Datacenter Network Engineers have two problems.
CHANGE.
LOOPS. (let's cover this one later!)
Change is everywhere. Emerging trends such as DevOps and/or CI/CD have created the need for dynamic, ephemeral allocation of data center resources; not only in large-scale deployments, but medium-sized companies are starting down this direction as well.
...but we still have to schedule change windows to add/remove networks from our datacenters due to the risks involved with network changes.
Current State
Today, most datacenter network deployments consist of 2 or 3 layers, with a huge variety of opinions on the "core" or topside layer. I'll start from the bottom up, as this will generally cover the areas of primary focus first.
Please keep in mind that I'm not throwing shade on this type of design. It's *highly* reliable and is the backbone of many companies. If it's working well for you, you don't have to throw it away. In many cases, the possibilities I will discuss may not even feasible for you. Eventually, I'll have enough time to cover all the various aspects that result in successful data center networks - but for now, I am going to cover a topic that tends to have a great deal of misinformation and markitechture that confuses many network engineers.
Core-Aggregation-Access Topologies
This reference design consists of three tiers, Core, Aggregation, and Access:
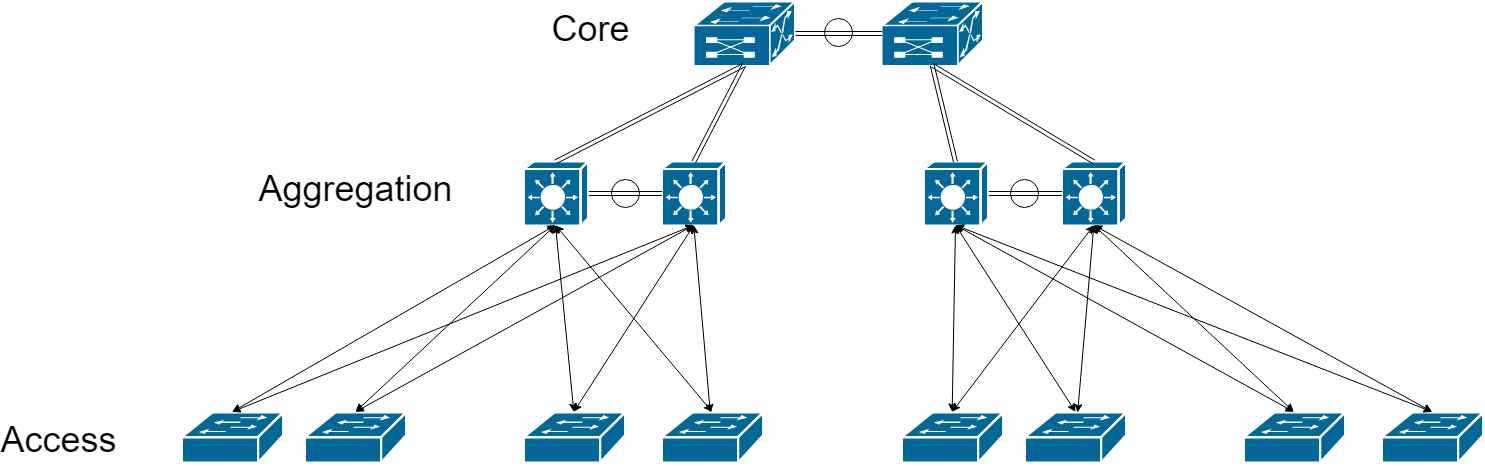
Datacenter Access
This particular layer is where the rubber hits the road. Servers directly connect to the Access layer, and the design of the service is geared primarily toward facilitating the needs of the subtending servers. All kinds of atypical services are typically deployed at this point, such as MC-LAG (vPC, MEC, etc). Generally speaking, this should be where the most change frequency will occur, as it is the least.
Most deployments at this point are Layer 2, trunking server/workload VLANs so that workloads do not have to change addressing as they traverse different switches. This is a workload problem that for the majority of deployments have not been solved - and must be mitigated by this design.
There are a few downsides, however:
- New network turn-ups involve all access-tier switches, and at a minimum, the aggregation layer. You're not mitigating risk with change if you have to modify pretty much every single device in your network!
- Loop prevention methods must all be Layer 2, e.g. spanning tree, FabricPath, TRILL, MC-LAG. These loop prevention methods are not very resilient, and any failures will cascade through the entire data center in most cases.
I do have some recommendations when facing this problem:
- When creating new networks, always explore the possibility of routed access. Adding SVIs to your access layer mitigates a great deal of this, but you lose workload portability. Perhaps not all workloads need portability, ex. storage over IP, host management.
- Preconfigure all ports with a default configuration that will support new server turn-ups. Server administrators love being able to just plug their equipment in and have it work. Spend a lot of time planning this default port configuration with your systems team - it'll pay off.
Datacenter Aggregation
This is where most of the meat and potatoes are as far as data center networking, and for most deployments, this is as far as most designs go. This section of a data center network will be running tons of services, into one place they can be aggregated (thus the name). You'll typically see the following connected to / running on the access layer:
- Firewalls
- Load Balancers
- Datacenter Interconnects, if there's no Core
- Loop prevention methods such as MC-LAG
- Layer 3 gateways for the majority of VLANs
- All your VLANs are belong to the aggregation layer
The Aggregation Layer is probably the riskiest device in a data center network to modify. I recommend doing a few things to mitigate these risks:
- Waste TONS of address space. Create lots of new networks, and keep them relatively small if you can (sub-/24). Deliver them to all of the access layers in a scalable manner, and preconfigure it all at the outset. Remember, no matter what capacity you allocate to, customers will overrun it.
- Don't pile too much on the aggregation devices. You can connect a separate firewall, LB, etc to the aggregation layer, keeping these devices as simple as possible will ensure that administration work is as simple as possible.
- Ensure you have an adequate port count. The move to adopting a data center core is an expensive one and is necessitated by the 3rd set of aggregation layer devices, typically.
Datacenter Core
This is the one where your VAR starts seeing dollar signs. Most deployments will not need this layer, even up when thousands of workloads (VMs, containers, I don't discriminate), as your port-count with an average Aggregation-Access network (we'll call them pods from now on) will be:
- 32-48 Aggregation ports
- 32-48 Access ports
You can dual-home 1,024-2,304 servers, or quad-home 512-1,152 servers on paper with one pod. Of course, most of these ports are wasted because you can't always fit 24-48 servers into a cabinet. Real-world maximum server count per pod would be in the hundreds.
The primary point where a data center network would expand to a network core would be when interconnecting 3 or more pods or physical locations. I do have recommendations on design here as well:
- Don't budge on IP portability here. Keep it Layer 3
- When I say Layer 3, I mean it. No VLANs at all - use stuff like
no switchportand .1q tags if necessary. Eliminate spanning-tree completely - Carefully choose your routing protocols here. BGP is fault-tolerant and complex, OSPF rapidly recovers from failure due to link state and often overreacts to changes. I won't talk about EIGRP because I don't like proprietary routing protocols. Deal with it.
So this is where most people are at with their data centers - and when properly designed, the biggest danger to reliability is the network engineer. Once you finish building this design, network additions, configuration changes, software upgrades will be the leading cause of network outages. Most network gear available for purchase today is highly reliable, and since everything is Layer 2, this network design will not fail unless an anomaly is introduced or a change is made.
The next section will be for those of us that suffer undue stress and pressure due to a high frequency of change - it's possible to have the level of comfort that most systems engineers have when performing their work.

Top comments (0)