
At Honeycomb, we’re big fans of AWS Spot Instances. During a recent bill reduction exercise, we found significant savings in running our API service on Spot, and now look to use it wherever we can. Not all services fit the mold for Spot, though. While a lot of us are comfortable running services atop on-demand EC2 instances by now, with hosts that could be terminated or fail at any time, this is relatively rare when compared with using Spot, where sudden swings in the Spot market can result in your instances going away with only two minutes of warning. When we considered running a brand-new, stateful, and time-sensitive service on Spot, it seemed like a non-starter, but the potential upside was too good to not give it a try.
Our strong culture of observability and the environment it enables means we have the ability to experiment safely. With a bit of engineering thoughtfulness, modern deployment processes, and good instrumentation we were able to make the switch with confidence. Here's how we did it:
What we needed to support
We're working on a feature that enables you to do trace-aware sampling with just a few clicks in our UI. The backend service (internal name Dalmatian) is responsible for buffering trace events and making sampling decisions on the complete trace. To work correctly, it must:
- process a continuous, unordered stream of events from the API as quickly as possible
- group and buffer related events long enough to make a decision
- avoid re-processing the same traces, and make consistent decisions for the same trace ID for spans that arrive late
To accomplish grouping, we use a deterministic mapping function to route trace IDs to the same Kafka partition, with each partition getting processed by one Dalmatian host. To keep track of traces we’ve already processed, we also need this pesky little thing called state. Specifically:
- the current offset in the event stream,
- the offset of the oldest seen trace not yet processed,
- recent history of processed trace IDs and their sampling decision.
This state is persisted to a combination of Redis and S3, so Dalmatian doesn’t need to store anything locally between restarts. Instead, state is regularly flushed to external storage. That’s easy. Startup is more complex, however, as there are some precise steps that need to happen to resume event processing correctly. There’s also a lot of state fetching to do, which adds time and can fail. In short, once the service is running, it’s better to not rock the boat and just let it run. Introducing additional chaos with hosts that come and go more frequently was something to consider before running this service on Spot.
Chaos by default
As part of the observability-centric culture we strive for at Honeycomb, we embrace CI/CD. Deploys go out every hour. Among the many benefits of this approach is that our deploy system is regularly exercised, and our services undergo restarts all the time. Building a stateful service with a complex startup and shutdown sequence in this environment means that bugs in those sequences are going to show themselves very quickly. By the time we considered running Dalmatian on Spot (queue the puns), we’d already made our state management stable through restarts, and most of the problems Spot might have introduced were already handled.
Hot spare Spots
There was one lingering issue with using Spot though: having hosts regularly go away means we need to wait on new hosts to come up. Between ASG response times, Chef, and our deploy process, it averages 10 minutes for a new host to come online. It’s something we hope to improve one day, but we’re not there yet. With one processing host per partition, that means losing a host can result in at least a 10 minute delay in event processing. That’s a bad experience for our customers, and one we’d like to avoid. Fortunately, Spot instances are cheap, and since we’re averaging a 70% savings on instance costs, we can afford to run with extra hosts in standby mode. This is accomplished with a bit of extra terraform code:
min_size = var.dalmatian_instance_count[var.size] + ceil(var.dalmatian_instance_count[var.size] / 5)
max_size = var.dalmatian_instance_count[var.size] + ceil(var.dalmatian_instance_count[var.size] / 5)
With a small modification in our process startup code, instances will wait for a partition to become free and immediately pick up that partition’s workload.
Spot how we're doing
We’ve made a significant change to how we run this service. How do we know if things are working as intended? Well, let’s define working, aka our Service Level Objective. We think that significant ingestion delays break our core product experience, so for Dalmatian and the new feature, we set an SLO that events should be processed and delivered in under five minutes, 99.9% of the time.
With the SLO for context, we can restate our question as: Can we move this new functionality onto Spot Fleets and still maintain our Service Level Objective despite the extra host churn?

In the last month in our production environment, we have observed at least 10 host replacements. This is higher than usual churn than we’ve had in the past, but also what we expected with Spot.
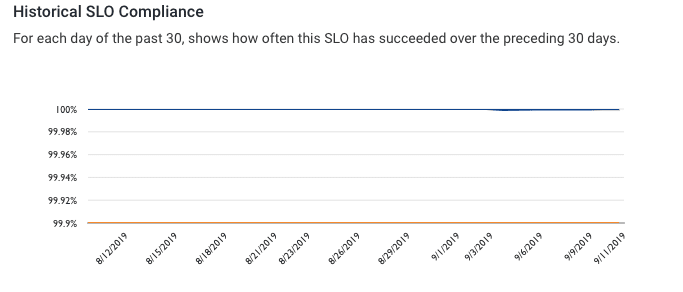
In that same month, we stayed above our threshold for SLO compliance (99.9%). From this perspective, it looks like a successful change - one we’re excited about because it saves us a significant amount in operational expenses.
New firefighting capabilities must be part of the plan
Things are working fine now, but they might break in the future. Inevitably, we will find ourselves running behind in processing events. One set of decisions we had to make for this service was “what kind of instance do we run on, and how large?”. When we’re keeping up with incoming traffic, we can run on smaller instance types. If we ever fall behind, though, we need more compute to catch up as quickly as we can, but that’s expensive to run all the time when we may only need it once a year. Since we have a one processor per partition model, we can’t really scale out dynamically. But we can scale up!
Due to the previously mentioned 10 min host bootstrapping time, swapping out every host with a larger instance is not ideal. We’ll fall further behind while we wait to bring the instances up, and once we decide to scale down, we’ll fall behind again. What if we stood up an identically sized fleet with larger instances and cut over to that? This Terraform spec defines what we call our “catch-up fleet”. The ASG exists only when dalmatian_catchup_instance_count is greater than 0. In an emergency, a one-line diff can bring this online.
resource "aws_autoscaling_group" "dalmatian_catchup_asg" {
name = "dalmatian_catchup_${var.env}"
count = var.dalmatian_catchup_instance_count > 0 ? 1 : 0
# ...
launch_template {
launch_template_specification {
launch_template_id = aws_launch_template.dalmatian_lt.id
version = "$Latest"
}
dynamic "override" {
for_each = var.dalmatian_catchup_instance_types
content {
instance_type = override.value
}
}
}
}
When the hosts are ready, we can cut over to them by stopping all processes on the smaller fleet, enabling the “hot spares” logic to kick in on the backup fleet. When we’re caught up, we can repeat the process in reverse: start the processes on the smaller fleet, and stop the larger fleet. Using Honeycomb, of course, we were able to verify that this solution works with a fire drill in one of our smaller environments.
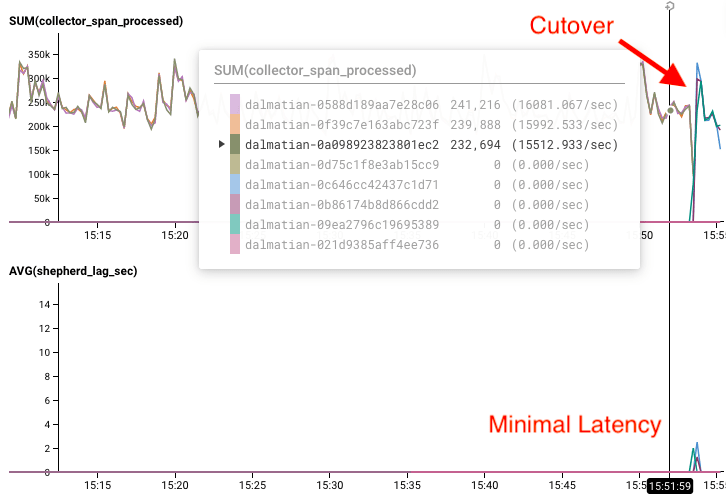
Spot the benefits of an observability-centric culture
Ok maybe that's enough spot-related puns, but the point here is that our ability to experiment with new architectures and make significant changes to how services operate is predicated on our ability to deploy rapidly and find out how those changes impact the behavior of the system. Robust CI/CD processes, thoughtful and context-rich instrumentation, and attention to what we as software owners will need to do to support this functionality in the future makes it easier and safer to build and ship software our users love and benefit from.
Ready to take the sting out of shipping new software? Honeycomb helps you spot outliers and find out how your users experience your service. Get started for free!

Top comments (0)