
Let's say, we want to quarantine people who have been exposed to a newly discovered virus that has a few symptoms in order to subdue it as soon as possible. However, the symptoms overlap with the common flu virus and we have a Machine Learning (ML) model trained to predict the virus in accordance with the symptom. In order to know what symptoms point to which pathogens and by how much importance, we definitely have to explain the predictions.
Similarly, many a time it might have occurred, why does an ML model predict something, and what might be the triggers for it. For basic models like Logistic Regression or Naive Bayes, explaining the model might be fairly simple but for models like Neural Networks, things get a bit complex.
In this article, we will try to understand how all sorts of models can be explained, without diving into too many technical details.
Contents
- What is model explainability
- Why should we care?
- Explainable approaches
- Accuracy and intelligibility trade-off
- Future Work
- References
- Footnote
What is model explainability
Model explainability refers to how accurately we can explain the model's predictions or explain patterns for the predictions. For example, let's say we have trained a model to predict if a person has Covid or not depending on 5 symptoms. This can help us determine which symptom is the most potent in classifying the person having Covid.
Why should we care?
For simpler models, we might not have to need to explain the model. However, for more complex models or if we are skeptical about a model's prediction, model explainability can help us.
More often than not, every ML model has a goal to achieve. For certain applications, the goal is to have high recall whereas for certain, high precision. Let's say, you run a model and the P/R numbers are not in the range you were expecting. In order to reach the goal, you need to understand the model.
A few other questions about any model are :
- Why did our model make a mistake : Explainability can help us understand the importance of features and how it affects a model
- Does our model discriminate : Let's say there is an imbalanced dataset and the model overfits a particular class. For instance, there are many AI-enabled photo post-processing where the AI is trained on Europeans and Americans, so when it does post-processing for any other ethnic group, the photos don't look natural.
- How can we understand and trust the model's decision : Every ML engineer has trust issues with his model when it comes to the production environment. Explaining the model helps build that trust.
- Are we in a high risk environment : There might be times when there is no room for false positives in predictions, like ruling out if a person has cancer or not? In these scenarios, explaining the model is heavily required.
Explainable approaches
There are 2 ways of explaining any ML model:
- Glass box models
- Black box explanation
Let us try to understand them in greater details.
Glass-box models
These models are built in such a way that they are inherently explainable. This means no extra steps are required to explain a model after the training the model, all explanations become a part of the model during the training stage itself. In simple words, if we want the explanations we just need to call an inbuilt method that fetches us the explanations.
Since these models are designed to be interpretable, it provides us with exact and accurate explainability for any prediction i.e. no approximations. Using this reasoning how the models make a decision becomes very easy.
A few examples of glass box models are: Explainable boosting machines (EBM), linear models, decision trees, and GAMs
Black-box explanations
Unlike glass box models, black box explanations are made by training a wrapper on top of existing models. In this approach, the wrapper on top of the model tries to explain the model by varying the inputs and outputs of the model.
To understand it further let's take an example. Consider a castle with 2 gates, entry and exit. Both the gates have guards and they are constantly communicating with each other through some medieval telephone. Now, two people - 30 and 10 years old enter the castle in a queue and come out as 33 and 11 years old people respectively. The guards discuss the changes and say that they have grown old by 10%. They further go on to discuss, that the older the people the more they age. Though the example is a bit contrived it clears the concept.
The biggest advantage of this approach is that since it's like a wrapper, it can work on any model. However, its biggest disadvantage is that depending on the varying outputs it gives an approximate explainability, which might be incorrect in a few scenarios.
A few examples of black-box explanations are: SHAP, LIME, global surrogate, PDP
Accuracy and intelligibility trade-off
Let's first define the terms. Accuracy is the measure of how many correct predictions our model is able to provide. Intelligibility is how easy it is to explain the model.
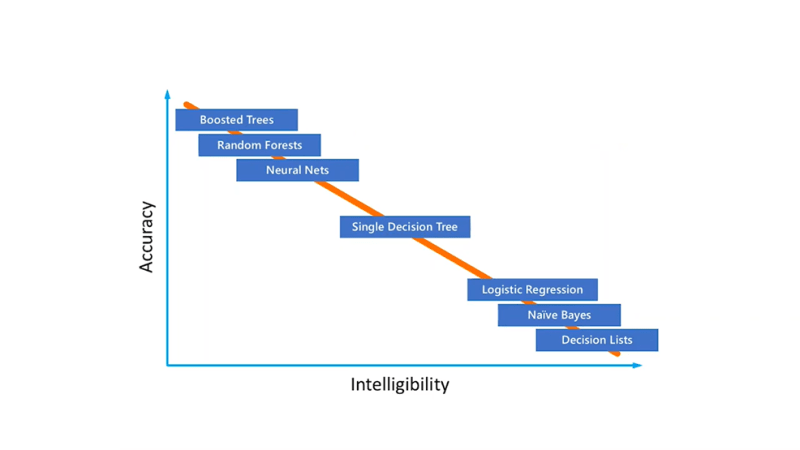
There is this constant trade-off with simpler models having high intelligibility but a lower accuracy and complex models having higher accuracy but lower intelligibility. It is observed in most cases that the simpler models like logistic regression, Decision trees have high intelligibility but low accuracy and it's the exact opposite for complex models like Random Forests and Neural Nets. Now, the question arises of which algorithm to use. We will explore more on this in the next article.
Conclusion
Model explainability is an actively researched area in ML with promising outcomes. It can speed up the lifecycle of ML pipelines by easily explaining the models. In the next article, we will learn more about glass-box and black-box models and how to remove the accuracy vs intelligibility trade-off.
References
- Molnar, C. (2022). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (2nd ed.).
- Kübler, R. (2021). The Explainable Boosting Machine.
Special thanks to Yash Govind for his useful remarks!
Footnote
If you liked this article, do let me know in the comments. If you have any questions write me on LinkedIn.

Top comments (0)