
Our #GraphQLJanuary continues with blog posts, live streams, Discord Q&A, office hours, and more. For a schedule of upcoming events, join the community or register at https://hasura.io/graphql/graphql-january/.
_In this post, Hasura engineer Toan shares his experience with using Hasura alongside TimescaleDB 2.0 and exploring what works...and what doesn’t. Learning from the experience of others exploring workarounds to achieve their goals is always instructive.
This is the second post in the series, the first is TimescaleDB 2.0 with Hasura._
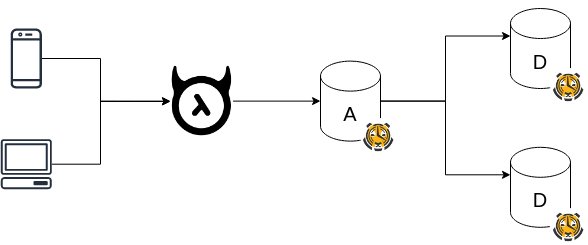
Multi-node is the most interesting feature of version TimescaleDB 2.0 that provides the ability to create a cluster of TimescaleDB instances to scale both reads and writes. A multi-node TimescaleDB cluster consists of:
- One access node to handle ingest, data routing and act as an entry point for user access;
- One or more data nodes to store and organize distributed data.
In this post, I will try setting up this Multi-node feature and running it with Hasura.
The example code is uploaded on Github
Infrastructure setup
Cluster requirements:
- Network infrastructure is ready. It is necessary for the access node to connect to data nodes when adding them.
- Authentication between nodes. The access node distributes requests to data nodes through the client library, so it still needs authentication credentials.
There are 3 authentication mechanisms:
- Trust authentication
- Password authentication
- Certificate authentication
In this demo, we will use the first mechanism. You may think that this approach is insecure. I don't disagree. But it is fine for the purpose of this exploration. And we will place the TimescaleDB cluster into a private cloud, and expose only the access node to the internet. The Docker environment can emulate it.
You can read more detail about authentication in official TimescaleDB docs.
First of all, we need to register data nodes to the access node.
SELECT add_data_node('data1', host => 'timescaledb-data1');
host can be IP or DNS name. In docker, you can use alias name.
Note: this function requires running in AUTOCOMMIT mode. So you can only run it with psql, or custom migration CLI. However, I don't recommend using migration, because Multi-node cluster configuration is different if you run multiple development environments (dev, staging, production...).
You can add nodes manually with psql. Fortunately, the Postgres docker image supports initialization hooks /docker-entrypoint-initdb.d. You can use a bash script to add them automatically.
# multinode/scripts/add-data-nodes.sh
psql -v ON_ERROR_STOP=1 -U "$POSTGRES_USER" -d "$POSTGRES_DB" <<-EOSQL
SELECT add_data_node('$node', host => '$node');
EOSQL
Can we register reversely from data node to access node?
It is possible. However you have to customize Postgres image. The temporary Postgres server for initialization scripts isn't exposed to external network (source). Therefore we can't run remote psql to register a node.
Other solutions are:
- Create an initialization container that waits for all Postgres servers to be online, then run
psqlscript. - Use Patroni with
postInithooks.
Create Distributed hypertable
As a next step, we need to create a distributed hypertable instead of normal, non-distributed hypertable. The difference of Distributed hypertable is that the data is stored across data node instances. The access node stores metadata of data nodes and distributes the requests and queries appropriately to those nodes, then aggregates the results received from them. Non-distributed hypertable still stores data locally in the current server.
The function is similar to hypertable. We run it after creating table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL DEFAULT NOW(),
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
SELECT create_distributed_hypertable('conditions', 'time');
Here we encounter another issue.

Prepared transactions are disabled by default. timescaledb-tune doesn't automatically enable this setting so we have to set it manually.
max_prepared_transactions = 150
enable_partitionwise_aggregate = on
You can mount a manual postgres.conf file in Docker container. However, it can't take advantage of timescaledb-tune. Fortunately the Postgres image also supports config flags. These can be set as arguments.
timescaledb-data1:
image: timescale/timescaledb:2.0.0-pg12
command:
- "-cmax_prepared_transactions=150"
# ...
Restart services and run the function again. You can verify by querying hypertable information:
select
hypertable_name,
num_chunks,
is_distributed,
replication_factor,
data nodes
from timescaledb_information.hypertables;
| hypertable_name | num_chunks | is_distributed | replication_factor | data_nodes |
|---|---|---|---|---|
| conditions | 2 | f | 1 | {timescaledb-data1,timescaledb-data2} |
You may notice the is_distributed column that represents whether this hypertable is distributed or not. On data nodes, this column is false or non-distributed. That means if the hypertable is detached, it can work as a normal hypertable.
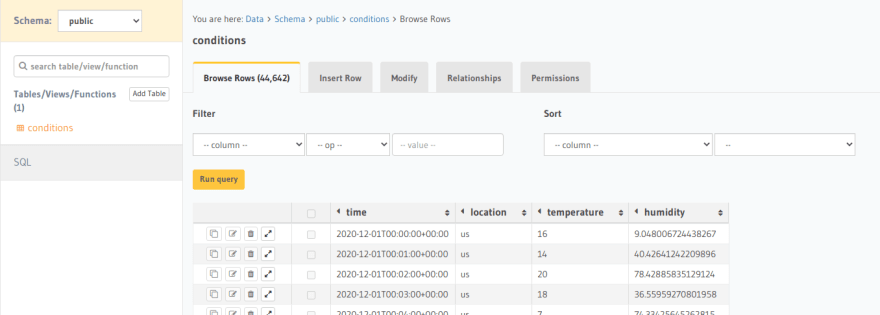
Work with data
In this test, I will run SQL script to insert 1 million rows. Let's see how long the execution takes and the number of rows per data node.
INSERT INTO conditions
SELECT time, 'US', (random()*30)::int, random()*80
FROM generate_series(
'2020-01-01 00:00:00'::timestamptz,
'2020-01-01 00:00:00'::timestamptz + INTERVAL '999999 seconds',
'1 second')
AS time;
Planning Time: 1.297 ms
Execution Time: 11763.459 ms
| access | timescaledb-data1 | timescaledb-data2 |
|---|---|---|
| 1,000,000 | 395,200 | 604,800 |
The distribution ratio isn't usually 1:1. The variance is larger when we insert large number of concurrent requests. The insert speed is very fast. It takes about 11 seconds to insert 1 million rows. In contrast, UPDATE and DELETE operations take a very long time. The below table show performance comparison between non-distributed hypertable and distributed hypertable, in milliseconds.
| Operation | Hypertable | Hypertable (JIT) | Distributed hypertable | Distributed hypertable (JIT) |
|---|---|---|---|---|
| INSERT | 3,707.195 | 4,586.120 | 12,700.597 | 11,763.459 |
| UPDATE | 4,353.752 | 4,404.471 | 184,707.671 | 204,340.519 |
| SELECT | 174.012 | 210.479 | 2,011.194 | 1,057.094 |
| DELETE | 737.954 | 883.095 | 159,165.419 | 184,945.111 |
- Distributed hypertable performance is much worse than non-distributed one. In my opinion, the access node has to distribute requests to data nodes through the network. This causes higher latency cost than inserting directly into disk. Moreover, the access node takes more computing power to query from all data nodes, then aggregate the final result.
- UPDATE and DELETE operations are extremely slow. We should avoid modifying data.
- JIT mode isn't really boosting performance. From the above table, the performance is slightly improved on Distributed hypertable, but slower on non-distributed one.
However, the main purpose of distributed hypertable is handling more write requests. The slower performance is an expected trade-off.
Foreign key and Relationship
For example, we create a table locations. conditions table reference locations through location column.
CREATE TABLE "public"."locations"(
"id" Text NOT NULL,
"description" text NOT NULL,
PRIMARY KEY ("id")
);
ALTER TABLE conditions ADD CONSTRAINT conditions_locations_fk
FOREIGN KEY (location) REFERENCES locations (id);
-- ERROR: [timescaledb-data1]: relation "locations" does not exist
The foreign key can't be created. Because locations table is available in the access node only. Data nodes don't know about it.
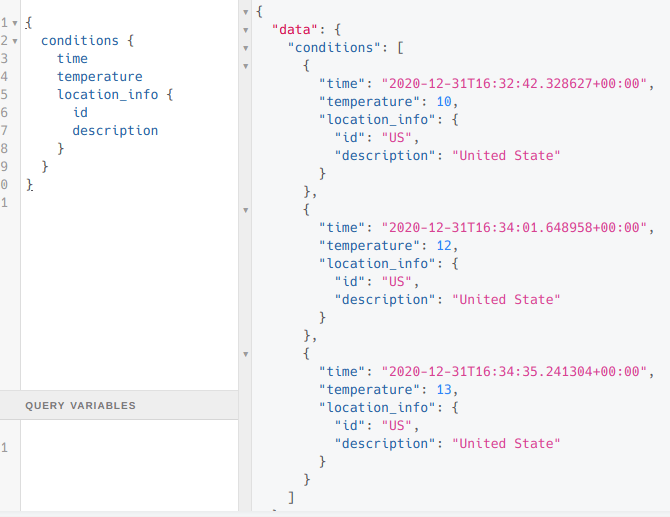
However, JOIN query is working on the access node. TimescaleDB is smart enough to map relational data.
SELECT * FROM conditions JOIN locations ON conditions.location = locations.id;
| time | location | temperature | humidity | id | description |
|---|---|---|---|---|---|
| 2020-12-31 16:32:42.328627+00 | US | 10 | 1 | US | United State |
| 2020-12-31 16:34:01.648958+00 | US | 12 | 1 | US | United State |
| 2020-12-31 16:34:35.241304+00 | US | 13 | 13 | US | United State |
Continuous Aggregate View
We can't create a Continuous Materialized view (see Caveats below).
postgres= CREATE MATERIALIZED VIEW conditions_summary_minutely
postgres- WITH (timescaledb.continuous) AS
postgres- SELECT time_bucket(INTERVAL '1 minute', time) AS bucket,
postgres- AVG(temperature),
postgres- MAX(temperature),
postgres- MIN(temperature)
postgres- FROM conditions
postgres- GROUP BY bucket;
ERROR: continuous aggregates not supported on distributed hypertables
Fortunately we still can create View or Materialized view. Therefore we can do a workaround with View or the combination of Materialized view and a scheduled job. The downside is a performance hit compared to the continuous view.
CREATE MATERIALIZED VIEW conditions_summary_hourly AS
SELECT time_bucket(INTERVAL '1h', time) AS bucket,
AVG(temperature),
MAX(temperature),
MIN(temperature)
FROM conditions
GROUP BY bucket;
CREATE OR REPLACE PROCEDURE conditions_summary_hourly_refresh(job_id int, config jsonb) LANGUAGE PLPGSQL AS
$$
BEGIN
REFRESH MATERIALIZED VIEW conditions_summary_hourly;
END
$$;
SELECT add_job('conditions_summary_hourly_refresh','1h');
SQL function
Custom SQL functions for GraphQL queries work well. These functions are created on the Access node only. However, the query engine is smart enough to get data from data nodes.
CREATE OR REPLACE FUNCTION search_conditions(location text)
RETURNS SETOF conditions
LANGUAGE sql STABLE
AS $$
SELECT * FROM conditions
WHERE conditions.location = location;
$$
However, Triggers don’t appear to work. The access node doesn't automatically create SQL functions and Triggers to data nodes. You have to create them on each data node.
There are more consideration in the Caveats section.
Run with Hasura GraphQL Engine
It isn't different from running with Postgres. GraphQL Engine service only needs connecting to the access node's database URL. There are still issues that are similar to non-distributed hypertable. View and SQL query function works as expected.
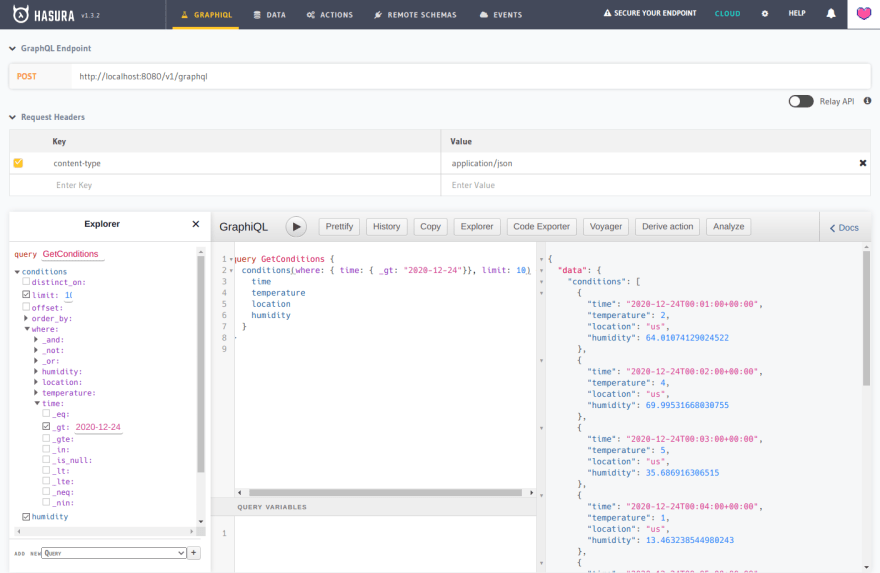
However, because Foreign keys doesn't work on a distributed hypertable, GraphQL Engine can't automatically suggest relationships. It is necessary to define them manually.

Caveats
Beside non-distribution hypertable caveats, distributed hypertable has more considerations:
- Besides hypertable, other features aren't distributed: background jobs, Continuous aggregate view, compression policies, reordering chunks...
- Joins on data nodes are not supported.
- Consistent database structure required between access and data nodes.
- If you create SQL functions, foreign keys,... you have to create them in all data nodes. The access node can't automatically do it for you.
- Native replication is still in experiment.
The root cause is in the access node that can't manage consistent metadata with data nodes yet. It can't automatically sync database structure to data node except distributed hypertables. However, TimescaleDB 2.0 is still in early stage. The caveats still have chance to be solved in next versions.
You can read more detail in TimescaleDB docs
So, should I use it?
Yes, if you really need to scale write performance, and don't use Continuous aggregate view, compression policies features, at least in near future. In theory, you still can create them manually in each data node, since these hypertables in data nodes are normal one. However this workaround could lead to inconsistent database structures between nodes.
The access node is still a TimescaleDB server. You still can create tables and local hypertables and use them along with distributed hypertables.
In the next, and final, part of this series I will discuss High Availability in greater detail. Thanks to the TimescaleDB team for their work and advice.

Top comments (0)