
Hello and welcome to the third installment of learning Kafka.
In the preceding sections, we’ve discussed what Kafka is, its features and its core components. In this section we will be looking at how Kafka works, how it does anything. How are messages sent and retrieved from Kafka? How are messages stored? How does Kafka ensure durability, availability, throughput etc. These questions can be answered by looking at some of the architectural designs of Kafka.
These architectural designs are; Publish/Subscribe, Commit Log, Replication, Bytes-Only System.
Publish/Subscribe
Scenario:
Imagine we have two applications, App1 and App2, and we want them to exchange data, the logical way to do this is to have them send the data directly to each other.

What then if we add other applications to this system, all of them sharing data with each other, by continuing being logical, we end up with something like this;
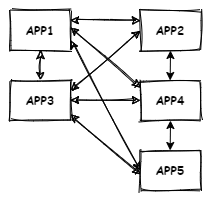
This is not ideal, the applications are tightly coupled together, if a single application fails, the whole system unravels. We can solve this problem by introducing a system that acts as a buffer between these applications, each application sends its data into the system, and also pulls the data it needs from the system.
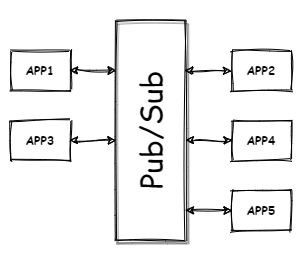
Publish/Subscribe, commonly called Pub/Sub is a messaging pattern where senders of messages, called publishers, do not send messages directly to receivers, called subscribers, but instead categorizes messages without any knowledge of subscribers or if there is even any subscriber. Likewise, subscribers express interest in one or more category of messages and only receive messages that are of particular interest to them. Publishers and subscribers are completely decoupled from and agnostic of each other.
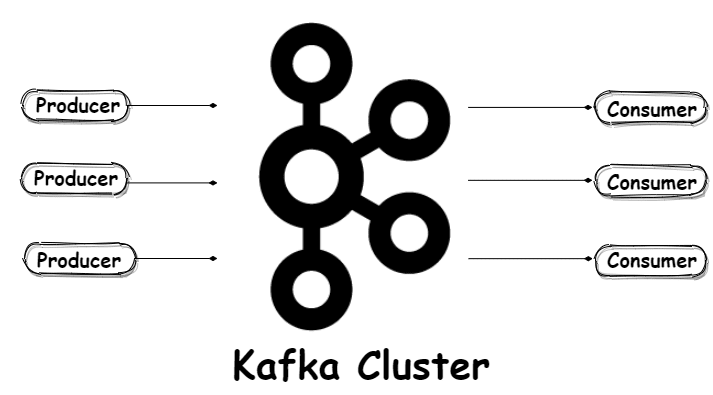
Kafka is designed after such system. Publishers (called Producers) send messages to Kafka, categorized as topics, subscribers (called Consumers) subscribe to one or more topics. Consumers receive the messages immediately they become available. (More on producers and consumers later in the series).
This design allows Kafka to scale well as we can add as many producers and consumers as we want without changing or adding complexity to the overall system design.
Commit log
At the heart of Kafka is the commit log. A commit log is a time-ordered, immutable and append only data structure. (Whatever data can be stored in and retrieved from is a data structure). Remember partitions? Well, each partition is actually a log. Do we want to add a message? No problem, it will get appended at the end of the log. Want to read a message? Still no problem, start from beginning of the log. Want to modify the message? Sorry, can’t do that, once written, messages are unchangeable. This makes sense, because once an event has happened in real-life, we can’t undo it.
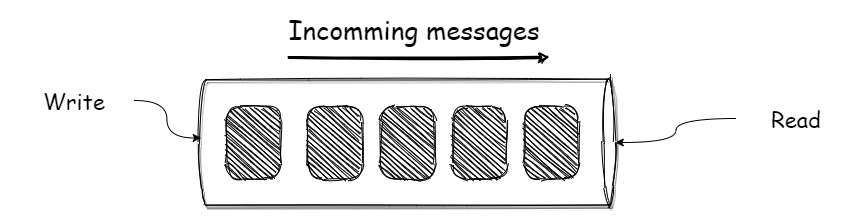
Once these messages have been written to the log, they are then persisted to local storage on the broker. This ensures durability because data is retained even after the broker shuts down. Also, the messages will be available for other consumers to consume, this is different from traditional messaging systems, where messages are only consumed once, then deleted.
Kafka has a configurable retention policy for messages in a log. Messages are retained for a particular period of time, after which they are deleted from storage to free up space. By default, messages are retained for seven days, but we can configure it to suit our need. For example, if we set the retention policy to thirty days instead, messages will be deleted thirty days from the day they were published, it does not matter if they have been consumed or not. We also have the option of configuring the retention policy by size, where messages in a log are deleted when they reach a certain size e.g. 1GB.
Replication
Replication is a fundamental design of Kafka that allows it to provide durability and high availability.
Remember, Kafka is a distributed system with multiple brokers, messages in brokers are organized into topics, and each topic is further partitioned. Replication is the process of copying these partitions to other brokers in the cluster, each partition can have multiple replicas. This is to avoid a single point of failure and to ensure that the data will always be available if a particular broker fails.
Kafka adopts a leader-follower model, each partition has a single replica assigned as leader of the partition, all produced messages go through the leader.
Follower replicas do not serve client requests except when configured otherwise, their main purpose is to copy messages written to the lead replica and stay up to date with it. Followers that are up to date with the leader are referred to in-sync replicas.
In a balanced cluster, the lead replica of each partition is spread across different brokers. When a lead replica goes offline, only in-sync replicas are eligible to become a leader, this is to avoid loss of data as a replica that is out of sync does not have the complete data.
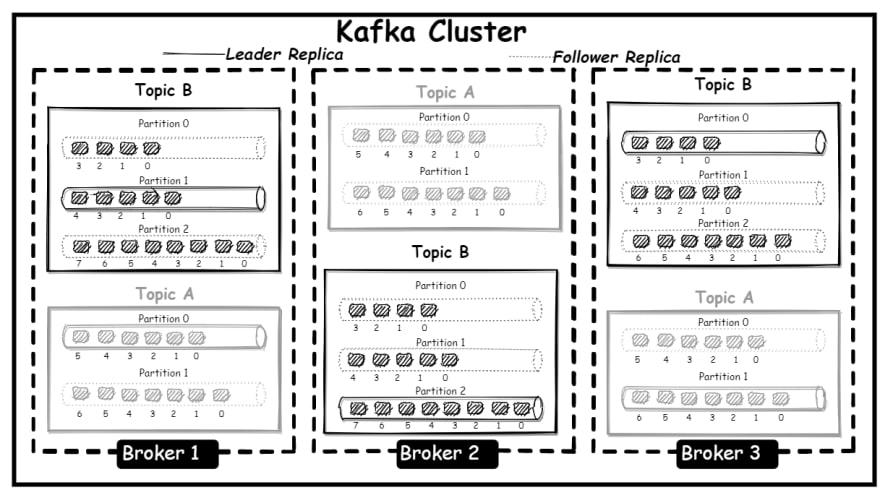
From the above image, the replica for Topic B Partition 2 on Broker 3 is out of sync with the lead replica on Broker 2, as such will not be eligible for leadership if the lead replica goes offline.
We enable the replication factor at the topic level, if we create a topic with three partitions and a replication factor of three, that means there will be three copies of each partition. We end up having a total of nine partitions (3 partitions x 3 replicas) for the topic. Note that the replication factor for a topic cannot be more than the number of brokers in the cluster.
In production, the number of replicas should not be less than two or more than four, the recommended number is three.
Bytes Only System
Kafka only works with bytes. Kafka receives messages as bytes, stores them as bytes, and when responding to a fetch request, returns messages as bytes. So, data stored in Kafka does not have a specific format or meaning to Kafka.
There are couple of advantages with this; bytes occupy less storage space, have faster input/output, and we can send any type of data from simple text to mp3 and videos. But it also adds another layer of complexity as we now have to convert these messages to bytes and from bytes in a process known as serialization and deserialization.
This is yet again the end of another segment.
Next, a look at those components that make up Kafka’s ecosystem.

Top comments (0)