
A hash map, also known as a hash table, is a data structure that enables fast and efficient lookup, insertion, and deletion of key-value pairs.
Because of their reliability hash tables are used in database indexing, caching, programming compilation, and many more places
Think of a hash table as living in a gated community where each home has an address(key) and the home as the value, if you want to get to a particular home you go straight to the address, getting the value is independent of the size of the hash table
how is data stored into the hash table?
The key is transformed into an index that points to a memory address, this is done by a hashing function.
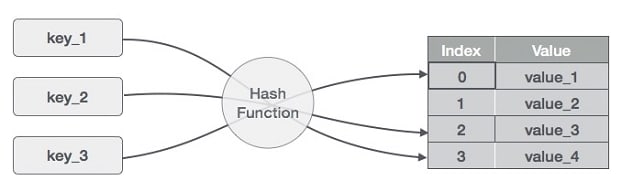
There are different hashing functions that can be used.
The most straightforward hashing function works by (if the key is a string) converting each character into an ASCII value and then summing it. once you get the sum you divide the number by the size of the hash table getting the remainder.
The remainder is then used as the index for that value
Another hashing function is the folding method, in this function, the key is divided into equal parts then added together, then divide by the size of the hash table getting the remainder and index
one issue usually comes with hash functions : collusions
This occurs when a hashing function returns an index that has already been assigned a value.
there are two ways that are used to address this occurring issues.
- open addressing
- chaining/closed addressing
open addressing
when the hashing function returns an index that is already in use it moves to the next position, and checks if is empty. if empty it takes that space else it continues moving to the next position till it finds an empty space
This is referred to as linear probing

This introduces another issue where values are not equally distributed in the hash table.
New methods for finding an empty space have been created to try and solve this second issues which they include:
- plus 3 rehash
- quadratic probing
- double hashing
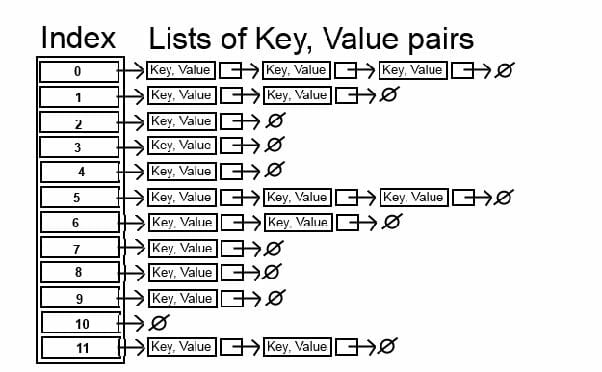
chaining/closed addressing
This deals with collusion by making the index a pointer to a linked list, if an index is duplicated it's just added to the linked list.
Popular programming languages such as Python, JavaScript, c++, and Ruby use chaining in their hash functions
Even though generally hash tables are fast, the performance of a hash table is highly dependent on the quality of the hash function.
what are some of the factors to consider when creating the perfect hash function ?
- minimize collusions
- uniform distribution of hash values
- easy to calculate
- resolve any collusion
If you would like to know more about optimizing the hash function here is a video that I found useful, even though at points in the video I was just hearing him speaking in tongues :)
Conclusion
Hash tables are an efficient data structure that allows for fast data retrieval and insertion by using a hash function to map keys to indices in an array. They have a constant average time complexity of O(1) for insertion, deletion, and retrieval operations, making them ideal for storing and accessing large amounts of data quickly. Hash tables can be implemented in a variety of programming languages and have numerous applications in areas such as databases, search engines, and cryptography. However, the efficiency of a hash table may be affected by collisions, which can be mitigated through various collision resolution techniques. Overall, hash tables are a valuable tool for optimizing data access in software development

Top comments (0)