Rails — Enhancement application performance using cache on views

Image with sustainability's 3Rs: reuse, reduce and recycle
Versão em português do post no link https://medium.com/sumone-technical-blog/rails-melhorando-a-performance-das-suas-views-com-cache-c4e318a7df45
When we talk about application performance, cache is one of the most common approach used. Thinking about cache can be similar to environment sustainability 3R's rule: we reduce the use of resources and application load and requests, reusing resources previously processed and saved, while we need to recycle those resources from time to time to maintain all informations relevant to users and does not show dated and old informations.
Talking about rails applications, cache is not a new topic. It is there since the beginning of the framework, but it is really common to made mistakes if we do not really understand how to use and how to recycle it.
One thing that I really like in rails is the possibility to use cache directly in the rails views, caching erb generated html. This approach is also known as russian doll caching.
What is russian doll caching?

A Russian Doll with all its "children" side by side
The rails guides are a great source of informations about cache, and has a exclusive topic about this approach, where you can understand in details and see examples of how to use. Being brief about this, it is a chained cache use in views, where you use cache in a smaller view fragment inside another cached view fragment. The name is inspired on old Russian dolls, like the above image.
Using cache in views
We can use the helper method cache directly in the rails views. This method, as we can see in the documentation, receive from 1 to 2 params and a code block. The first and required parameter is an object, the second and optional one is an options hash. The code block passed is what will be saved in the cache after it is processed and generate a html fragment. There are other two methods that you can use directly in views, where you can pass a conditional parameter: cache_if (doc)) and cache_unless (doc).
For example, let's imagine that we need to build a page with authors list that contain the name, quantity of books and last book publication date for each author. Just to make easier this exercise, let's not worry about pagination for now.
https://medium.com/media/404d37576ca6bc5b1a5f95536bb066ad/href
Let's use the code above to understand how rails will deal and process cache. When the page is rendering, it will first check if all block passed to cache is already processed and saved in cache. If it is found in cache store, it will not process the block again, using the previous processed and generated html that is saved in the cache store. Otherwise, it will process the block, generate a new html fragment and save it on cache for future uses.
Cache invalidations
One of the most difficult things about cache is to correctly invalidate it. We can forget to invalidate a cache key. When this happens, we will see dated and invalid informations. The simplest way to invalidate some cache is defining a expiration date.
Using the optional hash param, you can define the expiration date passing a timestamp to expires_in key when calling the cache method, as we can see in the example below:
https://medium.com/media/7095a777bff2be04afc1037ae80ed35e/href
This way, we assure that this page will be at most 1 hour delay from fresh informations. This will be enough in some scenarios, but what if we want to assure that the informations are always up to date? What if it is important to have the page always showing fresh informations?
To be able to do this, we must really understand how rails define the cache key when we call cache directly in the views. To define the cache key, rails will use at least three informations: first something that can be identified uniquely the object passed; another information that identifies how fresh the cache is, in other words, a timestamp that shows when the most recent information of the object passed was saved; lastly, one information that identifies uniquely the code block passed to cache method.
In the authors list example used in the above paragraphs, this will work with rails generating a identifier for the authors query and getting the count result and the maximum value for the updated_at column for the authors queried. Besides that, rails will generate a hash to identify the code block passed. We can see all of this in the image below, in the line that shows the output of read fragment action. It shows a string containing a path to the partial used, followed by the code block hash identifier and the query identifier and authors' count, 4219, and maximum updated_at, 20210132190705856638, result.

Console image showing rails console output with cache information key
Using all those informations, rails makes a lot easier for us to deal with cache invalidation. Since it uses authors count in the cache key, if another author is created in the database, it will generate a new key and invalidate the old key. The same works for any update processed in any author in the database, that will update the updated_at column and automatically invalidate the old cache key. Lastly, using a query and code block hash identifiers make possible that if we change the query or change something in the erb fragment being cached, it will get the updated query/erb fragment and generate a new cache with up to date informations.
Cache inside cache — using the russian doll approach
In this authors list page example above, we saw how to have a cache that work for the entire page always. If a single author has its name changed, the entire page cache will be invalidated and all the list will be reloaded and generated again. If you have a really large list in the page, it can be an issue.
Russian doll caching is a really good and useful option to solve this issue. Using this approach, we can cache not only the authors list, but cache each author fragment too.
https://medium.com/media/97c4264a5743afd4a0f970b574e4f0f2/href
It works the same we saw before with the authors list cache. The difference is that this time rails will follow those steps for each author fragment, generating a cache key for each author fragment, using an identifier hash for each code block and the author's id and updated_at informations.
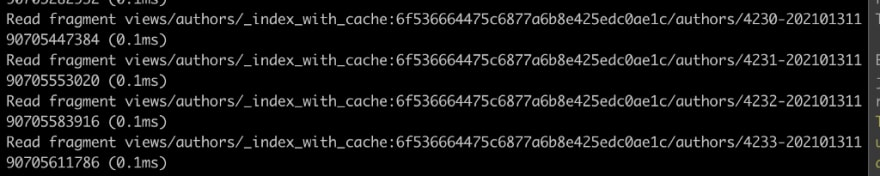
Console image showing rails console output with cache information key for each minor author fragment
In the image above, we can see that rails will perform the read fragment action for each fragment. We can see that the cache key pattern is the same as used on authors list cache — code block identifier, object identifier and a timestamp.
With this change, the page will now be loaded and processed in three possible scenarios:
- Using the cache for the entire page list if no author was change
- Using the fragments cache and processing one or multiples author fragment, for each author that has new informations, not saved previously in the cache. In this case, it will generate a new cache value for the entire list and save it to be used in the next requests
- Processing all the fragments and the list block and generating a cache for each of those, saving it to be used later.
Caching with multiple model informations
All the examples used in this post until now can led us to assume that rails take care of everything, and we do not need to worry with anything then just use the cache and be happy.
That is partly true. Rails sure take care of lot of things that make a lot easier to use cache in rails applications views. But it is not able to deal with one situation alone: caching multiple models together.
Let's go back to our authors list example. In this page, we show the author's name, books count and last published book date. The last two informations are not from authors table, they are related to the books table. In reality, if we create another book for some author, the page will not show the books count and last published date correctly, because it will not know about this new book we have just added. This happens because the action of add a new book to the database does not change any information used to generate the cache keys used on the page. It does not change the code block neither the authors query, neither change the authors query count or the updated_at column of any author.
There are two approaches that we can use. The simplest one is to pass a list of objects as first parameter to cache method. This list should contain all objects that can impact the cache, that has informations used in the code block passed.
https://medium.com/media/4e960030879fdf15cc1ec4081e91840b/href
Doing this, rails will add information about all objects in that list to the cache key, since the object being cached now is the list, not just an author, as we can see below.
![]()
We need to take careful about this approach, because every object that we pass increase the rails needed queries to check and load the cache. It generates more complex cache keys too.
Another approach, that personally I like and use more, is to "update" the author when one of his books is updated, created or deleted. We can solve this easy with rails too, we just need to make sure that we update the correspondent author updated_at column when some of his books has any change. We can do this adding the touch: true parameter to books belongs_to :author relationship in the book's model, like below:
https://medium.com/media/1524f7946290ecc9efe4f8e66ea3d498/href
The difference of this is that we add more load to the books CRUD actions In the first approach, we are adding more load and complexity to the page loading, where we want to increase performance for better user experience.
Conclusion
Using cache is a really useful way to increase performance in rails applications. Rails make it a lot easier to be used with its helpers and rules for cache keys. In most cases, you just need to make sure that you do not use methods that skip model callbacks and validations(like update_column) and all rails will take care of all. In some cases using multiple models in the same fragment cache, you can pass both objects to cache method as a list, or, what I prefer and think it is better, you can "update" the relationship model using belongs_to with touch: true option.
The most important thing to know when using cache is to understand the cache keys and how to generate this correcly.
More examples
I created a project that I used as based to write this post, there you can find more examples and scenarios. The scenarios always have a version with cache and another without, so you can compare the difference in the erb file. To run locally the project and run with cache version pages, just set the env var CACHE_ON to true.
Other resources and links
Caching with Rails: An Overview - Ruby on Rails Guides
https://blog.appsignal.com/2018/04/03/russian-doll-caching-in-rails.html
Russian Doll Caching with Rails 5 (Example) | GoRails - GoRails

Top comments (0)