
TL:DR
- Pyinstrument is a call stack sampling profiler with low overhead to find out time spent in your Django application.
- QueryCount is a simplistic ORM query count middleware that counts the number of ORM queries, finds duplicate queries, and prints them in the terminal.
- Django Silk is an extensive Django profiler that records the entire execution, SQL queries, source of origin, and persists the recordings. The complete Django profiler.
🔬 What's Profiling? 🔬
Profiling is a dynamic program analysis that measures a running program's time and(or) memory consumption. The profiler can instrument the entire running program or record samples for a fixed duration of time.
🚀 Why Profile Django code? 🚀
The Django application can consume more than expected memory or time. The blog post will focus on profiling performance. Some of the reasons why Django App can be slow
- ORM could be making N+1 select queries. Example: The child model fetching parent models.
- The custom python code can be making DB queries inside a for-loop.
- The service or utility function may be making an HTTP or network call that consumes a lot of time.
Application Setup
Here is a sample book counter application that contains three models - Book, Author, and Shelf. A shelf contains a list of books. A book has many authors.
Models
# book/models.py
from django.contrib.auth.models import User
from django.db import models
class Author(models.Model):
first_name = models.CharField(max_length=255, blank=False, null=False)
middle_name = models.CharField(max_length=255, blank=True, null=True,
default='')
last_name = models.CharField(max_length=255, blank=True, null=True,
default='')
profile_photo = models.URLField(default='', blank=True, null=True)
class Book(models.Model):
name = models.CharField(max_length=255, blank=False, null=False)
cover_photo = models.URLField(default='', blank=True, null=True)
language = models.CharField(max_length=255, blank=True, null=False)
#shelf/models.py
from django.db import models
# Create your models here.
from book.models import Book
class Shelf(models.Model):
name = models.CharField(max_length=255, unique=True,
db_index=True, null=False, blank=False)
books = models.ManyToManyField(Book, related_name="shelves")
Views
#shelf/views.py
class ShelfViewSet(viewsets.ViewSet):
http_method_names = ["get"]
queryset = Shelf.objects.all()
def list(self, request):
name = request.GET.get('name')
qs = self.queryset
if name:
qs = qs.filter(name=name)
data = ShelfSerializer(qs, many=True).data
return Response(data)
Serializers
#book/serializers.py
from rest_framework import serializers
from book.models import Author, Book
class AuthorSerializer(serializers.ModelSerializer):
class Meta:
model = Author
fields = ("first_name", "middle_name", "last_name", "profile_photo")
class BookSerializer(serializers.ModelSerializer):
authors = AuthorSerializer(many=True)
class Meta:
model = Book
fields = ("name", "cover_photo", "language", "authors")
#shelf/serializers.py
from rest_framework import serializers
from shelf.models import Shelf
from book.serializers import BookSerializer
import time
classic_books = ['War And Peace', 'Lolita', 'The Stranger']
class ShelfSerializer(serializers.ModelSerializer):
books = BookSerializer(many=True)
class Meta:
model = Shelf
fields = ("books", "name")
def to_representation(self, obj):
book = super().to_representation(obj)
if book['name'] in classic_books:
book['is_classic'] = True
else:
book['is_classic'] = False
time.sleep(1)
return book
The application has an endpoint /shelf/ that returns all the shelves along with books and authors using DRF model serializer.
🚆 Pyinstrument 🚆

Pyinstrument is a call stack Python profiler to find performance bottlenecks in your Python programs. It doesn't track every function call but samples the call stack every one millisecond. So it's a statistical profiler(not tracer), and it may lead to optimizing the wrong part of the program.
Since the profiler records the call stack, every fixed interval(can be configured to lower value too, say 1ns) has a low overhead.
Profiling time = program execution time + profiler recording time
If the program takes 0.33s to run, pyinstrument profiling takes 0.43s (30% extra) , cProfile takes 0.61s (84% extra).
Pyinstrument is a Python profiler that offers a Django middleware to record the profiling.
How to use it?
- Pyinstrument middleware records the request-response time. The middleware class goes into
MIDDLEWARElist variable.MIDDLEWARE+=[ 'pyinstrument.middleware.ProfilerMiddleware']. - The profiler stores the data in the configured directory mentioned in setting file. The profiler generates profile data for every request. The
PYINSTRUMENT_PROFILE_DIRcontains a directory that stores the profile data.
Output

By default, pyinstrument produces HTML profile information.
The right corner contains the metadata.
-
- SAMPLES - number of samples collected during the execution.
- DURATION - Total duration of the profiling.
The tree structure captures the flow of the code along with the time spent.
Each line is a frame that contains the duration, function/method name, file path, and line number.
data = ShelfSerializer(qs, many=True).data in the views, took 2.09 seconds.
The profiler auto hides any standard library and third-party calls to provide a brief overview of the program call graph.
From the profile,
sleepfunction inside the serializer takes most of the time.
Upside
- Fast and easy to use.
- Requires no code modification other than configuring
settings variables. - Less overhead to measure performance.
Downside
- The library can only collect Python code and not SQL queries executed during the request-response cycle.
- Since the library samples the call stack every one millisecond, there can be false positives. It's possible to configure the sample rate.
🧮 Django Query Count 🧮
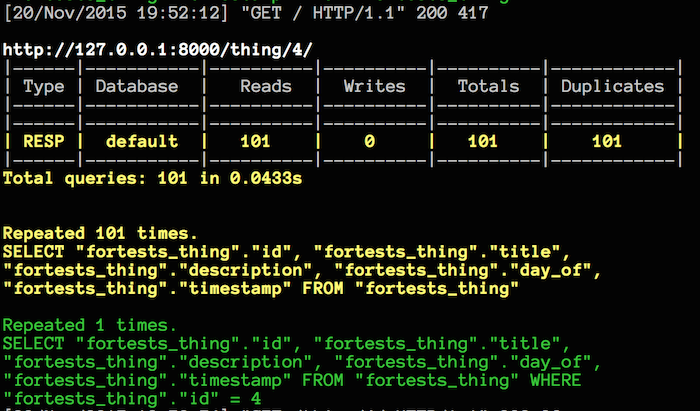
Django QueryCount is a middleware that prints the number of database queries made during the request processing.
How to use it?
Add
querycount.middleware.QueryCountMiddlewareto theMIDDLEWAREsettings variable.The middleware supports printing duplicate queries. Following are some extra settings options.
QUERYCOUNT = {
'THRESHOLDS': {
'MEDIUM': 50,
'HIGH': 200,
'MIN_TIME_TO_LOG':0,
'MIN_QUERY_COUNT_TO_LOG':0
},
'IGNORE_REQUEST_PATTERNS': [],
'IGNORE_SQL_PATTERNS': [],
'DISPLAY_DUPLICATES': True,
'RESPONSE_HEADER': 'X-DjangoQueryCount-Count'
}
Ouptut
# output in the server console
[17/Oct/2021 11:05:43] "GET /shelf/ HTTP/1.1" 200 1031
http://localhost:8000/shelf/
|------|-----------|----------|----------|----------|------------|
| Type | Database | Reads | Writes | Totals | Duplicates |
|------|-----------|----------|----------|----------|------------|
| RESP | default | 8 | 0 | 8 | 1 |
|------|-----------|----------|----------|----------|------------|
Total queries: 8 in 2.0803s
Repeated 1 times.
SELECT "book_book"."id", "book_book"."name",
"book_book"."cover_photo", "book_book"."language" FROM "book_book"
INNER JOIN "shelf_shelf_books" ON ("book_book"."id" =
"shelf_shelf_books"."book_id") WHERE "shelf_shelf_books"."shelf_id" =
1
Repeated 1 times.
SELECT "shelf_shelf"."id", "shelf_shelf"."name" FROM "shelf_shelf"
# output in the client
$http http://localhost:8000/shelf/ --header
HTTP/1.1 200 OK
Allow: GET
Content-Length: 1031
Content-Type: application/json
Date: Sun, 17 Oct 2021 11:05:43 GMT
Referrer-Policy: same-origin
Server: WSGIServer/0.2 CPython/3.9.7
Vary: Accept, Cookie
X-Content-Type-Options: nosniff
X-DjangoQueryCount-Count: 8
X-Frame-Options: DENY
- The middleware records the total number of SQL queries made and prints it in a tabular form in the terminal.
- The table contains the total number of reads, total number of writes, total queries, and total duplicates. The number of duplicates is a good indicator of N + 1 select queries.
- When DISPLAY_DUPLICATES is True, the middleware prints the duplicate query.
Upside
- Simple to use.
- Fast and accurate.
- Low overhead to find out the SQL queries.
Downside
- Simple, hence hard to find the origin of the SQL queries.
- No option to print all the SQL queries.
🔥 Django Silk 🔥

Silk is a live profiling and inspection tool for the Django framework. Silk intercepts and stores HTTP requests and database queries before presenting them in a user interface for further inspection.
Installation
pip install git+https://github.com/jazzband/django-silk.git#egg=django-silk
The latest PyPI version doesn't support Django 3.2.
How to use it?
- Add
'silk.middleware.SilkyMiddleware'toMIDDLEWAREsettings variable. - Add
silktoINSTALLED_APPSsettings variable. - Add silk endpoints to url patterns.
urlpatterns += [url(r'^silk/', include('silk.urls', namespace='silk'))]. - Run
migrateto create tables.python manage.py migrate. - Run
collectstaticto collect static files,python manage.py collectstatic.
Output
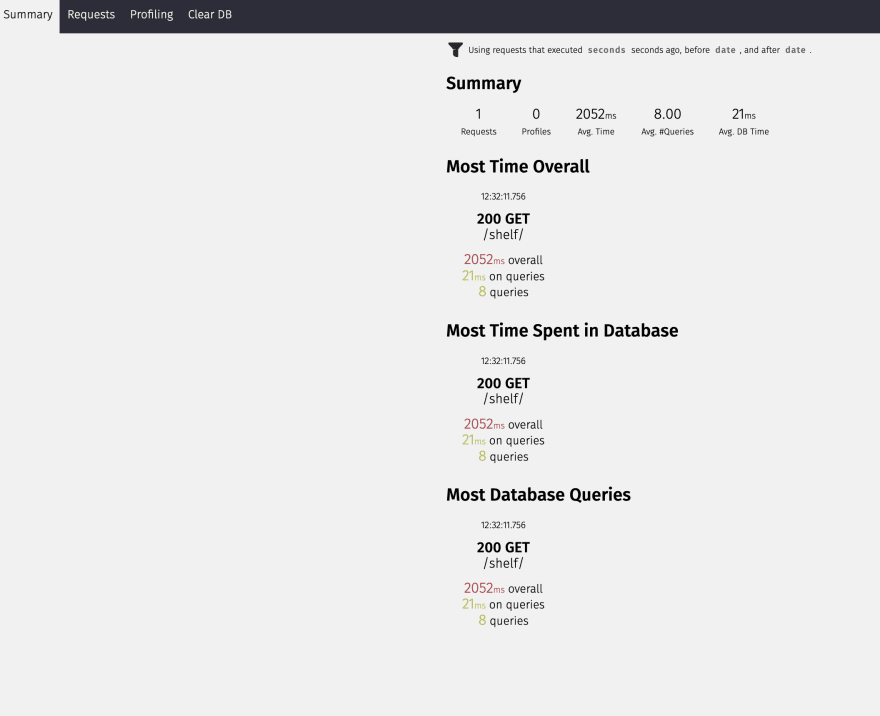
-
/silk/endpoint is the dashboard and lists all the recorded requests. - The quick view under
Most Time Overallshows, theresponse status, total response time, total time spent in queries, and total number of queries.

- Clicking on the request profile takes to the detail view. The detail view displays
request headers details, response headers, and details on how to use the client to connect to the endpoint.

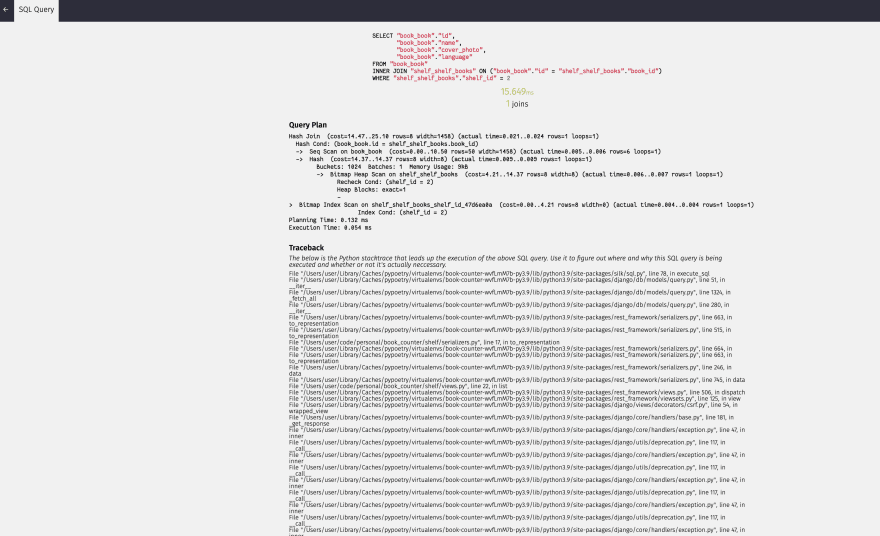
- The SQL tab displays all the queries made during the request-response cycle.
- Clicking on the single query displays the
query plan and Python tracebackto find the source of origin.SILKY_ANALYZE_QUERIESvariable controls the feature to analyze the SQL query.
Silk also provides option to generate Python profile code for a view or any Python function using a decorator or a context manager. Below is the modified view.
from silk.profiling.profiler import silk_profile
class ShelfViewSet(viewsets.ViewSet):
http_method_names = ["get"]
queryset = Shelf.objects.all()
@silk_profile(name='Shelf list')
def list(self, request):
name = request.GET.get('name')
qs = self.queryset
if name:
qs = qs.filter(name=name)
data = ShelfSerializer(qs, many=True).data
return Response(data)

- Profile tab displays the call graph and Python traceback. The page also shows the link to download ` profile file(.prof). snakeviz is an excellent tool to visualize the profile data.
- Below is the profile visualized using snakeviz.

- Snakeviz graph is visually pleasing and gives a breakdown of the function call based on time spent.
Other features
- Dynamic Profiling - Profile specific function or class during runtime.
SILKY_DYNAMIC_PROFILING = [{
'module': 'shelf.views',
'function': 'ShelfViewSet.list'
}]
- Silk can also display the time taken by the silk profiler. The setting variable
SILKY_METAcontrols it. When set to True, the dashboard displays the time taken by silk in red color in the display card.
Upside
- Exhaustive profiling option and completeness.
- UI dashboard to visualise and browse the profiling data.
- Storing all the data in the database helps to analyze performance improvement on the same endpoint over time.
- Highly customizable and extensible to profile.
Downside
- The library is not well maintained, there are a lot of open issues, and the PyPI release doesn't support Django 3.2 version.
- A bit of a learning curve and a lot of configuration.
- It can be slow on slow endpoints since it stores all the details in the database.
Conclusion
Performance is a feature that lets the user of the application perform certain types of operations quicker. The profiling tools help developers to measure the application's performance and make decisions accordingly.
There are other Django/Python profilers, but these three profilers help measure and understand the Django application performance. Use these tools to make your Django application faster.
1. 🚀Profiling Django App 🚀- https://t.co/EifIAiW8ba. In this blog post, I discuss three tools. #Django #Python
— kracekumar || கிரேஸ்குமார் (@kracetheking) October 17, 2021
Image Credits
- Foot Print Photo by Martin Widenka on Unsplash.
- Pyinstrument cover image is from the source repository.
- Query Count cover image is from the repository.
- Django Silk cover image is from the repository.

Top comments (0)