In continuation to my previous blog post, this is the final blog regarding the acronyms every beginner in software engineering should know. Hope you find this helpful.
1. AJAX - Asynchronous JavaScript and XML
Is a new methodology of using existing technologies like HTML (Hyper Text Markup Language) or XHTML (Extensible Hypertext Markup Language), CSS (Cascading Style Sheets), JavaScript, DOM (Document Object Model), XML (Extensible Markup Language), XSLT (Extensible Stylesheet Language Transformations) and the XMLHttpRequest object. When these technologies are used in they allow web applications to make incremental changes to the user interface without reloading the entire browser page. A simple example that most of us have seen in social media websites like facebook, wherein if you scroll the page in the browser it fetches new data without reloading the entire web page.
https://thepracticaldev.s3.amazonaws.com/i/6nmd73fcez7qduilh0gu.jpg
2. BASH - Bourne Again Shell
The Bourne shell or sh is a basic shell i.e. a small program with few features. The Bourne shell is not a standard shell but it is still available on every Linux system for compatibility with UNIX programs. Bourne Again Shell, on the other hand, is the GNU standard shell, intuitive and flexible. On Linux, bash is the standard shell for common users. It is a super-set of the Bourne shell which contains some more add-ons and plugins. Bourne Again Shell is compatible with Bourne Shell but the reverse is not true.
3. BAT - Batch File
A batch file is similar to the shell script in Linux. But it is compatible with DOS, OS/2 and Microsoft Windows. It is made up of sequence of commands to be executed by the command-line interface, stored in a plain text file. They are used to automate everyday tasks thereby reducing the time required. The term batch arises from batch processing, meaning non-interactive execution.
https://thepracticaldev.s3.amazonaws.com/i/hpj8eyhhwx29u6yyx29d.png
4. CLI - Command Line Interface
A Command Line Interface is a command line program that accepts text input to execute operating system functions. Before the arrival of the mouse, CLI’s were the only way to interact with computers. Today most users use GUI or Graphical User Interfaces and rarely use CLI. However, CLI is used by software engineers and system administrators to configure computers, install software and access features not available in the GUI (Graphical User Interface).
5. CRUD - Create, Read, Update, Delete
In software engineering CRUD stands for Create, Read, Update and Delete which are the basic functions of persistent storage or database. When we are creating API’s we want the models to provide all these four functionalities. The model must be able to create a new resource, read which returns the resource if already created, update an existing resource and delete any existing resource.
https://thepracticaldev.s3.amazonaws.com/i/31726jjyi87cnjmi7hm6.jpg
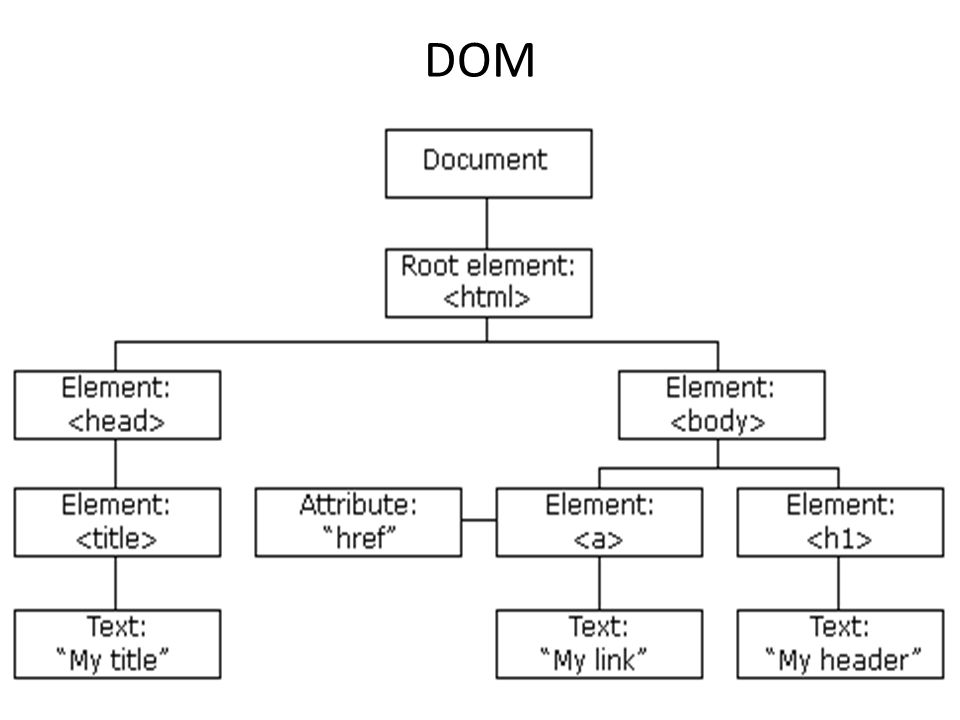
6. DOM - Document Object Model
It is a cross-platform and language-independent application programming interface that treats an HTML (Hyper Text Markup Language), XHTML (Extensible Hypertext Markup Language) or XML (Extensible Markup Language) as a tree structure where each node is an object representing a part of the document. DOM represents a document with a logical tree. Each branch of the tree ends as a node and each object contains objects. DOM methods allow programmatic access to the tree, which makes it possible to manipulate the document structure, style or content. Nodes can also have event handlers attached with them, which are executed when an event is triggered.
7. JIT Compilation - Just In Time Compilation
A JIT compilation is a way of executing computer code that involves compilation during execution of a program - at runtime as opposed to prior to execution. To understand this we need to understand the role of compilers and interpreters. Compilers and interpreters both convert the code from human-readable form to machine code, what differs is the way they operate. A compiler converts the code into computer’s native language up-front well before the program is even run. Some compiled languages include C, C++, Scala etc. On the other hand, interpreter converts the code from human-readable form to machine code one line at a time. Some common interpreted languages are JavaScript, Java, Python etc. JIT compilers are not just next-gen compilers, they don’t just run the code but they improve it over time. JIT compilers take the source code and convert it into an intermediary “assembly language”, which can then be pulled from when needed. Assembly code is interpreted into machine code on call-resulting in a faster translation of the code that you need. JITs monitor and optimize while they run. By identifying the parts of the code that are used more frequently then the others they are able to refine frequently used instructions and make them run in the future. Java has a JIT as a part of JVM, and Android has a JIT in it’s Dalvik Virtual Machine.
8. LTS - Long Term Support
LTS stands for Long Term Support. You may find these term associated with most of the open-source software. For example, Node.js versions like 10.13.0 LTS or Ubuntu 18.04.1 LTS etc. LTS means that the released piece of software will be maintained for a longer period of time. For example in terms of Ubuntu, a new Ubuntu Desktop and Ubuntu Server release every 6 months, whereas a LTS is released every 2 years. And a LTS has a support period of 3 years support for Ubuntu desktop and 5 years for Ubuntu Server. It’s advisable to use LTS versions in production.
9. DRY - Don’t Repeat Yourself
DRY stands for Don’t Repeat Yourself is a basic software development principle to avoid duplication of code. The advantages DRY bring is the maintainability, readability, reusability, and testing. Unit testing becomes a lot easier when you use the DRY approach.
https://thepracticaldev.s3.amazonaws.com/i/i73wcrwsdev2xi8avzka.png
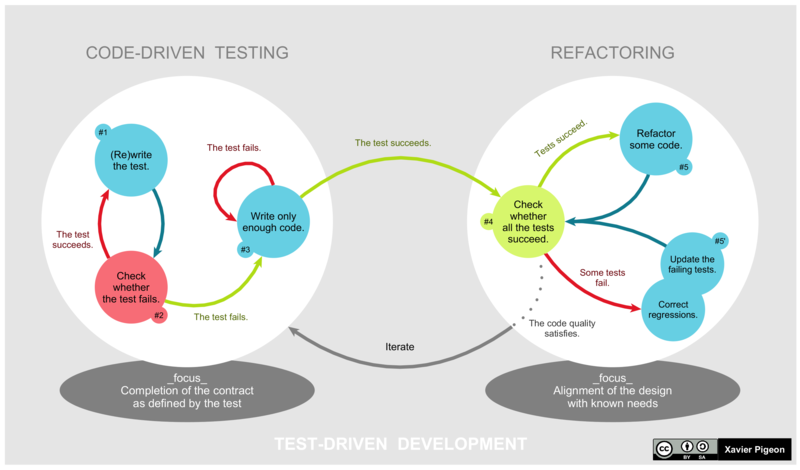
10. TDD - Test Driven Development
Test Driven Development is a software development process in which each requirement is turned into very specific test cases, then the software is improved to pass the new tests only. Following is a sequence of steps for test-driven development:
- Add a test: Each new feature starts with writing a test. To write the test the developer should completely understand the feature's specification and requirements.
- Run new tests for failure: Run the new tests and check whether they all fail, which is the expected behaviour since there is no code for the test cases written.
- Write the code: In this step, we write the code to pass the tests. Even though all the test cases pass, the code may not be perfect or optimized. However, this will be improved in step 5 when we refactor the code.
- Run all tests for success: In this step, all test cases are executed, and if all test cases pass this gives confidence to the developer that the new feature does not break any existing parts of the system. If the new code changes break any existing part of the system then the new code must be adjusted till all the test cases pass.
- Refactor code: In this step, the new code is refactored i.e. it is examined for duplication. It is in this step that the Object, class, variable and methods are named clearly to make the code readable and also clearly represent their purpose. Applying design patterns if necessary is done in this step. The developer continually re-runs the test while refactoring the code and this gives him confidence that the changes are not affecting the existing functionality.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Top comments (1)
Nice! I did better this time around compared to the previous post. I was able to recognize more than half of the terms.
And for those terms I didn't know, thanks for that, too!