
O DynamoDB da Amazon foi lançado em 2012 e vem adicionando uma série de novos recursos desde então. É difícil de acreditar agora, mas a versão original do DynamoDB não tinha streams, scan paralelos ou índices secundários.
Um dos lançamentos de recursos mais interessantes do DynamoDB nos últimos anos foi a adição de Transações do DynamoDB no re:Invent 2018. Com as Transações do DynamoDB, você pode escrever ou ler um lote de itens do DynamoDB e toda a solicitação será bem-sucedida ou falhará em conjunto.
Esta versão do recurso simplificou muitos fluxos de trabalho que envolviam versionamento complexos e várias solicitações para se trabalhar com precisão em vários itens. Nesta postagem, analisaremos como e por que usar as transações do DynamoDB.
Nós cobriremos:
- Informações básicas sobre transações do DynamoDB, incluindo diferenças com operações em lote (batch) e idempotência nas transações
- Três casos de uso comuns para transações do DynamoDB
Em um próximo artigo, veremos algumas análises de desempenho para ver quanto tempo as solicitações de transação do DynamoDB levam em comparação com as ações padrão de item único e até mesmo com ações em lote.
Vamos começar!
Informações básicas sobre transações do DynamoDB
Para começar, alguns detalhes sobre as transações do DynamoDB. Abordaremos duas áreas:
- Quais são as APIs transacionais e como elas diferem das APIs em lote?
- Manipulando idempotência com solicitações transacionais.
Quais são as APIs transacionais?
Existem duas chamadas de API que lidam com transações - TransactWriteItems e TransactGetItems. Como você pode adivinhar pelo nome, o primeiro é usado para escrever vários itens em uma única transação. O segundo é usado para ler vários itens em uma única transação. Ambas as APIs transacionais permitem operar em até 25 itens em uma única solicitação.
O DynamoDB há muito tempo tem APIs baseadas em lote que operam em vários itens ao mesmo tempo. Você pode BatchGetItem para ler até 100 itens de uma só vez ou BatchWriteItem para escrever até 25 itens de uma só vez.
Existem duas diferenças principais entre as APIs Batch* e as APIs Transact*. O primeiro é sobre o consumo de capacidade. Ao usar as APIs Transact*, você será cobrado duas vezes a capacidade que seria consumida se executasse as operações sem uma transação. Portanto, se você tiver uma solicitação TransactWriteItem` que insira dois itens com menos de 1KB, você será cobrado por 4 unidades de capacidade de gravação - 2 itens de 1KB X 2 para transações.
A segunda diferença entre as APIs Transact* e as APIs Batch* está relacionada aos modos de falha. Com as APIs Transact*, todas as leituras ou gravações terão êxito ou falharão juntas . Nas APIs Batch*, algumas solicitações podem ser bem-sucedidas e outras podem falhar, e você decide os erros.
Uma solicitação transacional pode falhar por vários motivos. Primeiro, um dos elementos em uma solicitação pode falhar devido às condições na solicitação. Para qualquer uma das solicitações baseadas em gravação, você pode incluir uma expressão de condição na solicitação. Se essas condições não forem atendidas, a gravação falhará e todo o lote falhará.
Segundo, uma transação pode falhar se um dos itens estiver sendo alterado em uma transação ou solicitação separada. Por exemplo, se você fizer uma solicitação TransactGetItems em um item ao mesmo tempo em que houver uma solicitação TransactWriteItems em aberto sendo processada no item, a solicitação TransactGetItems falhará. Esse tipo de falha é conhecido como conflito de transação e é possível visualizar no CloudWatch Metrics o número de conflitos de transação em suas tabelas.
Por fim, uma transação pode falhar por outros motivos, como sua tabela não ter capacidade suficiente ou o serviço DynamoDB sendo desativado em geral.
Idempotência com solicitações transacionais
Para a API TransactWriteItem, o DynamoDB permite que você transmita um parâmetro ClientRequestToken com sua solicitação. A inclusão desse parâmetro permitirá garantir que sua solicitação seja idempotente, mesmo que enviada várias vezes.
Para ver como isso é útil, imagine que você esteja fazendo uma solicitação TransactWriteItem que inclui algumas solicitações de gravação para incrementar um atributo em um item. Se você teve um problema de rede em que não sabia se essa operação teve êxito ou falhou, você pode estar em um estado ruim. Se você assumir que a operação foi bem-sucedida, mas não obteve, o valor do seu atributo será menor do que deveria. Se você presumir que a operação falhou quando não ocorreu, poderá enviar a solicitação novamente, mas o valor do atributo será maior do que deveria.
O ClientRequestToken lida com isso. Se você enviar uma solicitação com o mesmo token e os mesmos parâmetros em um período de 10 minutos, o DynamoDB garantirá que a solicitação seja idempotente. Se a solicitação for bem-sucedida quando enviada inicialmente, o DynamoDB não a executará novamente. Se falhou na primeira vez, o DynamoDB aplicará as gravações na solicitação.
A API TransactWriteItems é a única API do DynamoDB que permite a idempotência; portanto, você pode usar TransactWriteItems mesmo com um único item se tiver uma forte necessidade de idempotência.
Casos de uso comuns para transações do DynamoDB
Agora que conhecemos os conceitos básicos sobre transações do DynamoDB, vamos vê-los em ação. Lembre-se de que as Transações do DynamoDB custam o dobro de uma operação semelhante sem transação; portanto, devemos ser criteriosos e usar transações somente quando realmente precisamos delas.
Quando são bons momentos para usar transações? Eu tenho três exemplos favoritos que abordaremos abaixo:
- Mantendo a exclusividade em vários atributos
- Manipulação de contagens e prevenção de duplicatas
- Autorizando um usuário a executar uma determinada ação
Não incluí um exemplo em que eu precisaria de idempotência, conforme discutido na seção anterior, mas esse é outro exemplo de um bom caso de uso para as APIs transacionais.
Vamos revisar cada um dos exemplos por vez.
Mantendo a exclusividade em vários atributos
No DynamoDB, se você quiser garantir que um atributo específico seja exclusivo, precisará criar esse atributo diretamente na chave primária.
Um exemplo fácil aqui é um fluxo de inscrição do usuário para um aplicativo. Você deseja que o nome de usuário seja exclusivo em seu aplicativo, então você criar uma chave primária que inclua o nome de usuário.
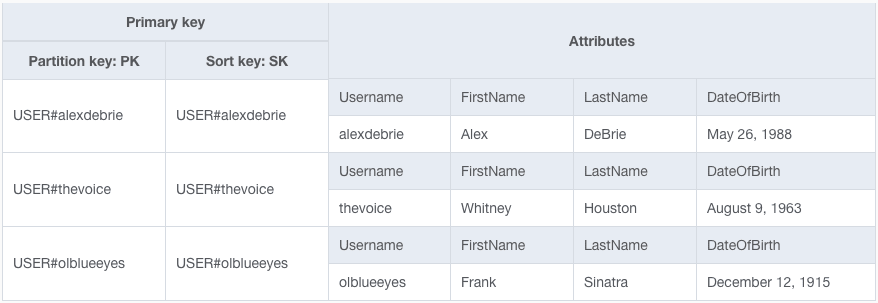
Na tabela acima, nossos valores de PK e SK incluem os valores username para que eles sejam únicos.
Mas e se você também quiser garantir que um determinado endereço de email seja exclusivo em todo o sistema, para que não haja pessoas que se inscrevam em várias contas no mesmo endereço de email?
Você também pode adicionar email à sua chave primária:
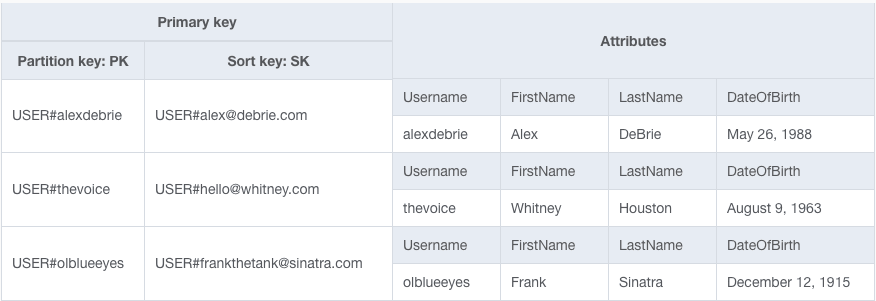
Agora, nossa tabela inclui o nome de usuário no PK e o email no SK.
No entanto, isso não vai funcionar. É a combinação de uma chave de partição e uma chave de classificação que torna um item exclusivo dentro da tabela. Usando essa estrutura de chaves, você confirma que um endereço de email será usado apenas uma vez para esse nome de usuário. Agora você perdeu as propriedades originais de exclusividade no nome de usuário, pois outra pessoa pode se inscrever com o mesmo nome de usuário e um endereço de email diferente!
Se você deseja garantir que um nome de usuário e um endereço de email sejam exclusivos em sua tabela, é necessário criar um item para cada um e adicionar esses itens a uma transação.
O código para escrever essa transação seria o seguinte:
python
response = client.transact_write_items(
TransactItems=[
{
'Put': {
'TableName': 'UsersTable',
'Item': {
'PK': { 'S': 'USER#alexdebrie' },
'SK': { 'S': 'USER#alexdebrie' },
'Username': { 'S': 'alexdebrie' },
'FirstName': { 'S': 'Alex' },
...
},
'ConditionExpression': 'attribute_not_exists(PK)'
}
},
{
'Put': {
'TableName': 'UsersTable',
'Item': {
'PK': { 'S': 'USEREMAIL#alex@debrie.com' },
'SK': { 'S': 'USEREMAIL#alex@debrie.com' },
},
'ConditionExpression': 'attribute_not_exists(PK)'
}
}
]
)
E agora sua tabela teria a seguinte aparência:

Observe que o item que armazena um usuário por endereço de email não possui nenhuma propriedade do usuário. Você pode fazer isso se planeja dar acesso por um nome de usuário e nunca por um endereço de email. O item do endereço de email é criado apenas como um marcador que rastreia se o email foi usado.
Se você vai acessar um usuário pelo endereço de e-mail, então você precisa duplicar todas as informações em ambos os itens. Em seguida, sua tabela pode ter a seguinte aparência:

Eu evitaria isso, se possível. Agora, toda atualização no item do usuário precisa ser uma transação para atualizar os dois itens. Isso aumentará o custo de suas gravações e a latência em suas solicitações.
Manipulando contagens e prevenção de duplicatas
Um segundo lugar em que as transações podem ser úteis é armazenar contagens para itens relacionados. Vamos ver como isso funciona.
Imagine que você tenha um aplicativo social com algum tipo de sistema para 'gostar' de itens. Pode ser o Twitter, como os usuários gostam de outros tweets. Pode ser o Reddit, onde os usuários podem curtir ou votar em postagens ou comentários específicos. Ou pode ser o GitHub, onde um usuário pode adicionar uma reação a um problema.
Em todas essas situações, convém armazenar um registro do usuário que está votando positivamente em um item específico para garantir que o usuário não vote várias vezes.
Além disso, ao exibir o item que pode ser votado, você deseja exibir o número total de votos. É mais eficiente desnormalizar isso armazenando uma propriedade de contador no próprio item, em vez de fazer uma operação de Consulta toda vez para buscar todos os itens que indicam que o item foi votado.
Sua tabela pode ter a seguinte aparência:

Esta tabela é uma versão simplificada do Reddit. Os usuários podem criar Postagens, e outros usuários podem gostar das Postagens. Nesta tabela, temos 5 itens. Dois deles são itens de postagem (usando o POST<PostId> padrão para PK e SK), enquanto três deles são itens semelhantes a usuários (usando o mesmo POST#<PostId> padrão para PK e um USER#<Username> padrão para SK). Observe como cada item de postagem possui um atributo UpvotesCount que armazena o número total de upvotes recebidos.
Quando um usuário faz uma votação de um item, primeiro você deseja garantir que o usuário não tenha votado anteriormente no item e depois incrementa o atributo UpvotesCount no item. Em um mundo sem transações, esse seria um processo de duas etapas.
Com transações, você pode fazer isso em uma única etapa. O código para executar esta transação seria o seguinte:
python
response = client.transact_write_items(
TransactItems=[
{
'Put': {
'TableName': 'RedditTable',
'Item': {
'PK': { 'S': 'POST#1caa5be06389' },
'SK': { 'S': 'USER#alexdebrie' },
'Username': { 'S': 'alexdebrie' },
},
'ConditionExpression': 'attribute_not_exists(PK)'
}
},
{
'Update': {
'TableName': 'UsersTable',
'Key': {
'PK': { 'S': 'POST#1caa5be06389' },
'SK': { 'S': 'POST#1caa5be06389' }
},
'UpdateExpression': 'SET UpvotesCount = UpvotesCount + :incr',
'ExpressionAttributeValues': {
':incr': { 'N': '1' }
}
}
}
]
)
Nossa transação inclui duas solicitações de gravação. O primeiro insere um novo item que indica que o usuário alexdebrie votou positivamente na publicação do Reddit. Essa solicitação de gravação inclui uma expressão de condição que afirma que um item com a mesma chave ainda não existe, o que indicaria que alexdebrie já fez um voto positivo nesse item.
A segunda solicitação de gravação é uma expressão de atualização para incrementar a postagem UpvotesCount votada.
Se a primeira solicitação de gravação falhar porque alexdebrie já fez o voto positivo para esse item, a atualização UpvotesCount não será atualizada, pois toda a transação falhará.
Nota: você pode manipular esse padrão de uma maneira diferente, sem transações. Você pode fazer uma solicitação PutItem simples para adicionar um item, indicando que um usuário votou positivamente em um item específico, com a mesma expressão de condição usada acima. Em seguida, usando o DynamoDB Streams, você pode agregar todas essas novas inserções de itens e incrementar os itens-pai UpvotesCount em lote.
Essas abordagens são bastante semelhantes, então você pode ir de qualquer maneira. Eu recomendaria apenas a abordagem baseada em streams, se uma das seguintes circunstâncias for verdadeira:
- Você deseja que o voto positivo seja o mais rápido possível, então você usa a solicitação
PutItemque é mais rápida do que a solicitação mais lentaTransactWriteItems. - Você tem um pequeno número de itens que serão votados de modo que seja provável que você possa agregar vários upvotes individuais ao incrementar o
UpvotesCount.
Vamos pensar um pouco no segundo caso, usando dois exemplos diferentes - um aplicativo de votação nacional e um site de mídia social como o Twitter. No aplicativo de votação, existem apenas algumas opções para os usuários selecionarem. Você pode economizar na capacidade de gravação em sua tabela usando o método baseado em streams para agregar vários votos e incrementar o UpvotesCount em lotes.
Por outro lado, um site de mídia social como o Twitter tem uma enorme cardinalidade de itens que podem ser votados. Mesmo com um tamanho de lote de 1000 registros do seu DynamoDB stream, é improvável que você obtenha vários registros que tocam no mesmo item pai. Nesse caso, o uso da capacidade de gravação será o mesmo, pois você precisará incrementar cada item pai individualmente.
Controle de acesso
Um terceiro caso de uso para transações está em uma configuração de autorização ou controle de acesso.
Imagine que você forneça um aplicativo SaaS para grandes organizações. Com a instalação de seu aplicativo por uma organização, existem dois níveis de usuários: Administradores e Membros. Os administradores têm permissão para adicionar novos membros à instalação, mas os membros regulares não.
Sem transações, você precisaria executar um processo de várias etapas para ler e gravar no DynamoDB para adicionar um novo membro. Com as transações do DynamoDB, você pode fazer isso em uma única etapa.
Imagine que você tem a seguinte tabela:

Esta tabela inclui organizações e usuários. Uma organização tem um padrão de chave primária usado ORG#<OrgName> para PK e SK, enquanto um usuário tem um padrão de chave primária usado ORG#<OrgName> para PK e USER#<Username> SK.
Observe que os itens da organização incluem um atributo Admins do tipo array de strings. Este atributo armazena quais usuários são administradores e, portanto, pode criar novos usuários.
Quando alguém tenta criar um novo usuário em uma organização, você pode usar uma transação para afirmar com segurança que o membro solicitante é um administrador.
A solicitação TransactWriteItems teria a seguinte aparência:
python
response = client.transact_write_items(
TransactItems=[
{
'ConditionCheck': {
'TableName': 'AccessControl',
'Key': {
'PK': { 'S': 'ORG#amazon' },
'SK': { 'S': 'ORG#amazon' },
},
'ConditionExpression': 'contains(Admins, :user)',
'ExpressionAttributeValues': {
':user': { 'S': 'Charlie Bell' }
}
}
},
{
'PutItem': {
'TableName': 'AccessControl',
'Item': {
'PK': { 'S': 'ORG#amazon' },
'SK': { 'S': 'USER#jeffbarr' },
'Username': { 'S': 'jeffbarr' }
}
}
}
]
)
Este exemplo é um pouco diferente do anterior. Observe que estamos usando uma operação ConditionCheck. Na verdade, não queremos modificar o item da organização existente. Nós apenas queremos afirmar uma condição específica: o Charlie Bell é um administrador. Se isso não estiver correto, queremos falhar em toda a transação.
Existem várias maneiras de lidar com a autorização no seu aplicativo, e essa é uma opção. O bom disso é que é flexível - você pode implementar a autorização em todo o aplicativo usando um item singleton em sua tabela ou pode implementar uma autorização refinada e baseada em recursos, adicionando informações de autorização em um grande número de recursos em sua tabela.
Conclusão
Nesta postagem, aprendemos sobre as transações do DynamoDB. Primeiro, abordamos o básico das transações do DynamoDB - como elas funcionam? Que garantias elas fornecem? Quanto elas custam?
Segundo, vimos alguns exemplos de transações do DynamoDB em ação. Passamos por três exemplos: mantendo a exclusividade em vários atributos; manipulação de contagens e prevenção de duplicatas; e gerenciamento de controle de acesso.
As transações do DynamoDB são uma ótima ferramenta para adicionar ao seu cinto de ferramentas. Mas você também precisa estar ciente do impacto no desempenho. Em um próximo artigo, testaremos o impacto no desempenho das transações em comparação com outras alternativas.
Deseja mais conteúdo nas transações do DynamoDB? Confira o seguinte:
- Edin Zulich fez uma ótima apresentação sobre DynamoDB Transactions.
- Depois que o DynamoDB Transactions foi anunciado no re:Invent 2018, Yossi Levanoni deu essa palestra no DynamoDB Transactions.
Se você tiver perguntas ou comentários sobre este artigo, sinta-se à vontade para deixar um comentário abaixo ou me envie um email diretamente.
Créditos
- DynamoDB Transactions: Use Cases and Examples, escrito originalmente por Alex DeBrie.

Top comments (0)