
When asked to speed up data processing, often the first thing we do as Site Reliability Engineers, is dive into slow query optimization. However, sometimes that is not enough. This was the case for us at Kenna. Despite optimizing all our slow queries, we still couldn't process data fast enough. In addition, our MySQL database was constantly maxed out on CPU. It was so bad, that even simple requests were a struggle. Before I dive into the details, I first want to give you a little background on Kenna so you have some context for this story.
Kenna Security
Kenna helps Fortune 500 companies manage their cybersecurity risk. The average company has 60 thousand assets. An asset is basically anything with an IP address. The average company also has 24 million vulnerabilities. A vulnerability is anyway you can hack an asset. With all this data it can be extremely difficult for companies to know what they need to focus on and fix first. That’s where Kenna comes in. At Kenna, we take all of that data and we run it through our proprietary algorithms. Those algorithms then tell our clients which vulnerabilities pose the biggest risk to their infrastructure so they know what they need to fix first.
We initially store all of this data in MySQL, which is our source of truth. From there, we index the asset and vulnerability data into Elasticsearch.
In order to index all these assets and vulnerabilities into Elasticsearch we have to serialize them and that is exactly what I want to cover in this post, serialization! Particularly, I want to focus on the serialization of vulnerabilities since that is what we do the most of at Kenna.
Serializing Vulnerabilities
When we first started serializing vulnerabilities for Elasticsearch we were using ActiveModelSerializers to do it. ActiveModelSerializers hook right into your ActiveRecord models so all you have to do is define what methods you want serialize and it takes care of the rest.
module Serializers
class Vulnerability < ActiveModel::Serializer
attributes :id, :client_id, :created_at, :updated_at,
:priority, :details, :notes, :asset_id,
:solution_id, :owner_id, :ticket_id
end
end
It is super easy, which is why it was our first solution. However, it became a less great solution when we started serializing over 200 million vulnerabilities a day. Our vulnerability data is constantly changing and we have to make sure to keep it insync between MySQL and Elasticsearch which is why we have to do so much serialization. As the number of vulnerabilities we were serializing increased, the speed at which we could serialize them dropped dramatically. Soon, we couldn't keep up with the rate at which our data was changing!
In addition, our database began to max out on CPU.
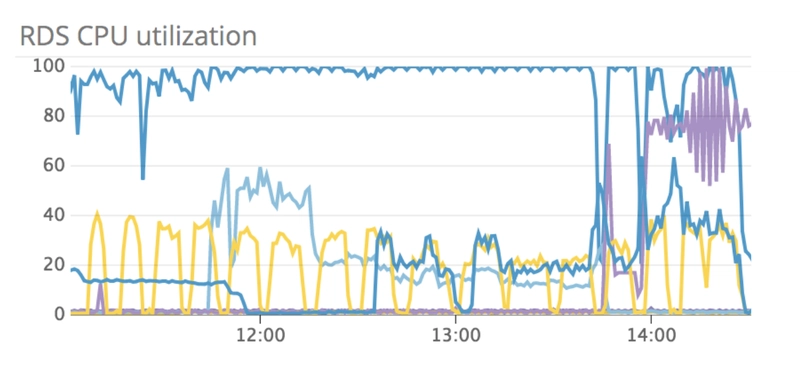
The caption for this screenshot in Slack was “11 hours and counting”. Our database was literally on fire ALL THE TIME! Some people’s first reaction when they see this graph might be to say, why not just beef up your hardware? Unfortunately, at this point, we were already running on the largest RDS instance AWS had to offer so that was not an option. When my team and I saw this graph we thought there has to be a horrible MySQL query in there. So off we went went, hunting for that elusive horrible query.

But we never found any horrible, long running queries because they didn't exist. Instead, we found a lot of fast, milli second queries executing over and over again. All these queries were lightening fast, but we were making so many of them at a time that the database was overloaded. We immediately started trying to figure out how we could serialize all of these vulnerabilities and make less database calls. What if, instead of making individual calls to get data for each vulnerability, we group all of the vulnerabilities together and make a single call to get all the data at once.

From this idea came the concept of bulk serialization.
Bulk Serialization
In order to implement this we started with a cache class that was responsible for taking a set of vulnerabilities and a client and looking up all of the related data in MySQL at once.
class BulkVulnerabilityCache
attr_accessor :vulnerabilities, :client, :vulnerability_ids
def initialize(vulns, client)
self.vulnerabilities = vulns
self.vulnerability_ids = vulns.map(&:id)
self.client = client
end
# MySQL Lookups
end
We then took this cache class and passed it to our vulnerability serializer, which still had all the formatting logic needed to serialize each field.
module Serializers
class Vulnerability
attr_accessor :vulnerability, :cache
def initialize(vuln, bulk_cache)
self.cache = bulk_cache
self.vulnerability = vuln
end
end
end
Except now, the serializer would get the data from the cache instead of the database. Let’s look at an example. In our application, vulnerabilities have a related model called Custom Fields.
class Vulnerability
has_many :custom_fields
end
Before, when we would serialize custom fields, we would have to talk to the database. Now, we could simply read from the cache.

The Result
The payoff of this change was big! For starters, the time to serialize vulnerabilities dropped dramatically. To serialize 300 vulnerabilities individually takes just over 6 seconds.
(pry)> vulns = Vulnerability.limit(300);
(pry)> Benchmark.realtime { vulns.each(&:serialize) }
=> 6.022452222998254
Often, it would take even longer when the database was maxed out. If we serialize those exact same 300 vulnerabilities in bulk...
(pry)> Benchmark.realtime do
> BulkVulnerability.new(vulns, [], client).serialize
> end
=> 0.7267019419959979
it takes less than a second! These speed ups are a direct result of the decrease in database hits we have to make to serialize the vulnerabilities.
When we serialize those 300 vulnerabilities individually we have to make 2100 calls to the database. When we serialize them in bulk, we only have to make 7 calls to the database. You can probably glean from the math that it's 7 calls per individual vulnerability OR 7 calls for however many vulnerabilities are grouped together at once. In our case, we index vulnerabilities in batches of 1000. This means we took the number of database requests we were making from 7k down to 7 for every batch.
This drop in database requests is easy to see in this MySQL queries graph. The graph shows the number of queries being issued BEFORE and AFTER we deployed the bulk serialization change.

With this large decrease in queries also came a large drop in database load which you can see in this RDS CPU utilization graph.

Lesson Learned
The moral of this story is when you are processing large amounts of data try to find ways to process that data in bulk. We did this for serialization, but the same concept can apply anytime you find yourself processing data in a one-by-one manner. Take a step back, and ask yourself, could I process all of this data together? Because one database call for 1000 IDs is always going to be faster than 1000 individual database calls.
If you are interested in other ways to prevent database hits using Ruby checkout my Cache Is King speech from RubyConf which is what inspired this post.

Top comments (4)
Hi Molly, if you don't mind me asking: why were vulnerabilities read from MySQL and then serialized to Elasticsearch continuosly? Is it data with high volatility? Do they keep changing?
I'm not sure if what you're describing is a one off (moving in bulk tens of millions out of mysql to elasticsearch) or else.
I guess what's not clear to me is the initial problem :)
Great question! The answer is high volatility, they are constantly changing. On average, we update 200 million vulnerabilities a day in MySQL and every time one of them is updated in MySQL we have to sync the changes to Elasticsearch. I added an extra sentence to help make that more clear.
Hope that helps! Let me know if it is still not clear! Thanks!
😱
A lot of stuff to do for job workers I guess!
Ah ah no now it's totally clear, thanks! I don't want to know how much you spend in bandwidth between MySQL and Elasticsearch :D
lol TBH, despite quadrupling in size over the past year and half, thanks to a lot of optimizations in Ruby and with Elasticsearch, we use a lot less resources than we did a year ago. The scale has really pushed us to work smarter with all our data, rather than brute forcing all the processing. Scale is one of the best teachers!