When one of the daily challenges came through my feed, I did not want to solve the problem but I thought it might be interesting to check performance on the different implementations.
I keep needing to start by saying, this is all written in D and only uses the language because of the source of style.
This ended up being a bigger exercise in figuring out gnu plotting and later found out the D library I originally wanted to use was called ggplotd.
 JesseKPhillips
/
devto-challenge259-dupencoder
JesseKPhillips
/
devto-challenge259-dupencoder
An attempt to capture performance with different implementation approaches for a Challenge
Dev.to has a daily challenge and I happened upon the Duplicate Encoder #259 for 2020
I didn't really want to solve the challenge per se, so instead I took the top comments for implementation and wrote them in D Lang.
For clarity these are all implemented in D and do not reflect the language performance that the implementation is based on.
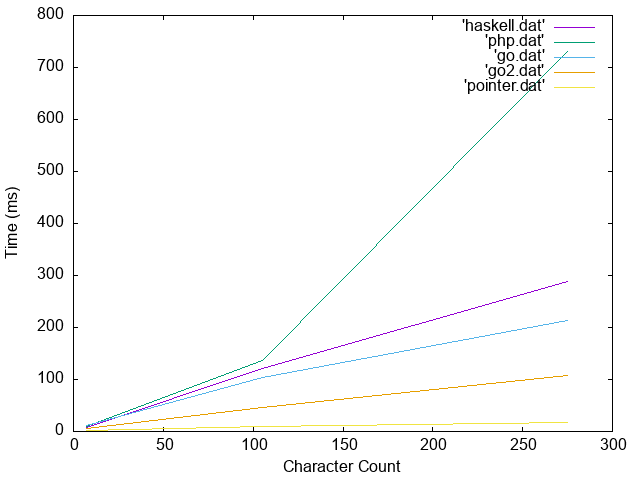
The "Haskell" implementation utilizes a range based map/filter approach to detecting duplicates.
The "PHP" implementation utilizes a nested loop apporach to intentify that the character occurs again.
The "Pointer" implementation was just something I wanted to try. It duplicates the array so it is mutable after which point it does not loop over the arry twice and instead stores pointers to the location of the same character. It takes quite a bit for this approach to see any performance gain.
The Haskell implementation was modified to put its…
Anyway, I ended up focusing on the Haskell implementation. This is because it originally had the worst performance and I already knew the biggest offending cause. Of all the implementations it had the best chance of working with unicode where ever other would clearly fail.

Top comments (0)