The following post is an excerpt adapted from a chapter about Relay-style pagination my book Advanced GraphQL with Apollo & React.
When you build a GraphQL API you would likely expect that, at some point, there may be too much data to retrieve all of the results from a given data source at once for a GraphQL query that returns a list. This may also be true for list fields nested inside of a GraphQL query. This is where pagination comes in.
While pagination is ubiquitous in the applications we use every day, it can be one of the trickiest things to reason about and implement properly in an app. What's more, there are also several approaches to choose from when deciding how to paginate a GraphQL query.
If you've implemented pagination before, you may be familiar with offset-based or cursor-based pagination. With GraphQL APIs, we also have Relay-style pagination as an option.
Relay-style pagination is a popular choice for paginating GraphQL queries, but it requires additional considerations to ensure a GraphQL schema adheres to Relay's opinionated specification.
In this post, we'll explore each style of pagination along with their relative advantages and disadvantages so you can determine which style would be the best fit for your GraphQL API.
Offset-Based
Historically, offset-based pagination has been a popular choice for paginating results from a database. With offset-based pagination, a client provides information about the number of results it wants to receive per page (called the limit) and how many results to skip before retrieving the limited number of items (called the offset). The server uses these criteria to query the database for that specific set of results (setting a default limit and offset, if necessary).
To visualize how offset-based pagination works, imagine you have a dataset with five items in it and you want to retrieve the second page of those items sorted in descending order with a limit of two items per page:
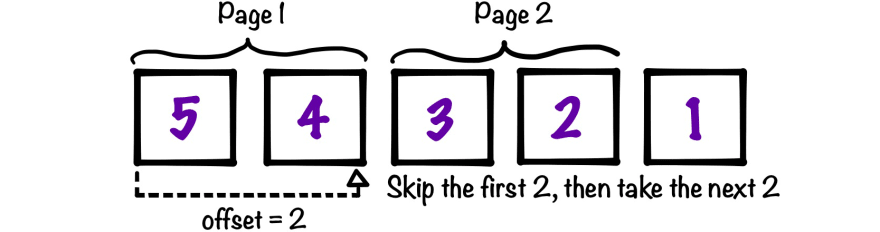
Offset-based pagination is useful when you need to know the total number of pages available. It can also easily support bi-directional pagination. Bi-directional pagination allows you to jump back and forth between pages or to navigate to a specific page within the results. This is the kind of navigation typically seen on blogs.
However, there can be performance downsides to this approach if the queried database has a lot of records in it. Further, if new records are added to the database at a high frequency, then the page window may become mismatched with real-time reality, resulting in duplicate or missed records in the pages of results.
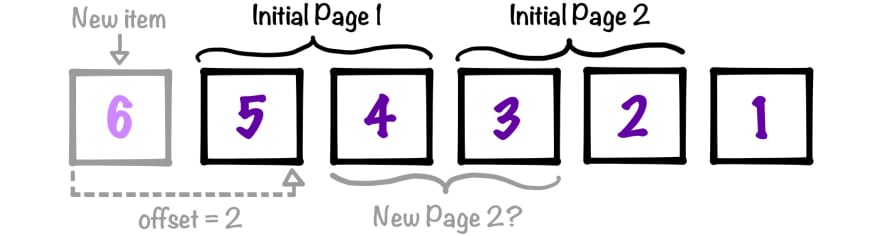
To illustrate this pitfall, imagine retrieving the first page of results from our dataset. While you're browsing those results, a new sixth item is added before requesting the second page. Suddenly, the paging window shifts back one position, and the fourth item will now confusingly appear at the end of the first page and the start of the second page:
Cursor-Based
Cursor-based pagination uses (surprise!) a cursor to progress through results in a dataset. A cursor is a pointer to a specific result in a dataset and can be anything that makes sense to the back-end application as long as it's a unique, sequential value. As a client navigates through subsequent pages, the server returns results after the item marked by the cursor value.
Cursor-based pagination on our five-item dataset (once again in descending order with two items per page) can be visualized as follows:

The nature of the cursor itself is inconsequential to the client—the client just needs to send this value back to the server on subsequent requests so the server knows from which point it should retrieve more results.
Cursor-based pagination is well-suited to datasets updated at high velocities because it helps address the issue of page window inaccuracies that can happen with offset-based pagination. If a sixth item is added to our dataset after retrieving the first page, then there will be no confusion about where to start the second page when using a cursor:

This style of pagination does have its trade-offs though. A cursor-based approach has the downside of not providing any way to jump to a specific page number or calculate the total number of pages. However, if you're building an app that will be updated rapidly and with infinite scrolling implemented in the user interface to browse content, then the lack of numbered pages and total page counts likely won't be deal-breakers for your app.
Relay-Style
Relay-style pagination is an opinionated flavor of cursor-based pagination for GraphQL APIs. Relay itself is a JavaScript framework that can be used as a client to retrieve and cache data from a GraphQL API. It was created by Facebook and was designed with Facebook-level applications in mind (in other words, apps with lots of data in lists that are read and written at a high velocity).
Relay's barriers to entry are a bit higher than other options like Apollo Client, so Relay itself often isn't the first package developers reach for when getting started with GraphQL. However, Relay offers a useful roadmap for how to handle paginated data in GraphQL APIs in what it calls a "cursor connection specification." You can read Relay's full pagination specification here.
Even if you don't intend to use Relay in a client app, you can still follow this specification when implementing pagination in your GraphQL API. Using this style of pagination may also help make your API a bit more future-friendly if any other clients using Relay wish to make requests to it in the future.
An important thing to keep in mind with Relay-style pagination is that it is uni-directional by design. If you need to implement "Previous Page" and "Next Page" buttons to traverse content in an app, then Relay-style pagination probably won't work well for you (although a quick Google search will reveal some proposed workarounds for supporting bi-directional paging with Relay). However, if your user interface requires infinite scrolling to load additional pages of results, this approach will be a good fit for you.
As mentioned previously, Relay is very opinionated about how pagination requests are made via query arguments, as well as the paginated query data output. Here's an example of a hypothetical query with Relay-style pagination implemented for a following field that returns a list of User objects:
query {
user(username: "bob") {
fullName
following(first: 20, after: "someProfileId") {
edges {
cursor
node {
fullName
username
}
}
pageInfo {
hasPreviousPage
hasNextPage
}
}
}
}
You'll notice a few interesting features of this query. First, we have the edges, which is a list containing the edge types. The edge types are an object type with at least two fields called node and cursor.
The node is the object itself and can be just about any GraphQL type except a list (for our case, it would be a User type). The cursor is a string that corresponds to the unique, sequential value that identifies the edge.
Lastly, the pageInfo is an object that must contain at least hasPreviousPage and hasNextPage fields. These fields are both non-nullable booleans.
Also worth noting are the first and after arguments for the query—these are the forward pagination arguments. If we wanted to paginate backward, then we would use the last and before arguments.
SIDEBAR! Backward pagination is different from sorting results in descending order. Backward pagination means starting at what constitutes the end of a dataset and working back to the beginning. Sorting results in descending order means traversing pages of results from the item with the highest sort value to the lowest. A dataset would typically be sorted first, and then would have forward or backward pagination applied to retrieve pages of sorted results.
What's not obvious from the example query above is that at the top level a "connection type" would be implemented as an object type (with the suffix Connection added to its name) and the following field would now return that single connection object instead of a list containing User object types.
While this conceptual model for thinking about query results and its corresponding syntax may seem taxing at first, it will provide a tidy, standardized way for us to deal with pagination in an application.
In Summary
In this post, we explored three different kinds of pagination, including offset-based, cursor-based, and Relay-style pagination.
Offset-based pagination is (usually) quick to implement and is useful when you want to support bi-directional pagination and calculate total page counts, but can create performance issues and isn't well-suited for rapidly updated data sets.
Cursor-based pagination helps address some of the downsides of offset-based pagination if you are working with a data set that is updated at a high velocity and will typically be traversed in a single direction. Relay-style pagination is a specific flavor of cursor-based pagination with an opinionated take on implementing pagination for GraphQL APIs.
Thanks for reading! If you enjoyed this post, I have an entire free chapter from Advanced GraphQL with Apollo & React available for download here.





Top comments (2)
Very useful. The visualizations made it easier to understand. Will think of writing a similar article on Devopedia. Are these pagination methods documented in the GraphQL specs?