
Redis is all about speed. But just because Redis is fast, doesn't mean it still doesn't take up time and resources when you are making requests to it. Those requests, when not made responsibly, can add up and impact the performance of your application. Here is the story about how Kenna learned this lesson the hard way.
Hiding in Plain Sight
One of the largest tables in Kenna's database is vulnerabilities. We currently have almost 4 BILLION. A vulnerability is a weakness which can be exploited by an attacker in order to gain unauthorized access to a computer system. Basically, they are ways a company can be hacked.
We initially store all of these vulnerabilities in MySQL, which is our source of truth. From there, we index the vulnerability data into Elasticsearch.
When we index all of these vulnerabilities into Elasticsearch, we have to make requests to Redis in order to know where to put them. In Elasticsearch, vulnerabilities are organized by client. In order to figure out where a vulnerability belongs, we have to make a GET request to Redis to fetch the index name for that vulnerability.
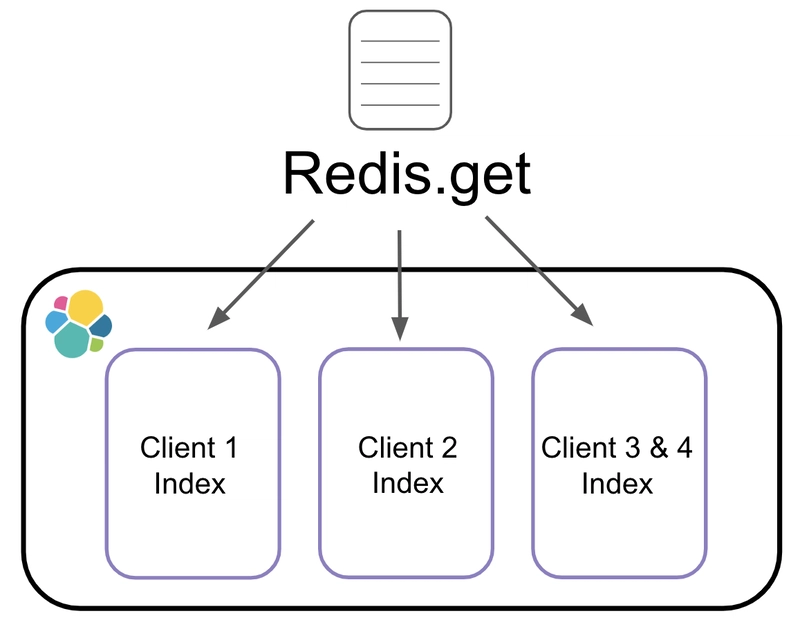
When preparing vulnerabilities for indexing, we gather all the vulnerability hashes up. Then, one of the last things we do before sending them to Elasticsearch, is make that Redis GET request to retrieve the index name for each vulnerability based on its client.
indexing_hashes = vulnerability_hashes.map do |hash|
{
:_index => Redis.get("elasticsearch_index_#{hash[:client_id]}")
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
Those vulnerability hashes are grouped by client, so that GET request
Redis.get("elasticsearch_index_#{hash[:client_id]}")
is often returning the same information over and over again. All these simple GET requests are blindly fast. They take about a millisecond to run.
(pry)> index_name = Redis.get("elasticsearch_index_#{client_id}")
DEBUG -- : [Redis] command=GET args="elasticsearch_index_1234"
DEBUG -- : [Redis] call_time=1.07 ms
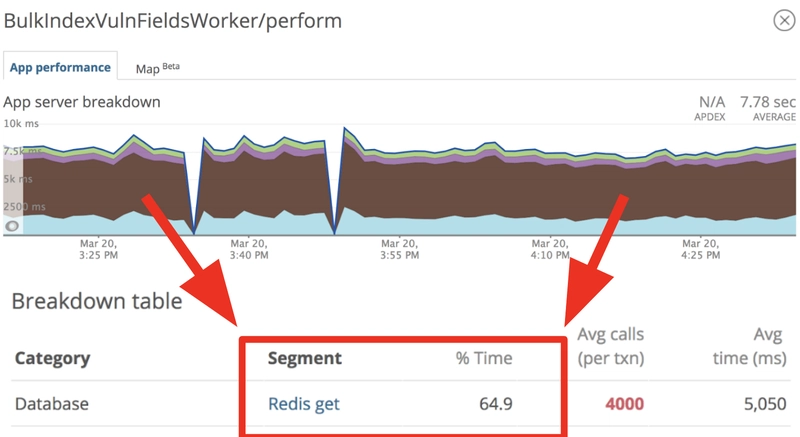
But it doesn't matter how fast your external requests are, if you are making a ton of them it is going to take you a long time. Because we were making so many of these simple GET requests, they were responsible for roughly 65% of the runtime for our indexing jobs. You can see this stat in the table below and it is represented by the brown in the graph.
The solution to eliminating a lot of these requests was a local Ruby cache! We ended up using a Ruby hash to cache the Elasticsearch index name for each client.
client_indexes = Hash.new do |h, client_id|
h[client_id] = Redis.get("elasticsearch_index_#{client_id}")
end
Then, when looping through all of the vulnerability hashes to send to Elasticsearch, instead of hitting Redis for each vulnerability, we would simply reference this client indexes hash.
indexing_hashes = vuln_hashes.map do |hash|
{
:_index => client_indexes[hash[:client_id]]
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
This meant we only had to hit Redis once per client instead of once per vulnerability.
The Payoff
Let's say we have 3 batches of vulnerabilities that need to be indexed.
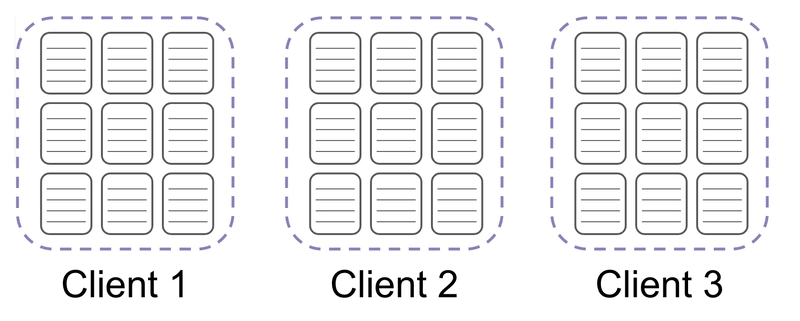
In the case of these three batches, no matter how many vulnerabilities we have in each batch, we will only ever need to make a total of 3 requests to Redis. These batches usually contain 1k vulnerabilities each, so this change decreased the hits we were making to Redis by 1000x which led to a 65% increase in job speed.
Even though Redis is fast, using a local cache is always going to be faster! To put it into perspective for you, to get a piece of information from a local cache is like driving from downtown Chicago to O’Hare Airport to get it.

To get that same piece of information from Redis, is like taking a plane from Chicago and flying all the way to Boston to get it.
Redis is so fast that it is easy to forget that you are actually making an external request when you are talking to it. Those external requests can add up and have an impact on the performance of your application. Don't take Redis for granted. Make sure every request you are making to it is absolutely necessary.
If you are interested in other ways to prevent database hits using Ruby checkout my Cache Is King speech from RubyConf which is what inspired this post.

Top comments (12)
Are indexes guaranteed to never change once created? If Redis goes down and has to be rebuilt will the resulting KV store be the same? Basically, is it possible for the client cache to become stale?
While I sometime consume data from Elastic though other tools I've never had to actually use it and am not familiar with its implementation, so forgive me if these are "no, DUH" questions.
Great questions!
Indexes can change, but it is not common. We shuffle data maybe once or twice a year depending on growth. For the most part, once an index is created it will not change. Sometimes we have a couple clients on a single index and a client will get too big so we have to move them to a new index. When we do that we use what we call index aliases. These allow us to name the indexes whatever we want and reference them by standard names.
For example: Say I have an index named
index_a. If I want to store client 1, 2, and 3 on that index I would give it three aliases,client_1_index,client_2_index, andclient_3_index. Then any time I make a request toclient_1_indexElasticsearch knows I meanindex_a. This allows us to move data around and when the data transfer is complete we simply point the alias at the new index.For Redis, we use Elasticache on AWS, so it has a replica in case our main instance fails which is helpful. However, if Redis did completely go down, we would still survive. The Redis values are populated by a request to Elasticsearch. If Redis went down that would mean rather than fetching the values from Redis, we would have to talk to Elasticsearch to figure out where to put the vulnerability. This means more load for Elasticsearch, which we would not want long term, but we could handle it for a short period.
When we store the keys for the index_name for a client, we set an expiration of 24 hours on them. This just ensures that if a client gets removed we dont have keys hanging around forever. Otherwise, since we are just moving the aliases around and and those basically never change the cache's don't ever go stale. If for some reason we needed to update an alias we would manually bust the cache for that client.
Hopefully I explained that clearly! If not please let me know and I will take another whack at it 😃
So the cached data can change, but extremely rarely and you control when it changes. You have a method to patch the cache using aliasing. And even if everyone drops the ball you have an expiry rule of 24 hours so the worse case scenario is that some people would have the wrong data (or no data) for at most a day.
Cool, got it.
PR approved 😄
You got it! We have guards in place so its never wrong data(bc that would be bad!), worst case it would be no data 😊
Of course I am not familiar with the whole problem as you are. But, I am wondering if using aliases was enough in this case without the need of storing index names in Redis.
Then if you need a specific document you just request it using the alias and not the index name.
We actually store the alias names in Redis. The index names are never referenced anywhere in our application. We could have stored them in MySQL on each client but we choose Redis because it was fast and if we ever needed to update one it was as simple as just busting the cache.
Did you consider just using RediSearch?
Great overview! Also nice to see someone else using a very similar implementation to what I’ve used in the past for fairly long lived data - did you have to worry about hash tags / slots for multi-deletes in your cache busting strategy? I had some headaches with that when first moving to clustered mode...
We never ran into any issues with hashtags or multi deletes, we have run into issues with large key deletes but those are a thing of the past now with Redis 4 which will handle them async.
A cache within a cache within a cache. An inception of caches.
Good work! Quite a lot of $$$ saving as well ;)
Thanks 😃
Was talking with some Netflix engineers who said they use Redis waaay beyond it's intended use because it was just so easy and fast. LOLz!