A sorting algorithm is an algorithm which puts elements of a list in a certain order, most commonly numerical and alphabetical order.
In this post, I will be investigating the complexity of five sorting algorithms, where two of which are considered efficient sorting algorithms.
Bubble Sort
One of the simplest sorting algorithms is bubble sort which works as follows:
Starting from the beginning of the list,
- Compare the current element with the next element
- If the current element is greater than the next element swap them
- Current element is now the next element
- Repeat from step 1 until at the end of the unordered elements
- Current element is now the first element, repeat from step 1 (Go back to the beginning of the list and make another pass)
- Stop when no swaps were made for a pass
Here is an example of Bubble Sort in action:

Analysis
In code we have,
module BubbleSort
def self.run(array)
a = array.dup
to_sort = array.length - 1
while to_sort > 0
for i in 0...(to_sort) do
if a[i] > a[i+1]
a[i], a[i+1] = a[i+1], a[i]
end
end
to_sort -= 1
end
return a
end
end
We could predict the complexity of this code to be O(n^2) as we have one loop nested in another (the for loop nested in the while loop) with both of these iterating based off of a variable which is dependent on n.
Looking at the algorithm, with each pass (steps 1 to 4) the largest unordered element will have been sorted to the end of the list. We can see that in the worst case (when the list starts in reverse order), on a given input of size n, there will need to be n-1 comparisons to sort the first element, n-2 comparisons to sort the next element and so on until the last unordered element which will need 1 comparison. Using Big O notation, simply letting each pass use n-1 comparisons and we make a total of n passes. Therefore, denoting the worst case runtime as T(n), we can see that
T(n) = O(n*(n-1)) => T(n) = O(n^2)
Selection Sort
Another simple sorting algorithm is selection sort which works as follows:
Starting from the beginning of the list,
- Find the minimum unsorted element
- Swap it with the current index (front of the unsorted list)
- Move to the next index and repeat from step 1
- Repeat until at the end of the list
Here is an example of Selection Sort in action:

Analysis
In code we have,
module SelectionSort
def self.run(array)
a = array.dup
i = 0
while i < array.length
min = { :number => a[i], :index => i }
for j in i...(array.length) do
if a[j] < min[:number]
min[:number] = a[j]
min[:index] = j
end
end
a[i], a[min[:index]] = a[min[:index]], a[i]
i += 1
end
return a
end
end
Similar to bubble sort we have one loop nested in another (a for loop nested in a while loop) with both of these iterating based off of a variable which is dependent on n. So we also predict selection sort to have a complexity of O(n^2)
Looking at the algorithm, with each pass the smallest unordered element in the list is swapped to the front of the array. In the worst case, we have to make n-1 comparisons to find the minimum the first time and one less comparison thereafter. Since each pass puts the next smallest unordered element in the correct place we need to make n-1 passes (final element is sorted without the need for another pass). So with similar reasoning to the case of bubble sort, we can approximate as follows
T(n) = O((n-1)*(n-1)) => T(n) = O(n^2)
Insertion Sort
The final simple sorting algorithm is insertion sort which works as follows:
Starting from the second element of the list,
- Compare the current element with the previous element
- If the current element is less than the previous element swap them
- Repeat step 2 until the current element is greater than the previous element
- Move to the next index and repeat from step 1
- Repeat until at the end of the list
Here is an example of Insertion Sort in action:
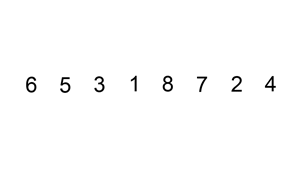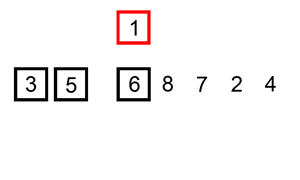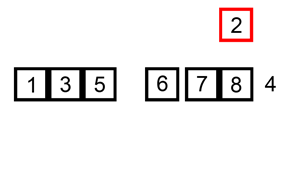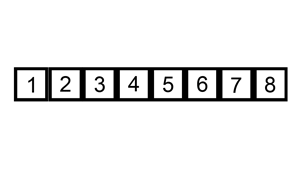
Analysis
In code we have,
module InsertionSort
def self.run(array)
a = array.dup
i = 1
while i < array.length
j = i - 1
while (a[j+1] < a[j]) && (j >= 0)
a[j+1], a[j] = a[j], a[j+1]
j -= 1
end
i += 1
end
return a
end
end
This time we don't have a for loop nested within a while loop, we instead have a while loop nested within another while loop. The outer while loop is clearly iterating over a variable dependent on n, the inner loop is not as obvious.
Looking at the algorithm, with each pass an element is added to the sublist of ordered elements at the front of the list. We make at most k comparisons for the kth pass and we make a total of n-1 comparisons, summing we can conclude
T(n) = O((n-1)*(n/2)) = O(n^2)
Comparison of simple sorting algorithms

The graph does seem to show that the algorithms are quadratic in growth (although there is a lack of data due to the limit of computational power) where insertion sort is the marginally the most efficient followed by selection sort, and then bubble sort.
Efficient Sorting Algorithms
Now we move onto the efficient sorting algorithms which are called this way because their average time complexity is O(nlogn) - and it can be proved that any comparison sorting algorithm is Theta(nlogn) which means that the time complexity is bounded below by nlogn and so it is the most efficient it can be.
Merge Sort
The first efficient sorting algorithm is merge sort which is a divide and conquer algorithm (and so uses recursion) which works as follows:
- Split the list into sublists each containing one element
- Repeatedly merge sublists until there is only one sublist remaining - the sorted list.
When merging, sorted sublists are created by choosing the smallest element from each sublist to be merged until one sublist is empty. If the other sublist still has elements then append the rest of the elements to the end of the sorted sublist.

Analysis
In code we have,
module MergeSort
def self.run(array)
a = array.dup
TopDownSplitMerge(array, 0, array.length, a) # Sort from (input) array into a
return a
end
def self.TopDownSplitMerge(b, start, finish, a)
return if (finish - start < 2) # Base case: An array of one element is sorted
middle = (finish + start) / 2
# Recursively sort both runs from array a into array b
TopDownSplitMerge(a, start, middle, b) # Sort the left run
TopDownSplitMerge(a, middle, finish, b) # Sort the right run
TopDownMerge(b, start, middle, finish, a) # Merge the resulting runs from array b into array a
end
def self.TopDownMerge(a, start, middle, finish, b)
i = start
j = middle
for k in start...finish do
if (i < middle && (j >= finish || a[i] <= a[j]))
b[k] = a[i]
i += 1
else
b[k] = a[j]
j += 1
end
end
end
end
It can be shown, using a recursion tree, that in the worst case
T(n) = O(nlogn)
Quick Sort
Another efficient sorting algorithm which is also a divide and conquer algorithm is quick sort which works as follows:
- Choose a pivot element
- Partition the remaining elements into two sub-arrays, one containing elements less than the pivot and the other containing elements greater than the pivot
- Recursively sort the sub-arrays
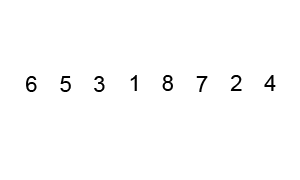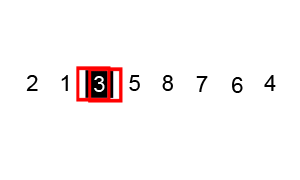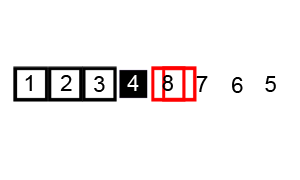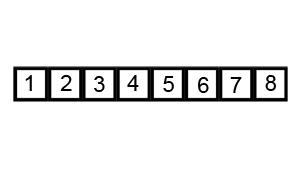
Analysis
In code we have,
module QuickSort
def self.run(array, pivot = "random")
a = array.dup
return a if a.length < 2
pivot == "random" ? r = rand(a.length) : r = 0
pivot = a[r]
lower = []
upper = []
(a[...r] + a[(r+1)..]).each { |n|
if n < pivot
lower.append(n)
else
upper.append(n)
end
}
run(lower) + [pivot] + run(upper)
end
end
It can be shown that in the worst case,
T(n) = O(n^2)
Comparison of efficient sorting algorithms

We can see that Merge sort and quick sort are much more efficient than even the fastest simple sort, insertion sort. From the graph, the efficient sorts are much more linear in growth which coincides with the complexity of nlogn as opposed to n^2 - this is a little surprising for the case of quick sort which has a time complexity of O(n^2).

It can be shown, through probabilistic analysis, that quick sort, with a random pivot, actually has an average time complexity of O(nlogn). We can see this on the above graph where quick sort and merge sort are quite similar in growth.
Thoughts
There are a wide variety of sorting algorithms and it seems that divide and conquer is a very powerful paradigm in terms of complexity. Analysing algorithms for the worst case is helpful but it is important to look at the average case as it can allow you to use algorithms which may be slightly less efficient but better in other ways such as simplicity or even time complexity.

Top comments (0)