Problem Situation 1
While running a post service, a user reported a post at some point.
By the time it was checked, the post had already been deleted, leaving no way to verify whether the user's claim was true.
Fortunately, modern developers use a technique called soft-delete to solve this problem.
Instead of actually deleting data, they record the deletion date and make the post invisible if the date exists.
By checking the list of deleted data, the reported post was found, and the issue was resolved.
However...
Problem Situation 2
One day, a user reported a post again.
Once again, the post had already been deleted, so an attempt was made to check the deleted content, but surprisingly, the post was empty.
Did the user lie? Checking the last modified time of the post, it appeared that something had been edited before deletion.
It turns out that the post author was a developer (!!!).
Before deleting the post, they edited the content, replacing it with spaces.
Since a database is just a table with rows and columns like an Excel sheet, once modified, the previous content is lost.
So how can this issue be solved?
Implementing a Snapshot Structure
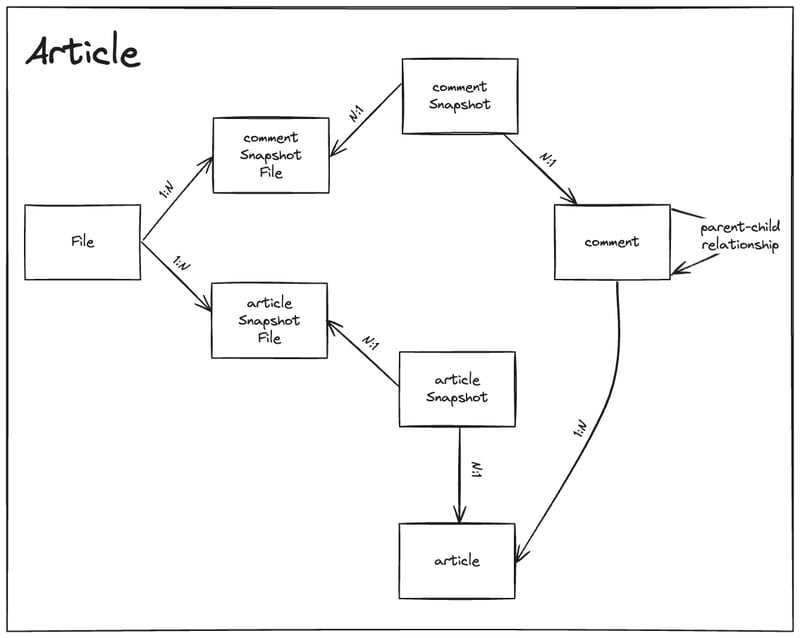
Article ERD
To solve this issue, there is a concept called snapshots.
Developers often associate snapshots with replication, but what I mean here is not history.
Rather than thinking of it as a past record, consider it as existing data that varies based on time.
When watching a streaming video on YouTube, is the footage from one second ago a past video while the current frame is the present video?
The data exists according to the chosen point in time—it is not a past artifact.
To understand this concept, let's create a snapshot table.
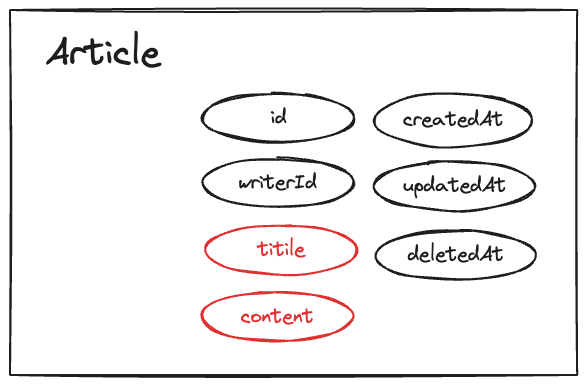
Suppose we have an Article table with the following seven columns:
- id
- writerId
- title
- content
- createdAt
- updatedAt
- deletedAt
Among these, the mutable columns are the title and content.
To create a snapshot structure, we extract these mutable columns into a separate table.
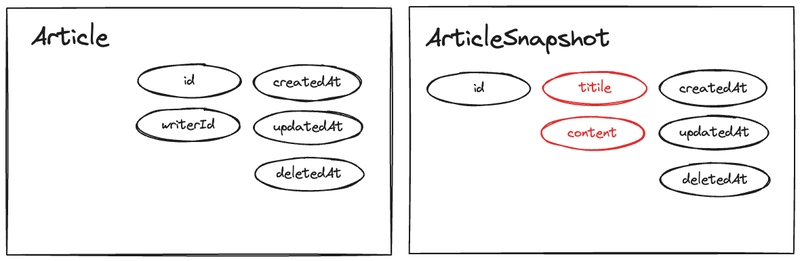
We now have an ArticleSnapshot table that stores these mutable columns.
The snapshots are stored separately, making Article hold a 1:N relationship with snapshots.
- Instead of updating posts, we now create new snapshots—eliminating the need for DB update queries.
- The latest snapshot represents the currently visible version of the post.
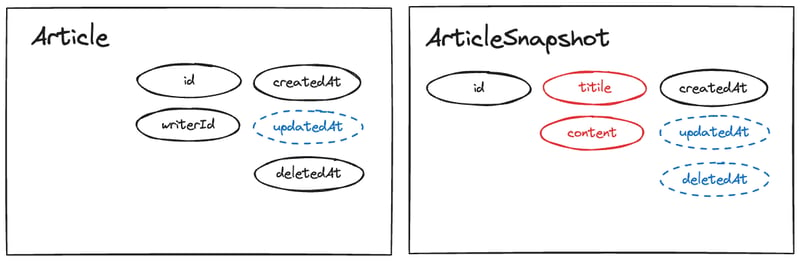
Lastly, we remove unnecessary columns.
Since updates no longer exist, updatedAt is unnecessary in Article.
Similarly, updatedAt and deletedAt are unnecessary in ArticleSnapshot.
If a post is modified, a new snapshot is created; if deleted, deletedAt is recorded in Article.
With this structure, we can track changes and even restore previous versions when needed.
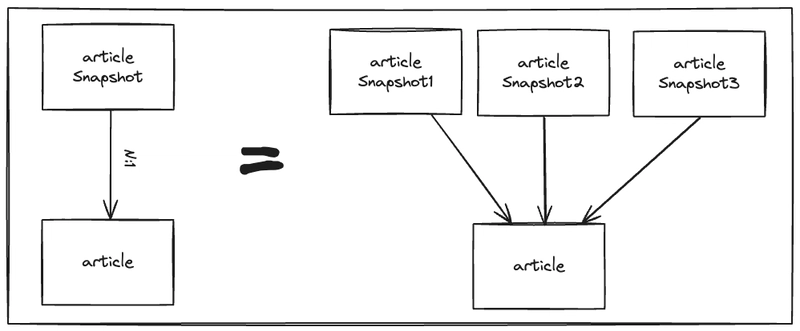
Both images above represent the same concept.
The latest snapshot is the currently visible version of the post.
Now, since a snapshot is created for every modification, the problems we previously encountered can be resolved!
Another Use Case: Products & Shopping Carts
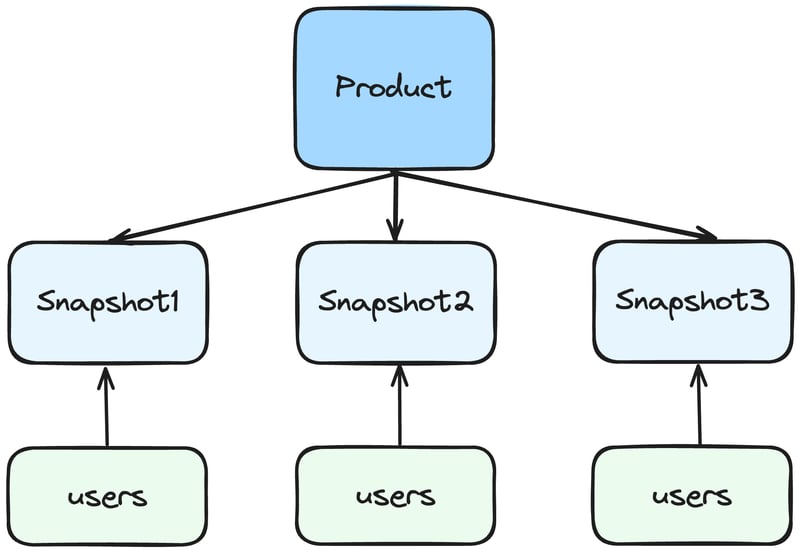
Snapshots can also be applied to products.
Whenever a product's name changes, a new snapshot is created.
If green-colored users represent those who added a product to their cart, we can gain interesting insights.
For example, how does the number of people adding a product to their cart change based on name modifications?
While users will always see the latest name, administrators may not need to.
This helps analyze whether name changes affect sales, which could be useful for vendors in a marketplace.
That's why snapshots are not past data but actively used data!
Benefits of Using Snapshots
Whenever a post is modified, a new snapshot is created, and the latest snapshot represents the current state.
But as mentioned earlier, previous snapshots are still useful:
- To verify reported posts by checking their original content before deletion.
- To track post contents at the time comments were made.
- To allow users to restore a post to a previous version.
- To analyze whether post modifications impact SEO positively or negatively.
In real-world scenarios, data rarely exists as a single node without historical tracking.
For example, if someone comments on a post and the author later modifies it, the comment might seem out of place.
What if a dispute arises, and someone requests the original post content at the time of the argument?
Again, snapshots are not past data but active, useful data.
Whether in posts, products, or shopping carts, snapshots are essential for understanding historical context and performing analytics.
Without a snapshot structure, companies may have to rely on data lakes, which can be extremely expensive.
Conclusion: My Company Doesn't Use Snapshots
Yes, most companies don’t use them, and they probably won’t.
I only encountered this concept at my current job, and I believe it's rare for the following reasons:
- Small companies don't prioritize data analytics, and few people understand its value.
- Backend developers don’t see the need to retain past data.
- Many think soft-delete is enough.
- Startups are focused on immediate problem-solving rather than long-term planning.
- This leads to simply adding columns per requirement.
- If leadership doesn’t value data, developers who spend time on design may be seen as slow.
However, as companies grow, data becomes increasingly important.
At some point, customers will start requesting historical data.
How will you respond when they ask for it?
Without snapshots, companies may end up adopting expensive data lake solutions.
Wouldn’t it be better to avoid that cost altogether?
If you enjoyed this article, I’ll write another one about designing commerce or marketing ERDs!

Top comments (0)