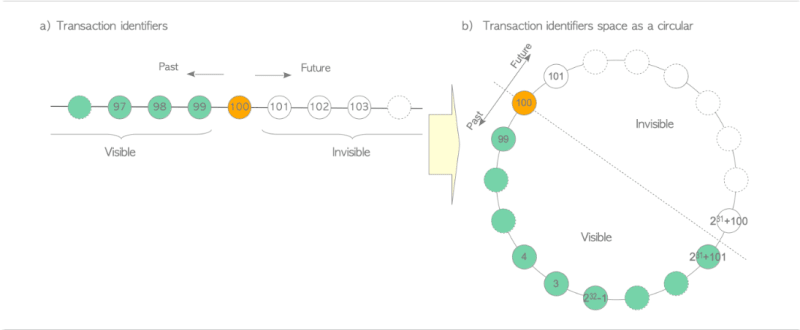
In PostgreSQL, a unique identifier called a transaction id (txid) is assigned to every transaction by the transaction manager. PostgreSQL's txid is a 32-bit unsigned integer, allowing for approximately 4.2 billion possible txids. When a transaction starts, the built-in txid_current() function returns the current txid. PostgreSQL reserves three special txids: 0 for Invalid txid, 1 for Bootstrap txid used only during database cluster initialization, and 2 for Frozen txid. Txids can be compared, with those greater than the current txid being invisible and those less than it being visible. However, since the txid space is limited, PostgreSQL treats it as a circle where the previous 2.1 billion txids are in the past, and the next 2.1 billion are in the future.
Tuple Structure
A heap tuple in PostgreSQL table pages consists of three parts: the HeapTupleHeaderData structure, a NULL bitmap, and user data. The HeapTupleHeaderData structure, which is defined in src/include/access/htup_details.h, has seven fields, but four fields are relevant to subsequent sections. The t_xmin field holds the txid of the transaction that inserted the tuple, while the t_xmax field holds the txid of the transaction that deleted or updated the tuple (set to 0 if the tuple has not been deleted or updated). The t_cid field holds the command id (cid), indicating how many SQL commands were executed before this command within the current transaction (starting from 0). Finally, the t_ctid field holds the tuple identifier (tid) that points to itself or a new tuple. When this tuple is updated, the t_ctid points to the new tuple, and otherwise, it points to itself.
Basic Tuple Structure

Inserting, Deleting and Updating Tuples
This section explains how tuples are inserted, deleted, and updated in PostgreSQL, and introduces the Free Space Map (FSM) used to manage free space on pages. When a tuple is inserted, its header fields are set based on the transaction ID of the inserting transaction. When a tuple is deleted, its t_xmax field is set to the transaction ID of the deleting transaction. In an update, the latest tuple is logically deleted and a new one is inserted. PostgreSQL uses the FSM to select the page for inserting a tuple, based on its free space capacity. Each table and index has a corresponding FSM that stores the free space information for its pages.
So this blog goes over the basics. Now we know about transaction ID and Tuples Structure we can go forward with cocurrency control. Feel free to study the book the internals of PostgreSQL for more in depth undestanding.

Top comments (0)