
Gathering and cleaning data are two steps present in every Data Analysis and Data Science process there is. Depending on the source you look at they're broken down slightly differently, but they're always there. Analytic Steps categorizes them as:

- Determining the Objective
- Gathering the Data
- Cleaning the Data
- Interpreting the Data
- Sharing the Results
Data Pine says:
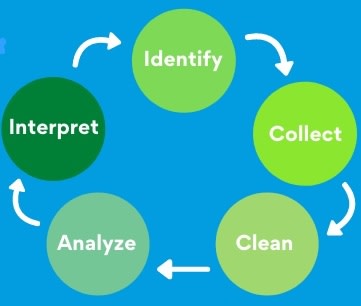
- Identify
- Collect
- Clean
- Analyse
- Interpret
And according to Google, there are six steps:
- Ask
- Prepare
- Process
- Analyse
- Share
- Act
Though all of these use slightly different words, they preach the same concept:
- Find out what you really want to do or discover
- Find the data that will help you get there
- Make sure the data is in shape to be modelled and visualised
- Model and visualise it
- Share your findings and take action based on them
The Data Science process is very similar to the Data Analysis one. We make sure to understand the problem, collect and clean the data, explore it, build models and deploy them. And what's the most important part of this? If you ask a data scientist you're likely to have 'modelling' as your answer. The issue is, the most exciting part for a data scientist is usually the model building and deploying. We love tweaking and running different models, getting a little percentage increase in our accuracy or precision, or whichever other metric we chose to use. I am definitely guilty of spending much more time in the model building phase than in any other phase. It feels more exciting and challenging. We're doing what really matters in the process, right?
Well, yes. But that's not all.
Albert Einstein once said, “If I were given one hour to save the planet, I would spend 59 minutes defining the problem and one minute resolving it.”. If we apply that to the data science process, that would be the first part 'Make sure you understand the problem'. I could go on on how this is another undervalued part of the process, but I want to start talking about what I think is given even less thought now: the Data.
Garbage In, Garbage Out

This popular expression from the early days of computing still holds true. It doesn't matter how advanced your machine learning model is, and how much data it is capable of incorporating. If that data is 'bad', then your result will not be representative of what you think it is. This is something that is completely overlooked a lot of the time in data science, from schools to actual jobs (and a few competition websites out there). Oftentimes we're just presented with a dataset and told to work with it. There's no critical examination of where the data came from, or how it got there.
How can we solve this issue? First, we should all have an understanding of what 'bad' data is.
Bad Data
- Improperly Labelled Data
Labelling data can be a tedious and time consuming job, but if you want your models to make correct predictions, it needs to be done properly. If your model was fed data labelled incorrectly, and it uses that information to make it's predictions, those predictions will most likely be wrong.
- Not Enough Data
Models need data. A lot of it. And I'm not talking of a few hundred, or even a few thousand data points. To build advanced and accurate models, you may need millions of examples. Imagine if your 'Is it a cat or a dog' model only had a few hundred images of a few different cat breeds. If we challenged it with a breed it has never seen, it might suffer to make accurate predictions.
- Untrustworthy Data
For our capstone project at Flatiron school we had to not only pitch the project we wanted to do, but also find a dataset that would allow us to accomplish that project. I chose to make a Fake News Classifier, and pitched a dataset I found on Kaggle for it. My instructor was quick in turning it down. It had no information on how that data was acquired, how it was labelled, and I had no means of verifying it. With some more research done I found the Liar dataset, which contained thousands of data points, humanly labelled by editors from politifact.com using a truthiness scale and which contained extensive metadata on each instance, making it verifiable. Once I settled on my final model, I decided to train a version of it on the rejected dataset, just for curiosity. The Accuracy it provided for the test data from that dataset was way higher than the one trained in the Liar dataset. Why was that? The model wasn't actually making correct predictions, it was just better at identifying the labels (which were not verified) from the dataset.
- Dirty Data
This should go without saying already, but your data should be properly pre-processed. This step is the most time consuming for a data scientist, who spends on average 60% of their time cleaning data. Considering that 76% of data scientists find this the 'least enjoyable part of their work' according to the research linked above, one understands why sometimes it's not done properly. That's not an excuse though. Your dirty data will lead you to an unreliable model.
- Biased Data
This is something that is much harder to achieve without the proper tools. When using data we must understand not only where it comes from, but how it was collected, by whom, how the sample was selected, amongst many other variables. Contextuality here is key. If my Fake News Classification project used data labelled only by a certain political party, then it could end up being biased towards classifying that party news or statements as true, while other parties could have a much higher chance of being labelled as false. Having an unbiased technique to collect data, from an unbiased sample, and use unbiased labels on them, is a hard task, but essential to have a trustworthy model.
Good Practices

To ensure the data you're using is reliable, you have to incorporate some practices in your model development pipeline, straight from the beginning. Ask yourself these questions:
- Is the data Reliable?
This can be hard to assess, but can be achieved by comparing the results to other sources. Unreliable data can lead to incorrect decisions.
- Is the data Original?
Can you validate the data with the original source? How does it compare to other datasets?
- Is the data Comprehensive?
Is this a complete dataset? Is it meaningful to what we want to accomplish? Is there enough data? Gaps in the dataset, like lots of people not answering 'age' in a questionnaire for instance, can make you unable to fully understand your data.
- Is the data Current?
When was this data acquired? Can the lack of recent data lead to biased models? Outdated data can lead to models that don't reflect the current reality.
- Is the data Cited?
Is it and its authors formally recorded and acknowledged?
If you can confidently answer all those questions in a positive way, then your data has a much higher chance of having good data quality.
Where to find data?

There are many places where you can find good datasets. I'll list a few here, in no particular order, but be sure to always perform the necessary checks to evaluate their reliability.
Awesome Public Datasets; UCI Machine Learning Repository; Recommender Systems and Personalization Datasets; The Stanford Open Policing Project; Labor Force Statistics from the Current Population Survey; Unicef Data; Climate Data; National Centers for Environment Information; Google Cloud Healthcare API public datasets; WHO Data Collections; USA Census Bureau; US Government Open Data
I can't find the data I need. What to do?
What can you do if the data you're looking for simply doesn't exist? You either find a proxy for the data you don't actually have, or you create your own dataset. Have a survey, study or questionnaire made, and find a representative and unbiased sample of the population you're targeting. If the study is too big, or you have difficulty setting the parameters for it, there are research services available like Prolific that recruit niche or representative samples on-demand and builds the most powerful and flexible tools for online research. They're doing great work connecting researchers with good quality data, which is a terribly important job.
Conclusion
Don't skip steps. It's as simple as that. Incorporate the Data Analysis and the Data Science process into your projects pipelines and actually go through them. Make sure you properly verify your data. Trust me, you'll be much more satisfied with your high Accuracy score when you are confident that the score is actually correct.

Top comments (0)