Context
Interactive PDF documents are widely used in business and education, but manually filling them out can be a real challenge. The repetitive nature of this process and the risk of errors during manual data entry often lead to wasted time and frustration. Automation can be a game-changer, significantly reducing document processing time and minimizing errors.
Instafill.ai team aimed to address the pain points of users dealing with PDF forms and we asked ourselves three key questions:
- Are there existing products today that solve the problems of manually filling out such forms?
- How can we solve these problems, and what additional value would our potential user gain if alternative products already exist?
- Can the task of filling PDF forms be entirely delegated to artificial intelligence?
To be honest, the last question remains relevant even now. However, the rapid advancement of large language models allows us to confidently bet on reducing human involvement in monotonous PDF form filling to zero. This idea forms the foundation of the solution I will discuss further in this article.
Solution Architecture: From Reading PDFs to Filling Forms Using AI
Let’s get to the core. The main concept of the solution involves:
- Reading the PDF form — extracting text and form fields.
- Using an artificial intelligence model to analyze and populate the fields.
- Updating the PDF file with new values.
Overall, nothing too complicated, right? This can be implemented using any programming language, but we chose Python specifically because it’s flexible, versatile, and efficient for writing code and conducting experiments. After all, we constantly need to test new hypotheses and make quick decisions based on the results. By the end, you’ll also have a script ready to use on your PDF forms.
Implementation and Step-by-Step Instructions
1. Reading the PDF
The script starts by reading the PDF file to extract its text and form fields. The text from the PDF document provides the AI model with general information about the form and its purpose. This sets the context in which the AI model will operate to fill in the required fields.
def extract_pdf_text(pdf_bytes: bytes) -> str:
pdf_text = ''
pdf_document = fitz.open(PDF_EXT, pdf_bytes)
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
text_page = page.get_textpage()
pdf_text += text_page.extractText()
return pdf_text
Equally important is extracting as much information as possible about these fields and saving it in a format understandable to the AI model. This improves the quality of the output because the more context and details we provide to the AI, the higher the likelihood of generating the desired result. Large language models tend to always return some output, but the quality can be questionable. Our goal is to minimize the frequency of hallucinations.
def extract_pdf_fields(pdf_bytes: bytes) -> list[dict]:
form_fields = []
pdf_document = fitz.open(PDF_EXT, pdf_bytes)
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
widget_list = page.widgets()
if widget_list:
for widget in widget_list:
form_fields.append({
'name': widget.field_name,
'label': widget.field_label,
'type': widget.field_type_string,
'max_length': widget.text_maxlen
})
return form_fields
2. Delegating the Work to AI
Before using the AI to populate the form fields, the script generates a prompt. The quality of this prompt determines whether the "magic" happens. The prompt contains general instructions and accepts PDF components (extracted in the previous step) and unstructured data as parameters. This data is the source of information needed to fill the form. For simplicity, the script reads it from a text file, but in general, it could be any format: PDF, DOCX, JPG, etc.
def fill_fields_prompt(pdf_text: str, fields: list[dict], source_info: str) -> str:
return f"""
You are an automated PDF forms filler.
Your job is to fill the following form fields using the provided materials.
Field keys will tell you which values they expect:
{json.dumps(fields)}
Materials:
- Text extracted from the PDF form, delimited by <>:
<{pdf_text}>
- Source info attached by user, delimited by ##:
#{source_info}#
Output a JSON object with key-value pairs where:
- key is the 'name' of the field,
- value is the field value you assigned to it.
"""
We chose OpenAI and the GPT-4o model as the AI provider. It is sufficiently intelligent and fast. You can experiment with other providers and models, but remember to tailor the prompt for each LLM. Prompt engineering is critical at this stage. After the API call (shown below), we’ll have a dictionary of <field name>:<field value>, ready for the next step.
def call_openai(prompt: str, gpt_model: str = 'gpt-4o'):
response = openai_client.chat.completions.create(
model=gpt_model,
messages=[{'role': 'system', 'content': prompt}],
response_format={"type": "json_object"},
timeout=TIMEOUT,
temperature=0
)
response_data = response.choices[0].message.content.strip()
return json.loads(response_data)
3. Filling the PDF
The final touch is populating the PDF with the values the AI has generated for the form fields.
def fill_pdf_fields(pdf_bytes: bytes, field_values: dict) -> io.BytesIO:
pdf_document = fitz.open(PDF_EXT, pdf_bytes)
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
widget_list = page.widgets()
if widget_list:
for widget in widget_list:
field_name = widget.field_name
if field_name in field_values:
widget.field_value = field_values[field_name]
widget.update()
output_stream = io.BytesIO()
pdf_document.save(output_stream)
output_stream.seek(0)
return output_stream
Testing the Solution
First and foremost, our product targets a U.S. audience, so as an example, I used the IRS W-9 form — a common document in the United States used to collect taxpayer identification information. This form is often required for freelancing, contractual agreements, and various financial transactions. Given its widespread use, it serves as an ideal example to demonstrate how our solution works.
For filling out this form, we used the following test data:
1. personal info
john smith
222 Victory St, 125
San Francisco, CA, 94111
2. business info
BOTMAKERS, LLC
has foreign partners
account numbers: 1234567890, 0987654321
tin: 123456789
3. requester
jane smith
87 Independence St
Now for the most interesting part: let’s look at the filled-out form and analyze the quality of the solution’s work.
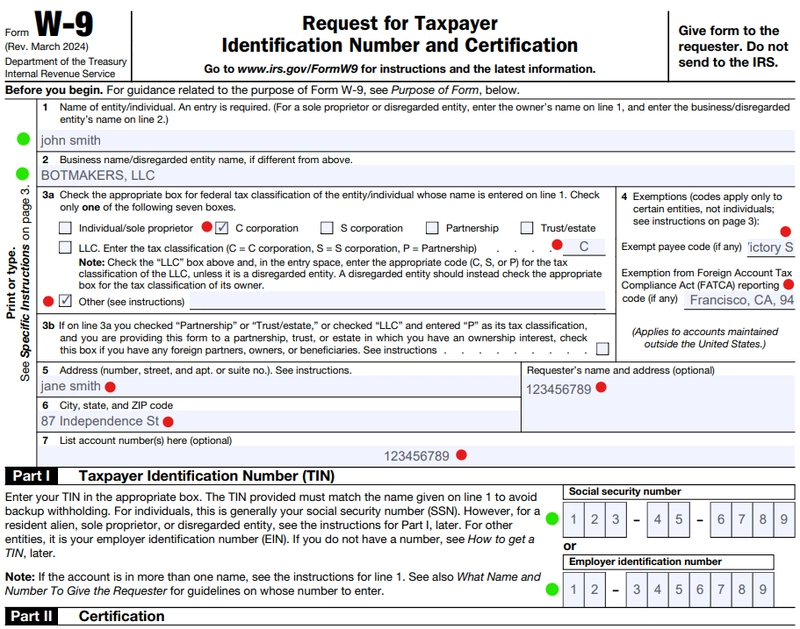
We see that all fields are populated. Ignoring quality for now, our initial conclusion is that the generative AI handled its task. Let’s dig deeper into what it generated: there are clear successes and failures. Some fields (highlighted in green) are filled correctly, while others (highlighted in red) look like someone typed them blindly. Let’s explore why this happened. Here are some of the fields extracted from the PDF form (only a subset is shown; others follow the same pattern):
{
"name" : "topmostSubform[0].Page1[0].Boxes3a-b_ReadOrder[0].c1_2[0]",
"label" : null,
"type" : "CheckBox",
"max_length" : 0
},
{
"name" : "topmostSubform[0].Page1[0].f1_05[0]",
"label" : null,
"type" : "Text",
"max_length" : 0
},
{
"name" : "topmostSubform[0].Page1[0].f1_06[0]",
"label" : null,
"type" : "Text",
"max_length" : 0
},
{
"name" : "topmostSubform[0].Page1[0].Address_ReadOrder[0].f1_07[0]",
"label" : null,
"type" : "Text",
"max_length" : 0
}
The field name is a critical parameter for the AI when filling in values. However, in this case, we face a problem: the names lack sufficient information to unambiguously determine the expected values for these fields. This explains the unsatisfactory results.
Let’s try filling out another form — TR-205 (Request for Trial by Written Declaration). This document is used in California to submit a request for a trial by written declaration. It allows drivers to contest traffic violations without appearing in court.
We used the following test data to fill it out:
Court:
SUPERIOR COURT OF CALIFORNIA
100 NORTH STATE STREET
UKIAH CA 95482
BRANCH #23480
Citation: KV19133
Case: 231N07977
Defendant:
John Smith
1234 Main Street, Apt. 101
Due date: 07/21/24
Bail amount: $441
Date mailed: 06/21/24
Evidence:
- photographs (5)
- witness testimony
Statement of facts:
I increased my speed to avoid a possible traffic accident due to a truck in the middle of the road.
Today: 06/21/24
And here’s the result:
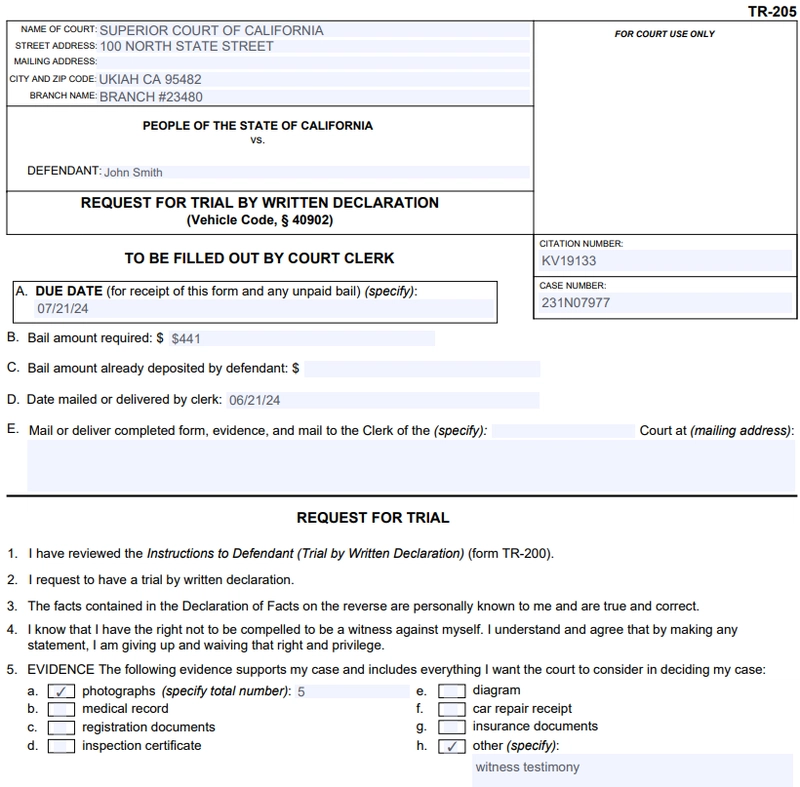
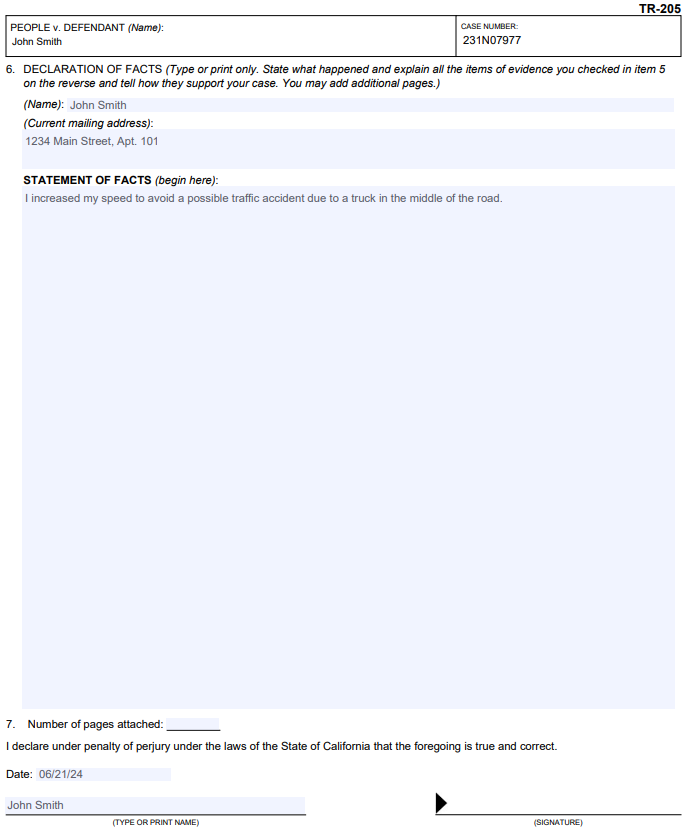
Notice that the script performed better with this form. All provided information landed in the “correct” fields. As you might guess, the difference lies in how these fields are stored in the PDF. Compare them to the previous example:
{
"name" : "TR-205[0].Page1[0].P1Caption[0].CitationNumber[0].CitationNumber[0]",
"label" : "CITATION NUMBER:",
"type" : "Text",
"max_length" : 0
},
{
"name" : "TR-205[0].Page1[0].P1Caption[0].CaseNumber[0].CaseNumber[0]",
"label" : "CASE NUMBER:",
"type" : "Text",
"max_length" : 0
}
Thus, we discovered that the quality of form filling heavily depends on the internal structure of the input PDF form. How the form fields are stored directly impacts the final result. This remains one of the key challenges we still don’t have a complete solution for.
Conclusion
Let’s summarize. In this article, we explored how AI can automate filling PDF forms, using the IRS W-9 and TR-205 as examples. The core idea was to demonstrate how manual labor and errors can be reduced by automating document processing. All materials used in this article, including the original Python code, are available on GitHub.
Feel free to leave comments, share your thoughts, or discuss your own experiences. If you have questions or want to explore any aspects of this article further, you are welcome!

Top comments (1)
Thanks for the guide!