The two biggest problems a network engineer will face are changes and loops.
In our Cisco exams, an overwhelming majority of the educational content is on methods of preventing loops, and for good reason. Unfortunately, the methods we use to prevent loops are highly complex - and if we partially understand these concepts, the risk is then transferred to changes , where we modify loop prevention mechanisms for a variety of reasons in the datacenter:
- Adding new servers
- Adding new networks to accommodate workloads
- Adding new hardware to accommodate the addition of new servers and workloads
- Adding new interconnects because the previous operations were so successful that new sites are now required
I'm sure many have said, "Make it Layer 3!" as if that's some form of easy fix that will magically remote datacenter reliability issues. The reality is that improperly Layer 3 networks can be just as unstable as Layer 2 ones, if not more so. To make it worse, you may not be able to accommodate your workload needs, causing the business to fail.
First, let's cover what network designers mean by Layer 2 or 3, as it violates the OSI model. In short, it is a reference to port configuration and whether or not Layer 2 loop prevention mechanisms are in play.
Layer 2
Layer 2 network provisioning is probably the easiest to configure, and the least scalable. Most typical systems administrators won't have any issues deploying a workable small-scale Layer 2 network on their own - and probably have experience doing so.
Layer 2 network configuration involves the creation of a VLAN, which in turn instantiates a loop prevention process of some kind, like:
- Per-VLAN Spanning Tree (PVST)
- Per-VLAN Rapid Spanning Tree (PVRST)
- Multiple Spanning Tree (MST) https://en.wikipedia.org/wiki/Multiple_Spanning_Tree_Protocol
- FabricPath https://www.cisco.com/c/en/us/solutions/data-center-virtualization/fabricpath/index.html
- TRILL https://en.wikipedia.org/wiki/TRILL_(computing)
Oddly enough, TRILL can actually be configured to conform to a Spine and Leaf spec. I won't discuss that here - I'll get into why later.
Layer 3
Layer 3 network provisioning is much less flexible, but can also be much more stable and scalable. In this case, Layer 2 loop prevention may be in play, such as with SVIs, but is not the primary or mandatory source of loop prevention. Instead, routing protocols and potentially redistribution are used, each with their own hazards:
- RIP and split horizon https://en.wikipedia.org/wiki/Split_horizon_route_advertisement
- OSPF, EIGRP, and redistribution problems (entire books, but also https://www.cisco.com/c/en/us/support/docs/ip/enhanced-interior-gateway-routing-protocol-eigrp/8606-redist.html)
- eBGP and AS-Path problems https://www.juniper.net/documentation/en_US/junos/topics/usage-guidelines/policy-prepending-as-numbers-to-bgp-as-paths.html
- iBGP and everything
Again, this is all just to prevent loops. Most network designs do a good job of preventing loops in the ways listed above but at the cost of making change riskier by tightly coupling networks to specific devices. As we know, tight coupling is a big negative with high change frequency.
The goals
To design a highly reliable, highly mutable, and highly maintainable network, a network designer must meet the following goals:
- Prevent loops reliably and automatically
- Allow for frequent, preferably automatic additions and removals of new networks
- Be easy to maintain, fix and troubleshoot
- Do all of the above, but with a minimum number of changes, to a minimum number of devices
Enter Spine and Leaf
Introduced in the 1950s by Charles Clos (details here), Clos networking is a mathematical model for non-blocking multistage circuits. This is a lot to unpack:
- Non-Blocking: Nearly all Layer 2 loop prevention mechanisms will prevent loops by refusing to forward on secondary or n-scale paths. Telecommunication companies don't really like this, as this reduces available bandwidth (and therefore revenue) by half. Non-blocking indicates that all available ports are able to forward at all available speeds.
- Multistage: Nearly every datacenter network has more than 6 network ports. As a result, we need the ability to scale beyond a single integrated circuit or network device.
Today, we have a few more technological advances than in the 1950s. Most datacenter network switches leverage Clos topologies to reduce manufacturing costs, increase reliability, by providing more ports on a switch than a single ASIC can provide by aggregating 4,6, or 8 port ASICs onto a crossbar.
This begs the question, why not layer 1? Since the switch itself is Clos, why not just buy a big switch and call it a day? There are some upsides here:
- One IP to administer, making change easier
- Layer 1 topologies are pretty reliable, and break-fix actions are typically just reseating something
- Layer 2/3 loop prevention isn't required
But when we think about it a second, the downsides are pretty big:
- Unless you use technology such as VSS, VCS, you have no redundancy
- You must always perfectly assess the correct port count for your data center on the first try, leading to massive amounts of waste
- It completely violates rule 4, because you're either changing the entire network or not at all.
Layer 2 Leaf Spine suffers from more or less the same issue but removes the need to always be completely correct with port-count.
Layer 3 Leaf-Spine (L3LS from here on out) leverages only Layer 3 loop prevention mechanisms between network devices - while built in a non-blocking Clos pattern in a 3-stage topology:
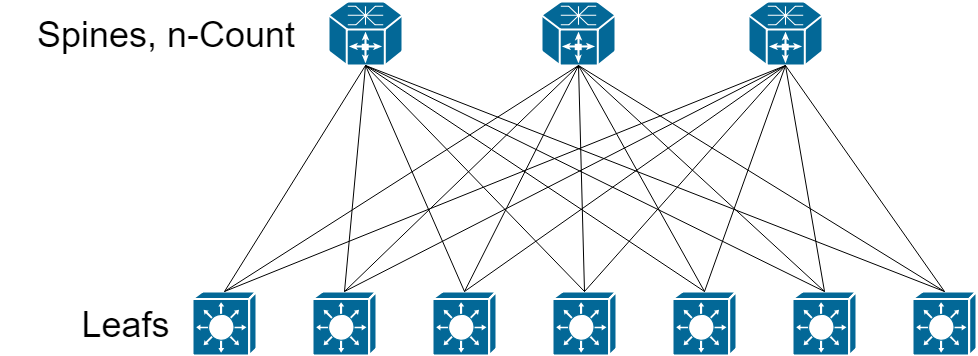
Odd looking, isn't it? Where are the connections between Spines, or behind leafs?
With Clos Networking, crossbars/spines should not connect to each other - it violates rule #4, and leads to blocking circuitry.
Now - this obviously removes all IP portability completely, and forces workloads running on-fabric to participate in routing on at least some level, because Leafs aren't aware of each other directly, but has certain reliability gains:
- Imagine if you could do ASIC-level troubleshooting internal to a switch
- Now imagine if you, as a network engineer, could do this without having to learn how to do ASIC-level troubleshooting. Instead, routing protocols that are familiar to you are your interface into the fabric
- Now imagine that all failure domains are constrained to the individual ASIC you're working on and won't have higher repercussions to the switch
Pretty big upsides, right?
So here's where we need to diverge a bit, due to what I mentioned here. There are quite a few ways to deploy Spine-and-Leaf networks, and nearly all are highly reliable. Some are even used as production networks!
Humor set aside - the usability problem is a big one. My recommendation and the order of this series of blog posts would be to choose whatever platform, protocols, and administration methods best suit your organizational needs, 'cause they all work. Even RIP.
Before we move on, I'd like to cover some fairly serious problems I've seen when discussing the use of L3LS in the datacenter. I apologize for the length but there is a lot to cover here. The statements listed below are misconceptions that I've seen kill adoption of this technological principal.
- L3LS is expensive: This is just flat out wrong. Generation 1 Catalyst 3560s with routing licensed can run it. All you need is layer 3 switching. While this is expensive in some cases, product selection can help a bit. Even older Layer 2-only datacenter switches cost quite a bit when compared to newer 10/25g switch options. If your department can afford new, unused 10 gigabit switches, L3LS probably won't cost more, if at all.
- L3LS is a product: While some products like Big Switch, Cisco ACI, or Juniper's QFabric provide a pre-made, self-provisioning network solution that loosely conforms to these design principles, it's not particularly difficult to build your own if a canned solution meets your needs.
- L3LS is difficult: We'll cover that in later posts, but it's mildly difficult to design, but easy to maintain and grow.
- L3LS has to use . Pretty much anything goes.
With that out of the way, let's have a bit of fun on the next one - running L3LS with RIPv2/3 as the designated routing protocol. In all cases the goal will be to provide a dual-stack network - IPv6 went final over 7 years ago. I'll be using CSR1000v and virtual NX-OS images for these examples, but your routing platform flavor of choice will work just fine. My point is that you know your platform, and should be able to map it out. This isn't stack overflow :)

Top comments (0)