I'm writing this post today while waiting for my oldest daughter to start her high school track and field event. I'm watching these talented athletes push their bodies well beyond anything I can personally relate to and in between rain showers and wind gusts there are meet records, and hearts, broken. Since these are High School student athletes, my mind wanders to what their future holds. Will their athletic abilities allow them to compete at a collegiate level, or will high school be the glory days of their running, jumping, and throwing experience? Is a college athletic scholarship in their future? Hmmm.... a recruiting website for my daughter's Javelin skills would be interesting.
While building a site just for her would likely include static performance data, the data geek side of me wonders how one would model track and field participation data inside a database. As is often the case for those that have been around data for a while, we start to think of the tables we would need. Clearly for our sample here we would need an athlete table, probably an event table with a list of possible events, another one for the meet name, just to name a few. And we haven't even gotten into data normalization yet, right? We should likely have a high_school table to maintain that information, a weather table to keep track of the rain and wind values, and many more. Here's a quick visualization of what our database might look like in a relational database management system (RDBMS) world.

We would need all of these tables to be able to pull up data in our application to see which event Jane Doe competed in at a specific meet and JOIN it with all the other tables to be able to generate some useful information for a college athletic recruiter to see. That seems like a lot of joins (computational time) to grab a relatively small percentage of the data from each row in our tables. For example, in the high_school table, we likely don't need to display the school's address and phone number on a student's site itself, but it would be nice to be able to provide a link to that information should a coach want to contact the school. We still, however, need to do the JOINs to get the information. Granted for those of us with some experience working with RDBMS technology, this example isn't overly complicated and the SQL necessary to come up with the data and the specific JOIN statements aren't horrendous, but we are still asking for some computational power to be expended to do the joins and retrieve the data.
What if there was another way to model our data? What if we could model our data in a way that was more application specific and suited our needs for showing off an athlete's skills to potential recruiters? Further, what if we could do that and get data back from our database without JOIN operations and still get all the data we need for our application at once? Sounds pretty amazing, yes? Well, that is precisely where we can use NoSQL and a Document Model for our data. Let's have a look at how we might model our athlete's data in MongoDB.
To start with, in the document model, we can think about the information our application needs, things like athlete name, event, time/distance accomplished for that event, when and where the event took place, what high school the athlete is from, etc.
Our document, therefore, could be designed to hold all of the data our application would need. We could have our document look like:

Something might seem familiar about this format too. It is modeled in JSON which, at least for me, is a much friendly format that table upon table. It also allows us to develop quickly. What happens when our student decides to do another sport in the fall and winter? In our RDMS model that will involve more tables and joins. In our document model we can simply add to our document another sport name, event, and statistic we want to track.
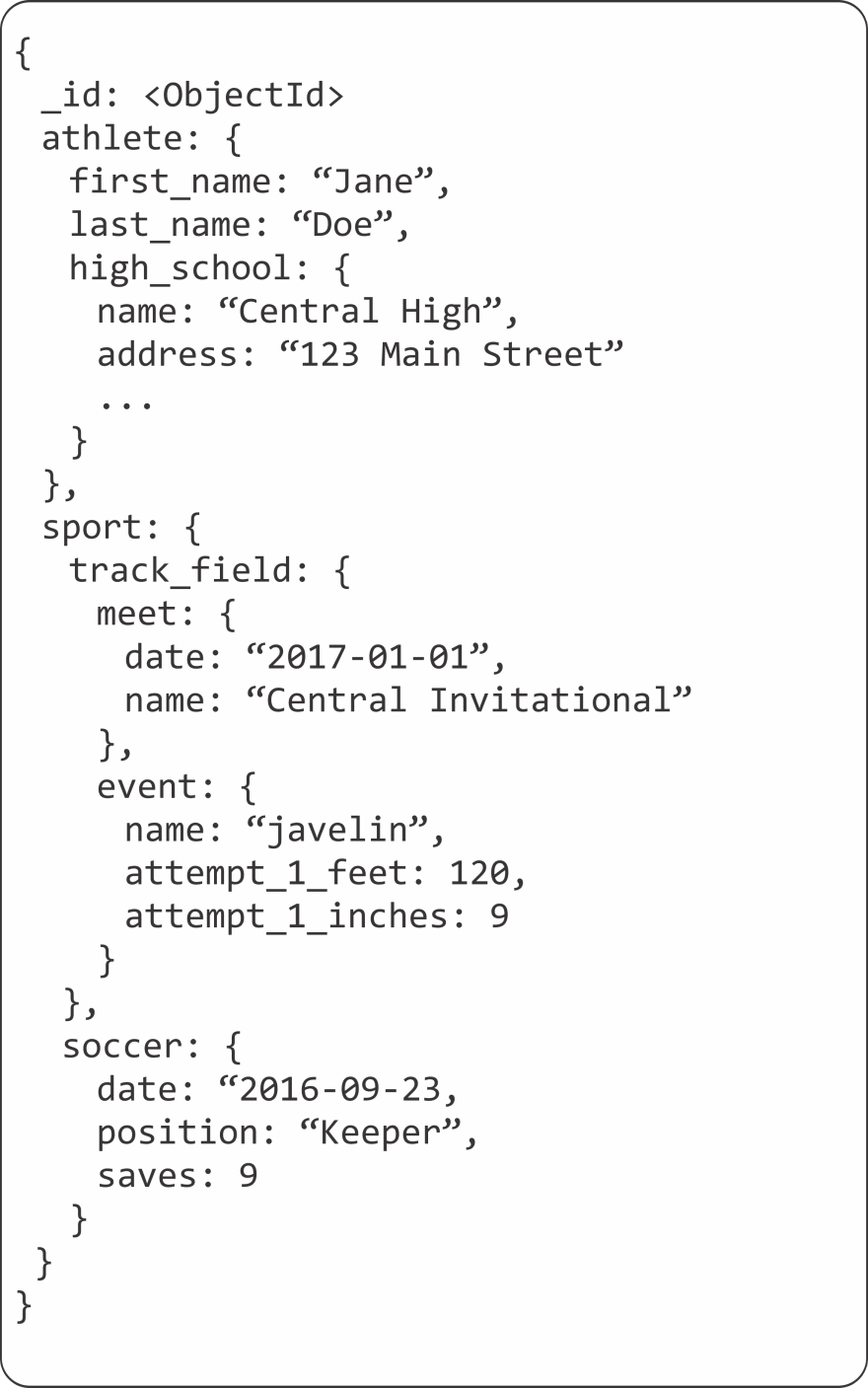
Another great feature of our document model is that we don't need to be concerned with NULL values. If an athlete doesn't participate in the long jump, there isn't a reason to maintain a value for that. If they suddenly do participate in long jump at a given meet, we can record that data as well. Similarly, if Jane and Kendra are involved in different sports, it is absolutely okay for their schemas to look and different information. This is the concept of flexible schemaand can be very powerful.
There are several reasons why using a document model is becoming more and more popular. Some of them are:
- The large amounts of data many applications generate combined with changing data types.
- Rapid development times and agile development practices often require quick iterations of a product. A flexible schema in a document data model easily allows for this.
- Gone are the days in which accessing data is from a single device to a single audience. Data needs to be always on and globally accessible in today's world, requiring data stores to be able to scale accordingly and provide application specific data.
For all these reasons, along with the ease and speed of development, the document data model shouldn't be discounted for your next project. In fact, I may just use such a model for my daughter's recruiting site. After a long day at the track meet she threw her second best throw of the javelin ever at 92' 6". Perhaps not NCAA Division I bound, but maybe with a web application backed with a document model a college somewhere will notice her.
Follow me on Twitter @kenwalger to get the latest updates on my postings, or see the original post on my blog.

Top comments (0)