
Since early 2025, AI labs have flooded us with so many new models that I'm struggling to keep up.
But trends says nobody cares!
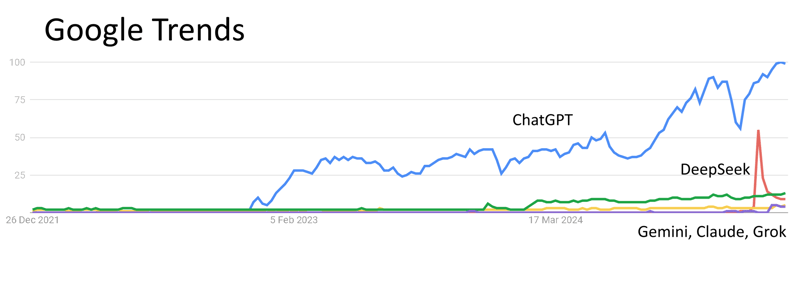
There is only ChatGPT.
How so?
The new models are awesome, but their naming is a complete mess. Plus, you can't even tell models apart by benchmarks anymore. Plain "this one's the best, everyone use it." doesn't work now.
In short, there are many truly fantastic AI models on the market, but few people actually use them.
And that's a shame!
I'll try to make sense of the naming chaos, explain the benchmark crisis, and share tips on how to choose the right model for your needs.
Too Many Models, Terrible Names
Dario Amodei has long joked we might create AGI before we learn to name our models clearly. Google is traditionally leading the confusion game:
To be fair, it makes some sense. Each "base" model now has lots of updates. They're not always groundbreaking enough to justify each update as a new version. That's where all these prefixes come from.
To simplify things, I put together a table of model types from major labs, stripping out all the unnecessary details.
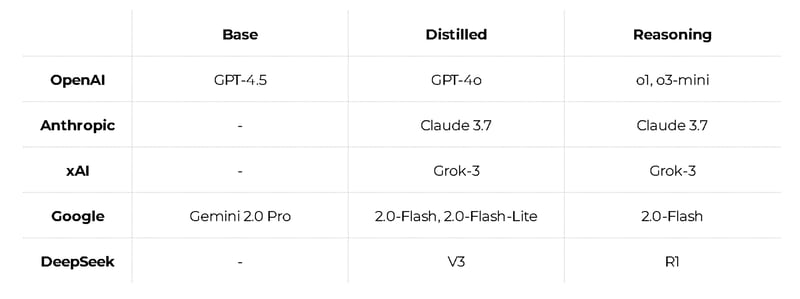
So what are these types of models?
There are huge, powerful base models. They're impressive but slow and costly at scale.
That's why we invented distillation: take a base model, train a more compact model on its answers, and you get roughly the same capabilities, just faster and cheaper.
This is especially critical for reasoning models. The best performers now follow multi-step reasoning chains—plan the solution, execute, and verify the outcome. Effective but pricey.
There are also specialized models: for search, super-cheap ones for simple tasks, or models for specific fields like medicine and law. Plus a separate group for images, video, and audio. I didn't include all these to avoid confusion. I also deliberately ignored some other models and labs to keep it as simple as possible.
Sometimes more details just make things worse.
All Models Are Basically Equal Now
It's become tough to pick a clear winner. Andrej Karpathy recently called this a "evaluation crisis."
It's unclear which metrics to look at now. MMLU is outdated, SWE-Bench is too narrow. Chatbot Arena is so popular that labs have learned to "hack" it.
Currently, there are several ways to evaluate models:
- Narrow benchmarks measure very specific skills, like Python coding or hallucination rates. But models are getting smarter and mastering more tasks, so you can't measure their level with just one metric anymore.
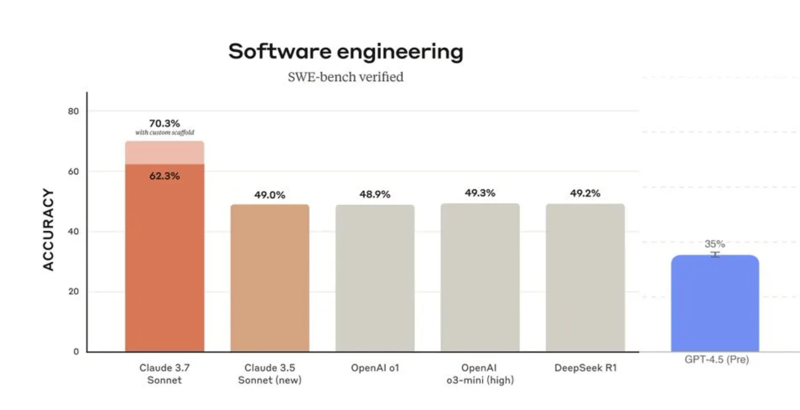
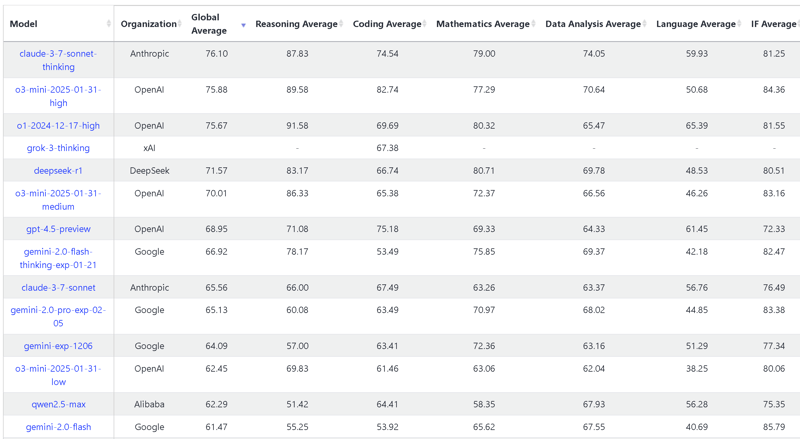
- Comprehensive benchmarks try capturing multiple dimensions with loads of metrics. But comparing all these scores quickly becomes chaotic. Note that people try to factor multiple of these complex benchmarks. Five or ten at a time! One model wins here, another there—good luck making sense of it. LifeBench has 3 metrics within each category. And that's just one benchmark among dozens.
- Arena, where humans blindly compare model answers based on personal preferences. Models get an ELO rating, like chess players. Win more often, get higher ELO. But this was great until the models got too close to each other.
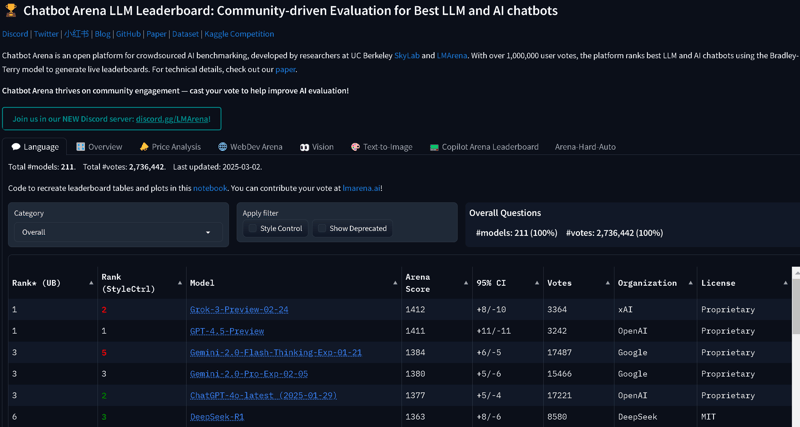
A 35-point difference means a model is better just 55% of the time.
As in chess, the player with the lower ELO still has a good chance to win. Even with a 100-point gap, a "worse" model still outperforms in a third of cases.
And again—some tasks are better solved by one model, others by another. Choose a model higher on the list and one of your 10 requests might be better. Which one and how much better? Who knows.
So, How Do You Choose?
For lack of better options, Karpathy suggests relying on the vibe-check.
Test the models yourself and see which one feels right. Sure, it's easy to fool yourself. It’s subjective and prone to bias—but it's practical.
Here's my personal advice:
If the task is new—open multiple tabs with different models and compare results. Trust your gut on which model requires less tweaking or edits.
If the task is more familiar, use only your best model.
Forget about chasing benchmark numbers. Focus on the UX you like and prioritize the subscription you're already willing to pay for.
If you still want numbers, try https://livebench.ai/#/. The creators claim it fixes common benchmarking issues like hacking, obsolescence, narrowness and subjectivity.
For product creators, here's a great guide from HuggingFace on how to set up your own benchmark.
Meanwhile, if you've been waiting for a sign to try something other than ChatGPT, here it is:
https://claude.ai/
https://gemini.google.com/
https://grok.com/
https://chat.deepseek.com/
https://chat.openai.com/
This is my first post here, but I have more writing on my Substack.
I'd appreciate it if you subscribed—but honestly, the dev community seems pretty cool, so I plan to keep writing more stuff here.
Maybe smth usefull on each of the models I mentioned.

Top comments (0)