
Motivation
As I would call me a fan of serverless and especially of Azure Functions and their Durable extension, I am always looking for use-cases on applying them and getting some learning out of it.
Of course I follow the usual suspects in that area like Marc Duiker and the blog post about his Twitter Bot made me curious.
As I am not a .NET programmer I thought it might be a good chance to develop the same story with TypeScript-based Azure Functions as there are always some "surprises" with Azure Functions when moving away from .NET 😉. In addition I wanted to use some other patterns than used by Marc namely sub-orchestration.
Next I needed a topic for the update notification. As my roots are in the area of SAP there is one favorite open source project that I have: Kyma which basically is an opinionated stack for developing app extensions on Kubernetes.
So why not post update tweets about new releases published to the GitHub repository (and other related repositories).
In this blog post I will guide you through the journey of developing this bot and highlight what I have learned along the way.
The code is available in GitHub.
Process Flow - Requirements
The Twitter bot should have the following process flow:
- The process to check for updates should be triggered on a regular basis (e.g. every 6 hours)
- Based on a configuration that contains the repositories that should be checked a process must be started that executes the following steps for each repository:
- Get the latest release information from GitHub
- Check if a tweet was already sent out for the release. If this is not the case, create a status update on Twitter and store the information about the latest release.
The question is: how can we bring this process to life using Azure Functions i.e. Durable Functions?
In general there are several options. In this blog post I will focus on how to solve it with a pattern called sub-orchestration (see official documentation).
Solution Architecture
Projecting the process flow to the solution space of Azure Functions and Durable Functions lead me to the following architecture:
- The trigger for the process is a timer-based Function that calls a Durable Orchestrator.
- The Durable Orchestrator contains two sequential steps:
- Call of an Activity Function that fetches the configuration from an Azure Storage Table.
- For each entry in the configuration the orchestrator must fetch the current GitHub release, check if there was already a Tweet about it and react accordingly.
The second step in the Durable Orchestrator can be done via a Fan-in/Fan-Out pattern or via a sub-orchestration.
I decided to use the later one as it seems quite natural to me to encapsulate the process steps in a dedicated orchestration as a self-contained building block.
So the second step in my main orchestrator is the call of a second orchestrator that comprises the following steps for each repository to check:
- Get the information from GitHub via an Activity Function.
- Get the information about the tweet history for the repository from a history table stored in another Azure Table via an Activity Function.
- Decide if an update is necessary. If this is the case trigger:
- an Activity Function to send the tweet.
- an Activity Function to update the History table.
In one picture this looks like this:

In order to store the API keys for the interaction with the Twitter API I used Azure Key Vault that can be integrated with a Function App.
Development Setup
I did all my development locally on a Windows machine making use of Visual Studio Code and the Azure Functions Extension.
As I use Durable Functions and store some configuration in Azure Tables I needed a Storage Emulator for the local development. I used Azurite for that and the Storage Explorer to have some insights.
Of course do not forget to point the Functions to the emulator by setting the property AzureWebJobsStorage in the local.settings.json file to UseDevelopmentStorage=true
Now let us walk through the single components of the solution and highlight some specifics that crossed my path along the way.
Solution Components
Azure Storage
Let's start with the persistency for the configuration and the history. For that I created two tables:
- one to store the configuration (
SourceRepositoryConfiguration) i.e. which repositories to look at, what are the hashtags to be used etc. - one to store the history of our updates (
RepositoryUpdateHistory) i.e. what was the latest release that we tweeted about.
Here is how the configuration SourceRepositoryConfiguration looks like:
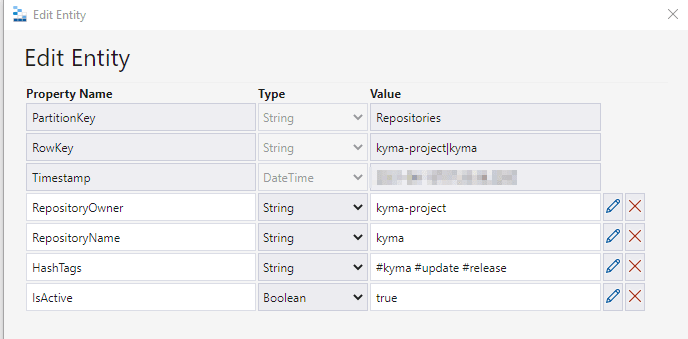
And here how an entry in the history table RepositoryUpdateHistory looks like:
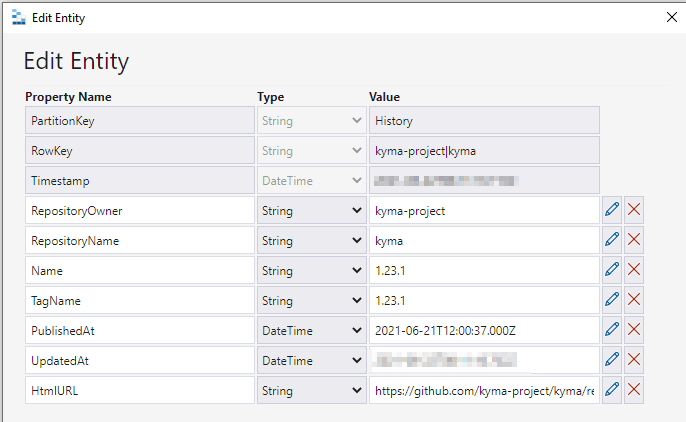
With this in place, let's move on to the Azure Functions part of the story.
Timer-based Function
The entry point to the Orchestration is a timer based Function. The creation via the Azure Functions extension is straight-forward.
I adopted the function.json file to start every six hours, by setting the corresponding value:
"schedule": "0 0 */6 * * *"
In addition, we need to make the Azure Function runtime aware that this Function can trigger an orchestration. To do so, we add the corresponding binding in the function.json file:
{
"name": "starter",
"type": "orchestrationClient",
"direction": "in"
}
We must then adopt the code of the timer-based Function to call the main Orchestrator Function. The final code looks like this:
import * as df from "durable-functions"
import { AzureFunction, Context } from "@azure/functions"
const timerTrigger: AzureFunction = async function (context: Context, myTimer: any): Promise<void> {
const client = df.getClient(context)
const instanceId = await client.startNew(process.env["MainOrchestratorName"], undefined, undefined)
context.log(`Started timer triggered orchestration with ID = '${instanceId}'.`)
}
export default timerTrigger
As you can see I did not hard-code the name of the main orchestrator that should be called, but provide it via an environment variable.
That's all to get the orchestration party started 🥳
💡 However, during local development I wanted to trigger the orchestration manually and therefore I also created an HTTP triggered Function, to be able to do so.
As a spoiler, I also deployed that Function to Azure, but I deactivated it. It serves me as a backup to trigger the process manually in production if I want or need to.
The Main Orchestrator
As described in the architecture overview, I have one main Orchestrator Function that comprises two steps:
- Call an Activity Function to retrieve the information which repositories to check (the
Config ReaderActivity Function) - For each repository that should be watched, schedule a sub-orchestration with the process steps containing the "business logic". The orchestrator gets the configuration data as input.
There is not too much code needed to achieve this: for each entry in the configuration a sub-orchestration is set up and then scheduled by the main orchestrator:
const configuration = yield context.df.callActivity("KymaUpdateBotConfigReader")
if (configuration) {
const updateTasks = []
for (const configurationEntry of configuration) {
const child_id = context.df.instanceId + `:${configurationEntry.RowKey}`
const updateTask = context.df.callSubOrchestrator("KymaUpdateBotNewsUpdateOrchestrator", configurationEntry, child_id)
updateTasks.push(updateTask)
}
if (context.df.isReplaying === false) {
context.log.info(`Starting ${updateTasks.length} sub-orchestrations for update`)
}
yield context.df.Task.all(updateTasks)
}
⚠ There is one strange behavior that I encountered. The daat fetched from the configuration has column names that start with a capital letter as in the Azure Storage Table (e.g. RepositoryOwner). After transferring the object to the sub-orchestrator it seems that some JSON manipulation takes place and the name in the input parameter of the sub-orchestrator will start with a small letter (e.g. repositoryOwner). This needs to be kept in mind, otherwise you will be surprised when you assign the data later in the processing.
The Config Reader Activity Function
The reading of the configuration can be solved declaratively via input binding. For the sake of the later evaluation I only want to get the entries that are marked as isActive which can be achieved via a filter.
So the whole magic for this Function happens in the function.json file:
{
"name": "repositoryConfiguration",
"type": "table",
"connection": "myStorageConnectionString",
"tableName": "SourceRepositoryConfiguration",
"partitionKey": "Repositories",
"filter": "(IsActive eq true)",
"direction": "in"
}
The Function itself returns the fetched data to the caller.
⚠ The official documentation for JavaScript Functions states that you must not use the
rowKeyandpartitionKeyparameters. However, they do work and I could not see any impact on the behavior. So I did not pass the partition key as a OData filter parameter and opened a issue on the documentation https://github.com/MicrosoftDocs/azure-docs/issues/77103.
The Sub-Orchestrator
As mentioned in the previous section the main process logic is orchestrated by the sub-orchestrator.
From the perspective of the Function Configuration it is another Azure Functions Orchestrator, so nothing special there.
The orchestrator executes the following steps:
- Call an Activity Function to get the latest release from the GitHub repository (
GitHub ReaderActivity Function). - Call an Activity Function to retrieve the information about the last update that was executed by this Twitter bot stored in an Azure Storage table (
History ReaderActivity Function). - Check if a new release exists. If this is the case tweet an update about the new release (
Update Twitter SenderActivity Function) and store the updated information into the history table (History UpdateActivity Function).
When you look at the code in the repository there is a bit more happening around, as I can influence the behavior of the orchestration to suppress sending tweets and to suppress the update of the table for the sake of testing and analysis options. Basically a lot of if clauses.
As things can go wrong when calling downstream system I call the Activity Function with a retry setup (callActivityWithRetry) to avoid immediate failures in case of hiccups in the downstream systems. The configuration parameters are injected via environment parameters from the Function App settings.
Let us now take a look at the single activities that are called throughout this orchestration.
The GitHub Reader Activity Function
The setup for querying the GitHub repositories is done via the
GitHub REST endpoints.
As the number of calls is quite limited in my scenario, I use the publicly available endpoints so no authentication is needed. The restrictions that come along with respect to the number of calls per hour do not apply in my case, so I am fine with that.
For the sake of convenience I use the @octokit/core SDK that helps you a lot with interacting with the endpoints.
The logic for getting the data boil down to three lines of code:
const octokit = new Octokit()
const requestUrl = `/repos/${context.bindings.configuration.repositoryOwner.toString()}/${context.bindings.configuration.repositoryName.toString()}/releases/latest`
const repositoryInformation = await octokit.request(requestUrl)
The Activity Function curates the relevant information for the further processing from the result and returns it to the orchestrator.
The History Reader Activity Function
In this Activity Function we fetch the historical information from our storage for the repository that we want to check to find out which was the latest version we were aware of.
Although the requirement is the same as for reading the configuration, the filtering needs a bit more input namely the repository owner and the repository name. Although this data is transferred into the Function via the activity trigger, it is not accessible via for the declarative definition of the Table input binding (or at least I did not manage to access it).
Therefore I read the whole history table via the input binding and then filter the corresponding entries in the Activity Function code. As the number of entries is not that large, there shouldn't be a big performance penalty.
The binding itself is therefore quite basic:
{
"name": "updateHistory",
"type": "table",
"connection": "myStorageConnectionString",
"tableName": "RepositoryUpdateHistory",
"partitionKey": "History",
"direction": "in"
}
And the filtering of the desired entry looks like this:
const result = <JSON><any>context.bindings.updateHistory.find( entry => ( entry.RepositoryOwner === context.bindings.configuration.repositoryOwner && entry.RepositoryName === context.bindings.configuration.repositoryName))
With this information the orchestrator can now decide if a tweet needs to be sent and consequently the history table must be updated. The following sections describe the Activity Functions needed to achieve this.
The Update Twitter Sender Activity Function
If a tweet should be sent out, we need to call the Twitter API. In contrast to the GitHub Activity we eed a registered as a developer in the Twitter developer portal and also register an app in that portal to be able to do so. This is well described in the official documentation (see developer.twitter.com).
With this in place we "just" need to to make an authenticated call to the Twitter API, right? This is where the fun starts ...
There is no official tool, library or SDK for that (see Twitter developer platform - Tools and Libraries). There are some community contributions but most of them are outdated and/or reference outdated npm packages including some with security vulnerabilities.
I finally ended up with twitter-lite
that has TypeScript support and takes over the burden of authentication.
However, for TypeScript based implementations you must take care on the import as discussed in this GitHub issue.
Using the following import works:
const TwitterClient = require('twitter-lite')
The final code then looks like this:
const tweetText = buildTweet(context)
try {
const client = new TwitterClient({
consumer_key: process.env["TwitterApiKey"],
consumer_secret: process.env["TwitterApiSecretKey"],
access_token_key: process.env["TwitterAccessToken"],
access_token_secret: process.env["TwitterAccessTokenSecret"]
})
const tweet = await client.post("statuses/update", {
status: tweetText
})
context.log.info(`Tweet successfully sent: ${tweetText}`)
} catch (error) {
context.log.error(`The call of the Twitter API caused an error: ${error}`)
}
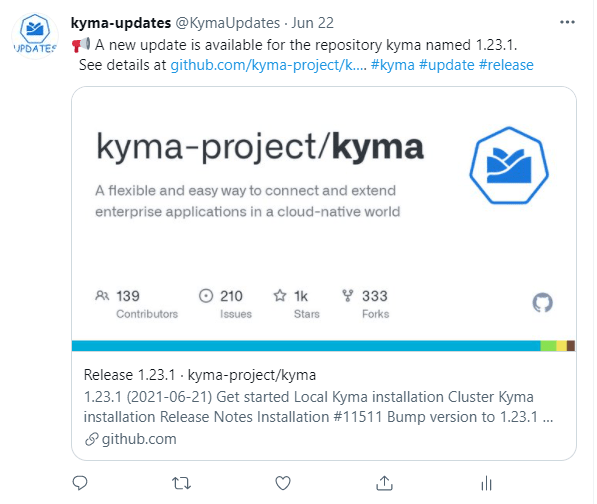
The text of the is build via a combination of free text, the news from GitHub and the data from the configuration table where I kept my hashtags.
Here one example of an tweet issued by the bot:
The History Update Activity Function
The last step of the orchestration is the update of the entry in the history table to remember the latest version that we tweeted about.
As we want to either insert a new value into the table (if we tweeted for the first time) or update an existing entry, we cannot use the Table Output binding as this one only allows inserts (and be assured I tried to update via that binding 😉).
So I update the table entries via code, which is okay (do not be too "religious" about bindings). I used the Microsoft Azure Storage SDK for Node.js and JavaScript. This SDK is quite cumbersome to use, as it relies on callback functions. I wrapped them using the pattern described in this blog post by Maxime Rouiller.
With that the code looks like this:
const tableSvc = AzureTables.createTableService(process.env["myStorageConnectionString"])
const entGen = AzureTables.TableUtilities.entityGenerator
let tableEntry = {
PartitionKey: entGen.String(process.env["HistoryPartitionKeyValue"]),
RowKey: entGen.String(context.bindings.updateInformation.RowKey),
RepositoryOwner: entGen.String(context.bindings.updateInformation.RepositoryOwner),
RepositoryName: entGen.String(context.bindings.updateInformation.RepositoryName),
Name: entGen.String(context.bindings.updateInformation.Name),
TagName: entGen.String(context.bindings.updateInformation.TagName),
PublishedAt: entGen.DateTime(context.bindings.updateInformation.PublishedAt),
HtmlURL: entGen.String(context.bindings.updateInformation.HtmlUrl),
UpdatedAt: entGen.DateTime(new Date().toISOString())
}
const result = await insertOrMergeEntity(tableSvc, process.env["HistoryEntityName"], tableEntry)
In the meantime an new library arrived (Link) that support state-of-the-art JavaScript and TypeScript. To be honest, I was too lazy to switch, as the API changed a bit or maybe I just wanted to keep some work for later improvement ... who knows 😇
With that we are through the implementation of the single Functions. Let us take a look at the surroundings of the development in the next sections.
Some Points about Local Development
As I mentioned before, I did the complete development locally and here some points I think are worth to mention:
- The storage emulator Azurite works like a charm. So no need to rely to the outdated Azure Storage emulator. You can and should switch to Azurite.
- I wanted to switch off the timer trigger Function during development as I relied on the HTTP triggered Function to start the orchestration. To achieve this you need one setting in the
local.settings.jsonfile namely"AzureWebJobs.[NameOfTheFunction].Disabled": true. The Function runtime will do some sanity checks on the Function despite of that setting that made me aware of an error in the Function. That's cool imho. - As I used Azurite for the local development I had the corresponding setting of
"AzureWebJobsStorage": "UseDevelopmentStorage=true"in mylocal.setting.jsonfile. I decided to use a different storage for my configuration and history table. which means you must specify the connection string to that storage in your Functions that make use of the non-default storage ... which you might forget when you do the local development. For the sake of science I made that error (or I just forgot the setting .. who knows) and be assured you will become aware of that when you deploy the Function. So specify that connection in your bindings in case you deviate from the default storage attached to your Function like in my case:
"connection": "myStorageConnectionString"
Deployment via GitHub Actions
In order to deploy my Functions to Azure I made use of GitHub Actions. I must state: I was stunned how smooth the deployment went through.
I followed the official documentation (Link) and used the pre-defined template and it worked out of the box.
The only adoption I made was to exclude files from triggering the action e. g. the markdown files via:
on:
push:
branches:
- main
paths-ignore:
- "**.md"
With the improvements that GitHub is pushing towards Actions (like environments etc.) I think that this is the path to following along in the future.
Setup in Azure
I did the setup of the main resources in Azure manually (no Terraform, no Bicep .. and yes shame on me for that - having said that I will definitely take a look at Bicep and try to replicate the setup with it).
Nevertheless some remarks on my setup and what I have seen/learned
- I stored my Twitter app keys in Azure Key Vault and referenced the secrets in my Function App settings/configuration. The reference follows the pattern
@Microsoft.KeyVault(SecretUri=[URI copied from the Key Vault Secret]). One cool thing here is: you might make a copy & paste error but Azure has you covered there as it will validate the reference and put a checkmark if everything is fine (valid URI and valid access rights):
- Use the Azure Storage Explorer to analyze you Durable Function executions. You can use it locally or with your resources in Azure. It really helps you a lot when you need to dig into that.
- Do logging in your Functions. And if you thing you have enough, think again. This can really help you with narrowing down errors especially in a setup with nested orchestrations
- Separate configuration and code i.e. use environment variables/App setting to increase the flexibility of your setup and avoid magic numbers and magic strings as far as possible.
- Use Azure Application Insights. The effort for the basic setup is minimal and it is a huge help when you need to analyze errors, performance issues etc.
- Create budget alerts. Although we are at the lower end of costs, maybe some errors occur that make your Functions run crazy, then this is thing comes to your rescue. I also have an unexpected high usage of the storage that I might need to investigate on.
Writing this blog post, the Twitter bot is running only a week, so everything looks fine so far. This also means no deeper insights with respect to productive usage in this project so it would be a bit artificial to make statements about best practices there.
If you want to read a bit more about it from the experience that is more settled I would recommend the blog post My learnings from running the Azure Functions Updates Twitterbot for half a year by Marc Duiker.
Conclusion and Outlook
So here we are now. We have a Twitter Bot up and running making use of Azure Durable Functions (including sub-orchestrators) in TypeScript. I experienced a huge improvement in this area over the last years although the primus inter pares with respect to the Azure Functions runtimes is still .NET in my opinion.
The experience of setting up the Functions and deploying them was smooth and I especially like the possibility to do the development completely locally. This also got improved with Azurite now.
There were no real frustrating bumpers along the way besides the usual "finding the right npm package".
So wrapping up: I hope you find some useful hints and learnings in this post and give Durable Functions a try also in more complex business process like scenarios.

Top comments (0)