
We already discussed how to choose a database and which things to focus on. However, picking a database is just the beginning of our journey. We need to maintain it and use it efficiently later on. There is not much use in getting the latest shiny database if we don’t use its full potential. To do that, we need to understand what we want to get from the database and which things to focus on.
There are multiple dimensions to consider here. We’ll go through them one by one to understand how they may affect our software development lifecycle.
Database internals
It’s important to understand how things work behind the scenes. Going with heap tables and naive SQL statements will get our job done, but surely won’t give us any decent performance. There are various things to understand here.
Data storage
The first thing is data storage. There are multiple approaches to storing data. The relational model focuses on data normalization with normal forms. This leads to no duplication of data, but we need to join tables to get the final entities. Joins are expensive in terms of I/O operations and in terms of data updates. Things get more complicated when we use Object Oriented Programming features like inheritance and polymorphism. There are multiple patterns on how to store objects in the relational database, but they may result in decreasing performance.
However, relational models are just one of many. We can use document databases which are very flexible in terms of what we can store, but typically don’t offer ways of atomic modification of multiple entities or efficient joins. We have key-value stores that are great for caches but are much less effective when we need to scan multiple entities based on some criteria. We have graph databases that optimize graph-related tasks but do not work well when storing generic data.
In short, understanding how the data is stored is crucial to optimize the way we access it. And here comes another dimension: indexes and access patterns.
Indexes and access patterns
Adding data is only the first step. We need to read it later on. When it comes to reading, we typically access entities via some identifier or we search for entities based on attributes. We want these operations to be as fast as possible, as they happen very often in our workload.
When we read about how to improve performance, the first thing we learn is to configure indexes. Modern databases support multiple types of indexes, some to support the “generic” use case, some to aid in very targeted scenarios like text search or JSON scanning. Knowing what index to apply and how it works behind the scenes is crucial.
How to identify which indexes we need? We need to identify our access patterns. We need to check our application source code, see what queries the application sends, and then tune the database for these queries specifically. Access patterns will dictate which fields we need to put in indexes, what types of indexes to configure, and how to evaluate them later on.
However, indexes degrade over time. We continuously modify our applications, so things that were applicable half a year ago may not be applicable anymore. We need to monitor our indexes, check if they are used, and see if they actually increase the performance. This sounds easy enough, but may lead to unexpected results. What if a given index is used only once a week, for instance during the weekend? Should we keep it? What if the index is helpful only in some countries or continents, should we then keep it everywhere? What if we don’t have the feature parity between regions, should we keep our configuration in sync?
Modern databases provide various solutions. There are multiple index types like clustered indexes, GIN indexes, full-text search indexes, or even databases dedicated to supporting particular use cases. Just having an SQL database is not enough. We need to tune our data model and configuration for the specific use cases we have.
Application code versus database code
Another thing to consider is how to optimize particular queries. We have basically three ways of doing that: relying on ORM or some library, writing an efficient query by hand and sending it from an application, or running some code directly in the database.
The first case is the easiest but won’t bring us much performance. If the ORM doesn’t handle the query efficiently, then we may not be able to optimize it without changing our application much. One example is loading an aggregate root from the database - ORM may decide to join multiple tables which will result in loading hundreds or thousands of rows to the application just to build one object. Optimizing that on the ORM level may be impossible without changing the application model.
Writing an efficient query sounds like a good solution, but we lose the benefits of the ORM. The point of using the library is to not bother with data mapping, query construction, keeping it up to date with the data model, etc. If we implement the query by hand, then we lose all of that and need to implement things ourselves. What’s more, the query that we write today may not work well half a year from now, and this will increase the maintenance burden on our end. Query hints may not work anymore, assumptions about data distribution may change, and the engine itself may change which makes our optimizations not work anymore.
Running some code directly in the database can give us some performance improvements, but also brings multiple issues. The database typically uses a different programming language than our application, so we can’t share the code anymore. We may not be able to install dependencies, access the Internet, or even write our code nicely. If you ever wrote a single line of PSQL code, then you probably know the painful syntax and how hard it is to maintain the code. However, modern databases support other languages as well like Python, JavaScript, or R. This makes sharing the code much easier. We still may have a hard time deploying the code via the CI/CD pipeline or even knowing it’s there.
Another issue of writing the code in the database is the lack of visibility. We typically see the code that runs in our application, but we may be very surprised to see that there is some additional code running in the database. Triggers, stored procedures, scheduled tasks - all these elements may improve the performance but also increase the cognitive load of our solution.
Proper paradigm
The next thing to consider is the proper paradigm, especially in the world of heterogeneous applications. OOP is not the only approach to writing the software. We have functional programming, logic programming, and declarative programming in general. Choosing a proper paradigm is crucial to get the best performance out of our database.
However, the database type should match the paradigm to decrease the impedance mismatch. There are things we won’t avoid, for instance, collation (how do you define the order of characters in the String type of your language) or numeric precision (you can’t change it most of the time and you need to use Float or Double). If we process data as documents, then the document database may be much easier to use than the relational one. If we run a data warehouse, then storing things as key-value pairs may not give us good performance.
Choosing the paradigm is even harder when we have a heterogeneous system. If our applications use different paradigms and different programming languages, then we should consider having multiple data stores. Duplication of the data is not a problem as long as we know what the source of truth is, and how to replicate data between the systems. We need to keep our data flow well-defined, which may be a hard task on its own but will bring us performance improvements.
Bounded contexts
Another thing to discuss is bounded contexts. This term comes from the Domain Driven Design (DDD) world and in our case indicates that independent parts of the application should have independent stores.
The User entity doesn’t have a standardized meaning. Users in the e-commerce world will mean an entity that holds the delivery address and the payment method. Users in the financial world will mean an entity that holds investments, loans, and credit cards. Both users will have an address for correspondence, but it doesn’t mean that these users should be represented by the same entity (class, table in the database, etc.). We should separate them and keep them independent because we use them differently.
Bounded contexts let us split our application into independent parts that maintain their logic and stores. It’s okay to duplicate data between databases in such a case. This may lead to harder maintenance of the source of truth, though. However, this approach will let us optimize the performance, use more appropriate data stores, or even tune the configuration better for specific applications.
Implementation details
Finally, we have implementation details. Each database builds its own best practices or optimization tricks. We can rely on them to improve the performance or to simplify the storage, but we need to keep in mind they may go out of date.
One example is partitioning. Depending on your SQL engine license or version, you may not be able to create partitions in a table. One trick is to use separate tables with year and month encoded in the name, and then wrap all these databases together with a view. This works pretty well and gives us a very similar experience.
However, if we change the license or database version in the future, then this carefully implemented feature will not be needed anymore, because the database will support partitions natively. What’s worse, our hand-crafted implementation may be slower than the native solution. This would not only increase our maintenance costs but also require us to run an expensive migration process in the future.
This scenario happens often and in multiple areas of the application. Whenever we rely on some implementation details, we should wrap them with abstractions that would allow us to migrate to other solutions later on.
Monitoring and observability
Seeing is the key! We need to see the context to troubleshoot efficiently. Each database provides its own tools for monitoring the performance, tuning the indexes, or peeking behind the scenes.
The first area where we need tools is signals. We need to be able to access logs, statistics, and metrics. These tools may be standalone or may integrate with the database provider. They may be enabled automatically if we run in the cloud, or we may need to configure them manually when we run on-premise.
The next area is tuning. Modern databases provide tools for analyzing index usage, suggesting new indexes, or sometimes suggesting how to restructure the database to get better performance. However, these tools are based on the signals that we have currently. They won’t suggest improvements for the access patterns that we don’t have yet which limits their usefulness. We either need to run expensive load tests to identify access patterns, or we go blind.
What’s more, the mentioned tools often lack the understanding of all the things happening around them. They don’t know that the CPU spiked because we had a deployment on some other host and the load couldn’t be distributed evenly. They don’t know if the given circumstances are one of a kind, or if they will repeat tomorrow at the same time. They don’t know if the query was sent manually by the database engineer, or if it was an automated reaction of some other system.
Most importantly, these tools often tell us “what happened” instead of “what we should do”. It’s great to see that the CPU spiked, but is this an actual issue? Should we do something about it? Will it happen again? And - last but not least - how to prevent that from happening? These tools lack the understanding of our system. Understanding only we have.
How can Metis help?
Metis is a platform that answers “what to do” instead of “what happened”. Metis gives the full context of all the things around - deployments, data storage, migrations, access patterns, and actual conditions of the production environment.
The first thing it helps with is answering whether a given query is going to scale in production. Developers can’t learn that until they run expensive load tests or even deploy to production. Metis can analyze the query and provide a quick insight into what may go wrong.
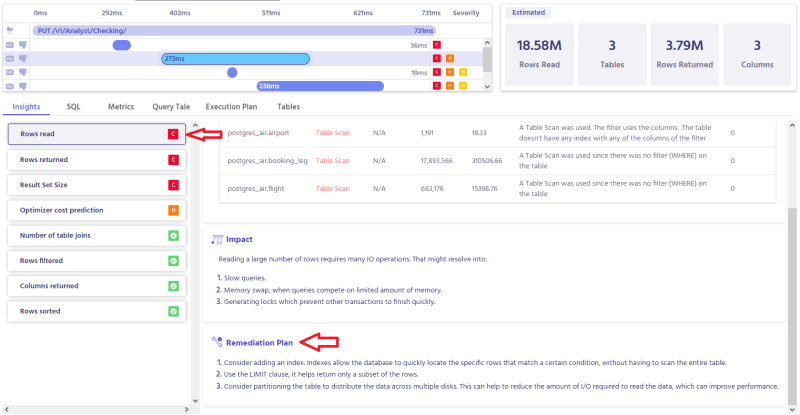
Metis can also analyze things that may take the database down for some prolonged period of time, like migrations:
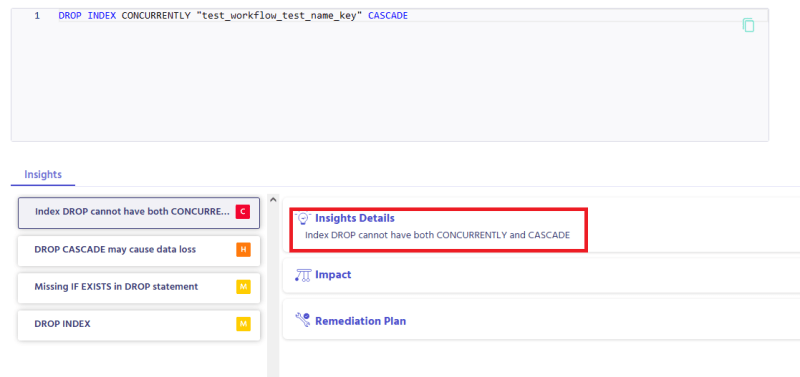
Metis gives you a dashboard that shows all the findings in your database at a glance:

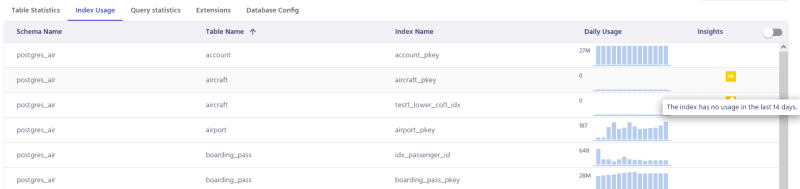
Metis can also analyze the production database to see how things perform over time. For instance, it can identify indexes that are not used anymore:
Metis can analyze your production schema and suggest improvements:

Metis can integrate with your CI/CD pipeline to stop pull requests that would degrade the performance. It allows for ad-hoc analysis, automated insights, and constant monitoring.
Summary
Storing data takes time. We need to understand how to do it efficiently, have a way to monitor the performance and understand the context of all we do. We need tools, we need understanding of internals, and we need to have that automated. Metis does exactly that and is the ultimate solution for database guardrails.

Top comments (0)