
In selenium XPath is a very important strategy to locate elements. It can be simple as well as complex at the same time if you did not grab it correctly.
Topics to be covered in this article.
What is XPath and XML Document?
Syntax of the XPath
Syntax Demo
Types of XPath
Tips to follow
What is XPath and XML Document?
XPath (also called as XML Path) is a technique to locate elements in Selenium. It consists path expression along with some conditions.
Now lets see how a XML Document looks like.
<mobileshop>
<mobile category= “samsung”>
<model lang=”en”>Note 10</model>
<manufacture>samsung</manufacture>
<mobile>
<mobile category= “apple”>
<model lang=”en”>iphone11</model>
<manufacture>apple</manufacture>
<mobile>
As you can see here mobileshop node has a child node mobile and its futher followed by attribute called category and its value as samsung.
This mobile node has two child nodes which is model and manufacture.
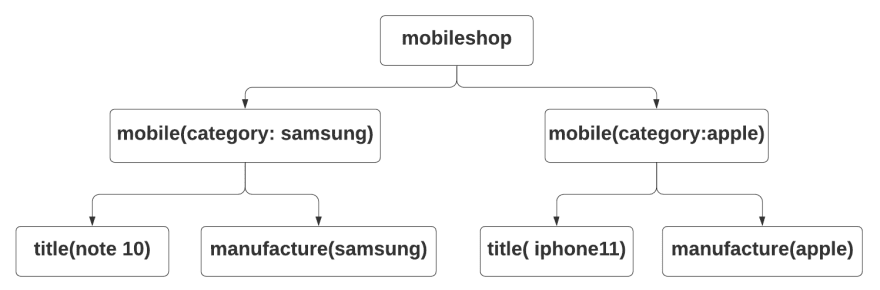
If we write the XPath to locate the title of the mobile we have to write it like this.
Xpath = /mobilestore/mobile[@category='apple']/title
So this is how we write our XPath.
Syntax of the XPath
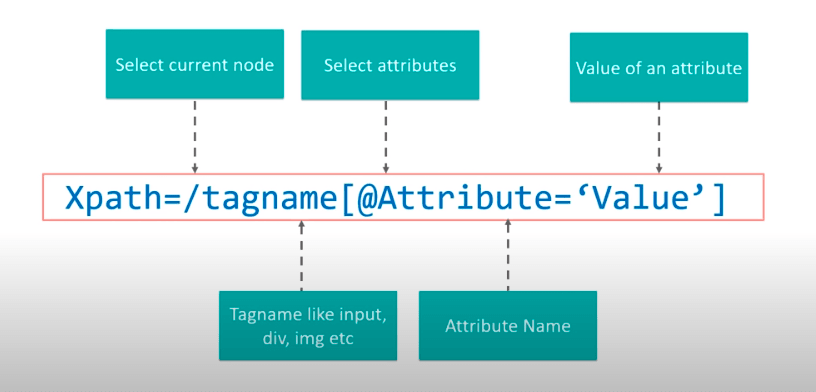
Syntax Demo
lets go to the google.com and we can see the google search box. So we are going to create the Xpath to this google search box.
Do a right click on the search box and open the developer console. You will now see the particular area for the selected node.
<input class="gLFyf gsfi" jsaction="paste:puy29d;" maxlength="2048" name="q" type="text" aria-autocomplete="both" aria-haspopup="false" autocapitalize="off" autocomplete="off" autocorrect="off" autofocus="" role="combobox" spellcheck="false" title="Search" value="" aria-label="Search" data-ved="0ahUKEwj9q8C8ydfwAhWG63MBHbWRDSMQ39UDCAQ">
As you can see it have a name attribute inside the input tag. So we are going to use it to create our Xpath.
In the console press CTRL + F and the area will come up to test our xpath.
//input[@name='q']
When you enter this path you will see it highlighting the element. This is the way of catching any element using Relative Xpath.
We can identify elements using Absolute Xpath also. To Absolute path of the same element you can just right click on the input tag and copy the Xpath.
/html/body/div[2]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input
In absolute Xpath we start from the very first root node and go all the way until the element on the web page.
As a best practice its not recommended to use absolute path because this can break if you have any changes in your web application.
On the other hand Relative Xpath have very less chances of breakage and we can also locate a element using two attributes in Relative Xpath.
And incase if we do not know the tag name we can replace it by * sign.
//input[@type='text'][@name='q']
//*[@type='text'][@name='q']
XPath Functions
Now lets talk about few functions that can be used with Xpath.
Lets take ikman.lk as the example site.
contains()
This is a method used in Xpath expression when the value of any attribute changes dynamically.
Lets take the vehicle section of the ikman.lk site. If we write the XPath to this element it should look like this.
//span[@class=’ui-sprite categories-36 vehicles’]
In a situation that this class path is changed we cannot track the element using class attribute. In this case we can use contain() function
//span[contains(@class,’vehicles’)]
You see now we just mentioned ‘vehicles’ inside the contains() class and its working.
That because its only searching for the word vehicle in this scenario. So if any of the word changed in the class it does not affect to identify the element.
text()
This expression is used to locate element with the exact text. Lets have a example.
If we go to the vehicle section text area we can see it mentioned “Vehicles”.
<span>Vehicles</span>
So we can use text() function to locate this element. It says go anywhere in the page and does not matter where you go but it should have a text whose value is “Vehicles”.
//*[text()='Vehicles']
starts-with()
This one is very useful when we have some elements, some part of the value is common but the other part is always changing.
For example lets take ikman.lk login page where you have to enter your email and password to login.
Email box:
<input id="input_email" name="email" aria-label="Email" type="email" class="input-field--3A-bW themed-form-input--2Q2dw input-field-error--2NJwO" placeholder="Email">
Password box:
<input id="input_password" name="password" aria-label="Password" type="password" class="input-field--3A-bW themed-form-input--2Q2dw" placeholder="Password">
You can write the xpath this way. In this its match the starting text of the attribute that is used to locate an element which have both “email” and ”password”.
//input[starts-with(@id,’input’)]
or / and
Lets say we have two input tags whose attributes are different. So to uniquely identify each input tag we can use or/and functions.
Lets take the same example above.
This will give only one input tag which is name=“password”
//input[starts-with(@id,'input') and @name='password']
//input[@id='input_password'] | //input[@name='password']
This will give two input tags which is name=“password” and name=“email”
//input[starts-with(@id,'input') or @name='password']
For your reference find my GitHub project here
Tips
If you are using Firefox or Chrome for test automation there are some extensions to identify XPath automatically. you just need to add the extension to your browser.
https://chrome.google.com/webstore/detail/chropath/ljngjbnaijcbncmcnjfhigebomdlkcjo/related

Top comments (0)