
A few weeks ago, the Kitemaker team was working on diagnosing a performance problem one of our larger customers reported. A few seconds after loading Kitemaker, the app would freeze up for several seconds before becoming responsive again. After digging into the problem, we were able to pinpoint that the lockup happened during the fetching of data from our servers. Kitemaker has a two-phased approach to loading data - first the data is loaded from a local offline cache (IndexedDB) in order to get a snappy load, and then we do a fetch from the server to ensure the client always has the latest data. Based on the timing, we could see it was the fetch from the server that was causing the freeze.
There we bunch of places in the code that could be to blame for such a performance issue. Maybe it was our client-side search indexing hogging the CPU? Maybe it was an issue of loading a lot of data all at once into our state management library Recoil? It wasn’t until we did some analysis using Chrome’s profiling tools that we spotted the culprit:
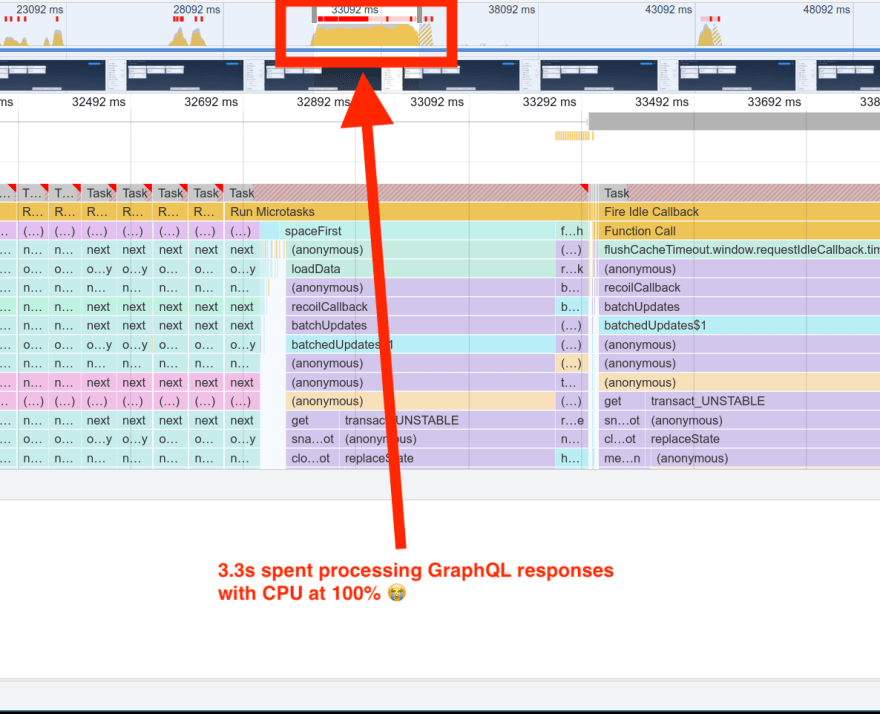
After the network responses were received, > 3 seconds was spent in our GraphQL client, Apollo. Specifically, we were spending a bunch of time and a ton of CPU cycles in the cache layer (InMemoryCache) of Apollo that we’d specifically tried (and apparently failed) to disable.
We suspected we needed to take some drastic action and rip out the Apollo client. But before we get into the details, let’s take a quick walk down memory lane to see how we got here.
A brief history of GraphQL at Kitemaker
We started with GraphQL at Kitemaker on day 1. And in the beginning, we were a pretty traditional-looking GraphQL application. Each screen fetched just the queries it needed from the server and we used Apollo’s state management for everything. This meant Apollo’s InMemoryCache cached all of our data and we frequently wrote updaters to keep that cache in sync after mutations and subscription events.
However, we began to hit some real challenges with Apollo in terms of making it reliable when our users had bad/no internet. Writing optimistic cache updaters was an error-prone pain and we never got the offline experience (persisting mutations client-side until the client came back online, etc.) to work the way we wanted it to.
Therefore, we decided to drop Apollo’s state management in favor of writing our own syncing layer, which was still based on GraphQL. Since the basic functionality of GraphQL was working fine with the Apollo client, we decided to stick with it. We configured it to not do any caching (we thought) and we went on our way:
new ApolloClient({
link: getLink(),
cache: new InMemoryCache({ fragmentMatcher }),
defaultOptions: {
watchQuery: {
fetchPolicy: 'no-cache',
errorPolicy: 'ignore',
},
query: {
fetchPolicy: 'no-cache',
errorPolicy: 'all',
},
},
}),
Apollo’s normalization
So if we’d disabled Apollo’s caching, why were we getting massive amounts of time spent in Apollo’s InMemoryCache? Turns out, the cache actually does two things:
- Caches the results of queries (what we disabled)
- Normalized caching
What’s normalization mean in this case? If you have a GraphQL query that looks like this:
query MyQuery {
space {
labels {
id
name
color
createdAt
updatedAt
}
workItems {
id
title
description
labels {
id
}
}
}
}
Apollo will attempt to match the various objects by ID and create a graph of all of the data in the cache. This means, if the labels on workItems are the same IDs as the ones at the top level of the space query, Apollo will recognize this and build a graph of the data, where accessing labels via the workItems will include all of the properties like name and color even though they weren’t specified. It’s pretty neat! It’s also very costly when you have a lot of data, especially when you’re never actually accessing that graph that Apollo builds.
We tried ripping out the cache entirely, but we didn’t manage to get it to work. It was time to find a new client.
URQL to the rescue
URQL is a lightweight GraphQL client that had been on our radar for a while. It’s almost a drop-in replacement for Apollo if you’re not using Apollo for your state management. However, unlike Apollo, it only (by default) provides caching of GraphQL query results - it does not perform any normalization of the data.
In the places where we were using the Apollo client directly (calling methods like query() and mutation()), switching to URQL was just a matter of massaging parameters into the correct format. Similarly, for the places where we used React hooks (like useQuery() and useMutation()), switching was basically figuring out that the hooks took arguments in a slightly different format and returned some extra objects/callbacks (that we didn’t really care about).
Error handling was a bit of work since there were some places where the Apollo client threw exceptions where URQL just quietly returned an error. Overall though, URQLs CombinedError (which wraps GraphQL errors and network errors together in a single object) is easy to work with and helped us clean up our error handling code.
Additionally, we created a bit more work for ourselves by upgrading the library we use for GraphQL subscriptions over web sockets, moving from the seemingly unmaintained subscriptions-transport-ws to the active graphql-ws project (which is URLQ’s library of choice for subscriptions).
The work took about a week including upgrading some Apollo Server libraries while we were at it.
After we switched to URQL, the performance timeline looked like this:
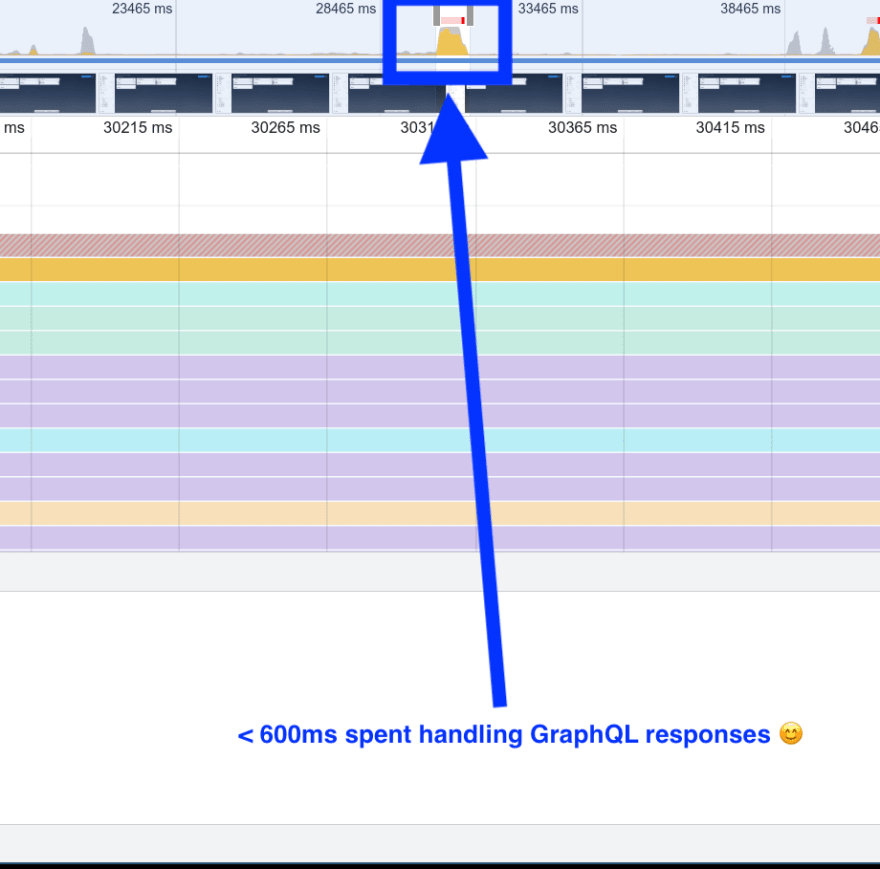
While there’s still some room for improvement, the lockup is gone and the app spends much less time processing the response.
Wrapping it up
Having made the switch of libraries, we were delighted to see that the application no longer locked up after fetching data in the background. Three seconds we were previously wasting processing data into a format we didn’t need was gone. As an added bonus, we upgraded some GraphQL-related dependencies to their latest-and-greatest versions. If any team is using Apollo but doesn’t require any of the caching or state management aspects, we definitely recommend taking a peek at URQL.
We're building Kitemaker, an alternative to your issue tracker that helps product managers, designers, and engineers collaborate better from ideation to delivery. Click here to learn more.
Images:
Top photo by Stanos

Top comments (0)