
Written by Rosario De Chiara✏️
Large language models (LLMs) have gained immense popularity, with chat interfaces often assumed to be the default way to interact with them. This article explores why chatbots became the norm, the problems they create for developers, and alternative, more effective solutions.
Why chatbots are everywhere
Chatbots emerged largely because early LLM services used conversational formats, which appealed to users by mimicking human-like interactions. A notable example is OpenAI, which promoted its services by releasing ChatGPT, a widely publicized chat interface to its powerful LLM.
The success of ChatGPT reinforced the idea that chat-based interaction was the most intuitive and effective way to harness LLM capabilities. However, while chat works well in certain contexts, there are many scenarios where a different interface would offer a more optimal experience.
For example, LLMs can function as backend components where most interactions are handled by a frontend interface, such as a dashboard, web app, or mobile app, without relying on a chat-based system. This is the case in a personalized recommendation engine, where an LLM analyzes user preferences and behavior to generate tailored recommendations for products (e.g., a trip to Italy), content (e.g., recipes), or resources (e.g., scientific papers) without requiring a chat interface.
Similarly, in the business domain, an LLM can power a business intelligence dashboard, interpreting and summarizing data, generating insights, and providing explanations for visualizations (e.g., charts and graphs). Users can interact with the system simply by clicking buttons or selecting data points, rather than engaging in a chat.
The problem of chat interface inertia
Many developers default to chat interfaces even for tasks better suited to other UI types — such as dropdown menus, interactive dashboards, and command line interfaces — resulting in inefficient, overly complex user experiences.
For example, a simple Google search for "chat with PDF" reveals countless services offering the ability to "chat" with a document:  The concept is enticing and straightforward: find a clever way to feed document text into a prompt — perhaps using a retrieval-augmented generation (RAG) architecture like LlamaIndex — and allow users to ask questions as if they were chatting with the document.
The concept is enticing and straightforward: find a clever way to feed document text into a prompt — perhaps using a retrieval-augmented generation (RAG) architecture like LlamaIndex — and allow users to ask questions as if they were chatting with the document.
However, chat-based interactions create certain expectations. Users assume real-time responses, which can significantly strain hardware resources. Forcing chat interactions complicates development, negatively impacts the user experience, and introduces performance inefficiencies.
In many cases, simpler and more direct interfaces would be more suitable, reducing complexity and optimizing system performance.
When chat works best
The "chat with PDF" use case is part of a broader trend: "chat with your data." While this model has its advantages, it is not always sustainable as a primary solution.
Chat interfaces excel in situations involving unstructured data or open-ended questions, providing users with flexibility and opportunities for exploration. LLMs have the potential to improve UI designs by introducing smart features such as form completion, dynamic search, and data insights without forcing interactions into a chat format.
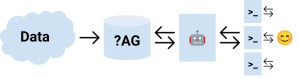
The figure below shows the "chat with your data" model. Unstructured data, represented by a cloud, is fed into an “?AG” block:

This representation is used to illustrate various architectures that can augment generation, such as retrieval augmented generation (RAG), cache augmented generation (CAG), and the more general knowledge augmented generation (KAG). The symbol “?AG” encompasses all these possible variations of augmented generation approaches. The user (the smiley icon) interacts by using a chat-based interface with the model.
I propose a different model. The idea is to automate most interactions while allowing users to refine outputs through selective dialogue:
The successive phase refines the results by chatting with specific sections of the artifact.
Microsoft Copilot in Visual Studio Code is a successful example of this hybrid model. Developers work on their code, then ask Copilot to generate specific sections. The generated code varies in quality depending on the language and framework, but users can engage in targeted conversations with specific sections as needed. This aligns with the information retrieval mantra: "Overview first, zoom and filter, then details on demand."
In the following example, the developer asks Copilot to expand the selected lines of code:
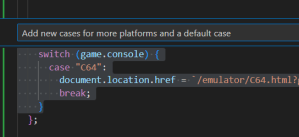
The LLM version of the information retrieval mantra
The information retrieval mantra, formulated by Ben Schneiderman, is a principle widely used in user interface and data visualization design. It consists of three main steps:
- Overview first — Provide users with a broad overview of the information or dataset so they can understand the context and scope
- Zoom and filter — Allow users to narrow down the information, zoom in on relevant sections, or filter out unnecessary details
- Details on demand — Enable users to drill down and access specific, detailed information only when necessary
This approach helps users navigate complex datasets efficiently, moving from a high-level understanding to detailed information as needed. For LLM integration, we propose a similar mantra: "Draft first, refine through dialogue, then perfect on demand."
- Draft first — The LLM generates an initial draft based on a knowledge base or input data, providing a foundational response
- Refine through dialogue — Users engage in targeted conversations with specific sections, requesting corrections, expansions, or clarifications
- Perfect on demand — After iterative refinements, users can fine-tune or finalize the output to achieve a polished result
This approach balances automation with user-driven interaction, enabling efficient initial content creation while allowing thoughtful customization through guided conversation. However, it also presents challenges, as we are experiencing a paradigm shift in capabilities. Developers invest significant effort in controlling and limiting an LLM’s tendency to generate answers—even when data is incomplete or the response is uncertain.
To better regulate an LLM’s inclination to always provide an answer, a useful approach is to give users the ability to accept or reject even the smallest intervention. For example, in the following figure, Microsoft Copilot in Visual Studio Code prompts users to explicitly accept or decline a proposed solution. This subtle UI integration allows users to leverage an LLM while maintaining full control over every interaction: 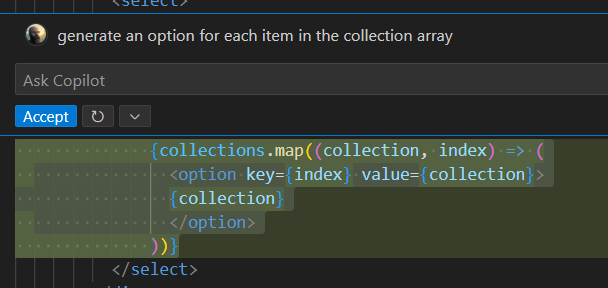 A key benefit of this model is that the first phase occurs asynchronously: the LLM can query the augmentation component multiple times before returning a response. Users then review the output and engage in minimal, focused chat interactions for refinements. This reduces token exchange, improves efficiency, and maintains a smooth user experience.
A key benefit of this model is that the first phase occurs asynchronously: the LLM can query the augmentation component multiple times before returning a response. Users then review the output and engage in minimal, focused chat interactions for refinements. This reduces token exchange, improves efficiency, and maintains a smooth user experience.
Conclusion
While chat interfaces have become the default for interacting with LLMs, they are not always the most efficient or effective solution. Overreliance on chat can introduce unnecessary complexity, strain resources, and limit the user experience.
By adopting a hybrid approach — automating initial drafts and using chat-based refinement only when necessary — we can optimize both performance and usability.
This model balances LLM automation with user-driven refinement, leading to more flexible and efficient workflows, especially in contexts where structured interactions are preferable. Rethinking LLM integration beyond chat will enable developers to create more effective, user-friendly experiences.
Get set up with LogRocket's modern error tracking in minutes:
- Visit https://logrocket.com/signup/ to get an app ID.
- Install LogRocket via NPM or script tag.
LogRocket.init()must be called client-side, not server-side.
NPM:
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
Script Tag:
Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
3.(Optional) Install plugins for deeper integrations with your stack:
- Redux middleware
- ngrx middleware
- Vuex plugin

Top comments (0)