After graduating from Makers Academy I thought it would be interesting to look at topics which are not covered on the course but are still important to being a developer, this included Algorithmic Complexity.
Algorithmic complexity can be split into two parts, time complexity and space complexity. I will be focusing on is time complexity which questions how efficient an algorithm is as the input gets larger.
The first function I looked at was Shuffle but before I did anything I had to create a timing framework so I could time my code.
Timing Framework
In Ruby, there are a few ways you could do this, I ended up using the Benchmark module.
require 'benchmark'
n = 50000
for i in 1..10 do
size = n*i
arr = ((1..size).to_a)
Benchmark.bm do |x|
x.report { arr.shuffle }
end
end
# Output
user system total real
0.000000 0.000000 0.000000 ( 0.001211)
user system total real
0.000000 0.000000 0.000000 ( 0.002816)
user system total real
0.000000 0.000000 0.000000 ( 0.005472)
user system total real
0.000000 0.015625 0.015625 ( 0.007966)
user system total real
0.000000 0.000000 0.000000 ( 0.010034)
user system total real
0.000000 0.000000 0.000000 ( 0.014221)
user system total real
0.000000 0.000000 0.000000 ( 0.012675)
user system total real
0.015625 0.000000 0.015625 ( 0.011585)
user system total real
0.000000 0.015625 0.015625 ( 0.018004)
user system total real
0.015625 0.000000 0.015625 ( 0.016173)
The main information I was looking for was the realtime (last column) so I instead just used Benchmark.realtime and also ran the code multiple times so I could use the average runtime. Some further optimisations I did were, I changed the input size to be a range to allow for easier adjustment, returned the time in (Seconds x 10⁹) for clarity and removed outliers by throwing away the top and bottom 5% of results.
require 'benchmark'
a = 5000
b = 100000
count = b / a
for i in 1..count do
size = a*i
arr = ((1..size).to_a)
results = []
times = 100
for i in 1..times do
results << Benchmark.realtime { arr.shuffle }
end
out = times*0.05
results.sort!
results.shift(out)
results.pop(out)
time = (results.inject(:+)/results.length) * (10**9)
puts "#{size} #{time}"
end
# Output
5000 106623.33333534157
10000 222154.4444384765
15000 319890.00000167935
20000 439441.1111257391
25000 380744.4444520217
30000 442679.9999995031
35000 525283.3333340985
40000 786333.3333135516
45000 752957.7777657121
50000 773688.8888934522
55000 915482.2222095997
60000 1063672.2222165596
65000 941309.9999922755
70000 1014344.4444490038
75000 1111192.222232502
80000 1243894.4444486173
85000 1382976.666665551
90000 1472218.8888855372
95000 1501871.1111072965
100000 1648841.111111526
I then used Excel to plot the data on a graph.
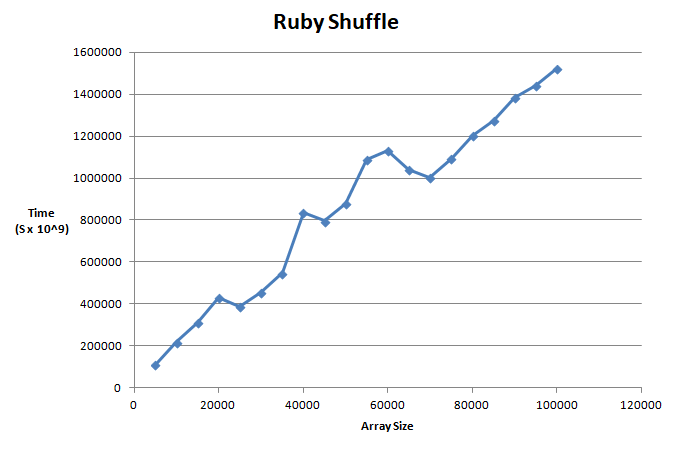
Looks pretty good, now I can try to write my own algorithm for shuffle.
Shuffle Algorithm: Naive Approach
My first approach was a naive one which involved using the delete function
def bad_shuffle(array)
arr = array.dup
new_arr = []
until arr.empty?
i = rand(arr.length)
new_arr << arr.delete_at(i)
end
new_arr
end
This was really slow and by isolating lines in the code I was able to discover that it was slow because of the delete_at function, so I had to do some research. I found out that delete functions on arrays are slow because after deleting an element, you have to 're-index' all the elements that come after it. This can at worst, on an input of size n, be an O(n) operation (in the case where you are removing the first element in the array).
This lead to the below graph which looks to be exponential in growth - not what you like to see.
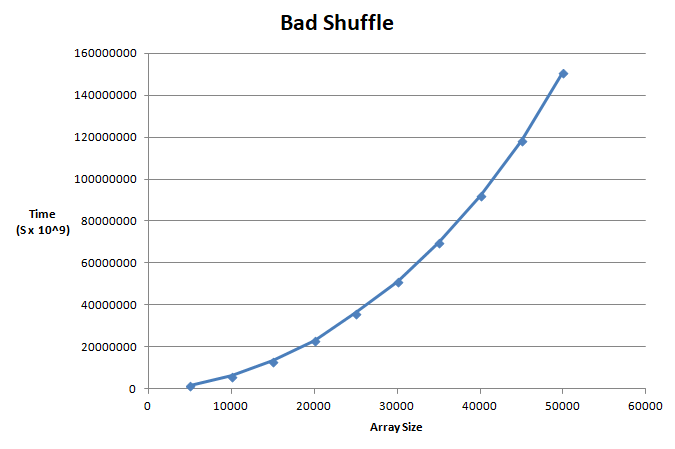
It was at this point I had remembered in my Combinatorial Optimisation module there was the mention of a shuffle algorithm which doesn't use delete.
Fisher-Yates Shuffle
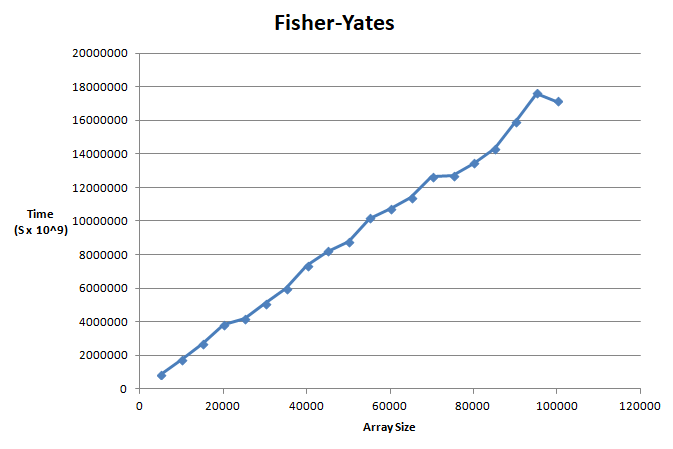
Instead of deleting elements, Fisher-Yates moves elements to the end of the array and so only needs to make lookups, which are fast (actually O(1)), and swaps.
def fy_shuffle(array)
arr = array.dup
length = arr.length
while length > 1
r = rand(length)
arr[r], arr[length-1] = arr[length-1], arr[r]
length -= 1
end
arr
end
This resulted in a much better graph that looked quite linear.
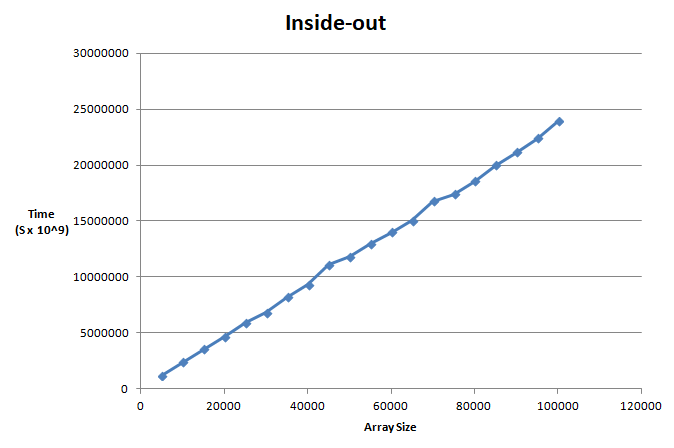
Inside-out
I also tried implementing the inside-out variant of Fisher-Yates.
def io_shuffle(array)
new_arr = []
for i in 0...(array.length)
j = rand(i+1)
new_arr[i], new_arr[j] = new_arr[j], new_arr[i] if j != i
new_arr[j] = array[i]
end
new_arr
end
This was also linear in growth but didn't seem to do better than Fisher-Yates in this case.
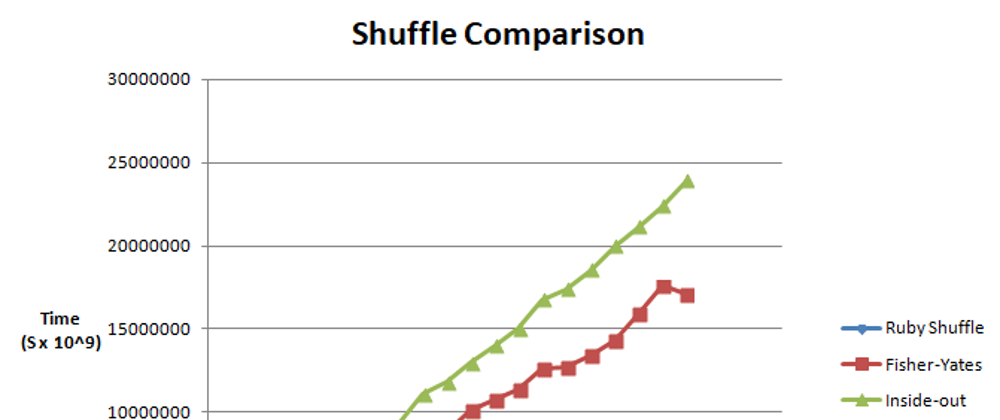
Comparison
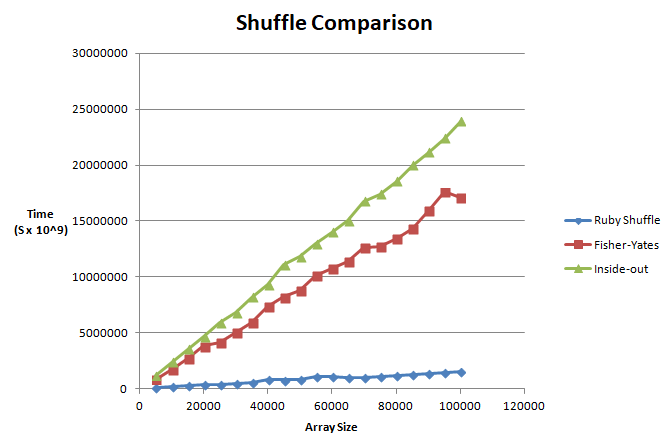
Whilst being much more efficient than the naive approach (which I couldn't fit on the graph because of how drastically slow it is), both approaches were still not as efficient as the built-in method.
Upon further research, it does turn out that Ruby's shuffle also uses the Fisher-Yates algorithm but it's that more efficient because it is written in C, a low-level language.
Thoughts
I feel like this exercise was a great introduction into algorithmic complexity and I hope to learn more about it.

Top comments (0)