
Às vezes, o DynamoDB é considerado apenas para um armazenamento de chaves-valores simples, mas nada poderia estar mais longe da verdade. O DynamoDB pode lidar com padrões de acesso complexos, desde modelos de dados altamente relacionais a dados de séries temporais ou até dados geoespaciais.
Neste artigo, veremos como modelar relacionamentos um-para-muitos, one-to-many, no DynamoDB. Os relacionamentos um para muitos estão no centro de quase todos os aplicativos. No DynamoDB, você tem algumas opções diferentes para representar relacionamentos um para muitos.
Abordaremos o básico dos relacionamentos um para muitos e, em seguida, revisaremos cinco estratégias diferentes para modelar relacionamentos um para muitos no DynamoDB:
- Desnormalização usando um atributo complexo
- Desnormalização duplicando dados
- Chave primária composta + ação da Query API
- Índice secundário + ação da Query API
- Chaves de classificação compostas com dados hierárquicos
Vamos começar!
Noções básicas de relacionamentos um para muitos
Um relacionamento de um para muitos ocorre quando um objeto específico é o proprietário ou a origem de vários sub-objetos. Alguns exemplos incluem:
- Local de trabalho: Um único escritório terá muitos funcionários trabalhando lá; um único gerente pode ter muitos subordinados diretos.
- Comércio eletrônico: um único cliente pode fazer vários pedidos ao longo do tempo; um único pedido pode ser composto de vários itens.
- Contas de software como serviço (SaaS): uma organização comprará uma assinatura SaaS; vários usuários pertencerão a uma organização.
Nos relacionamentos um para muitos, há um problema principal: como obtenho informações sobre a entidade pai ao recuperar uma ou mais das entidades relacionadas?
Em um banco de dados relacional, existe basicamente uma maneira de fazer isso - usar uma chave estrangeira em uma tabela para se referir a um registro em outra tabela e usar uma SQL JOIN no momento da consulta para combinar as duas tabelas.
Não há associações no DynamoDB. Ao invés disso, existem várias estratégias para relacionamentos um-para-muitos, e a abordagem adotada dependerá de suas necessidades.
Nesta postagem, abordaremos cinco estratégias para modelar relacionamentos um-para-muitos com o DynamoDB:
- Desnormalização usando um atributo complexo
- Desnormalização duplicando dados
- Chave primária composta + ação da Query API
- Índice secundário + ação da Query API
- Chaves de classificação compostas com dados hierárquicos
Abordaremos cada estratégia detalhadamente abaixo - quando você a usaria, quando não usaria e um exemplo. No final do artigo, teremos um resumo das cinco estratégias e quando escolher cada uma.
Desnormalização usando um atributo complexo
A normalização de banco de dados é um componente essencial da modelagem de banco de dados relacional e um dos hábitos mais difíceis de quebrar ao migrar para o DynamoDB.
Você pode ler os conceitos básicos da normalização em outro lugar, mas há várias áreas em que a desnormalização é útil com o DynamoDB.
A primeira maneira de usar a desnormalização com o DynamoDB é ter um atributo que use um tipo de dados complexo, como uma lista ou um mapa. Isso viola o primeiro princípio da normalização do banco de dados: para entrar na primeira forma normal, cada valor de atributo deve ser atômico. Não pode mais ser decomposto.
Vamos ver isso como um exemplo. Imagine que temos um site de comércio eletrônico em que existem entidades do Cliente que representam pessoas que criaram uma conta em nosso site. Um único Cliente pode ter vários endereços para os quais eles podem enviar itens. Talvez eu tenha um endereço para minha casa, outro para meu local de trabalho e um terceiro para meus pais (uma relíquia do momento em que enviei um presente de aniversário atrasado).
Em um banco de dados relacional, você modelaria isso com duas tabelas usando uma chave estrangeira para vincular as tabelas, da seguinte maneira:
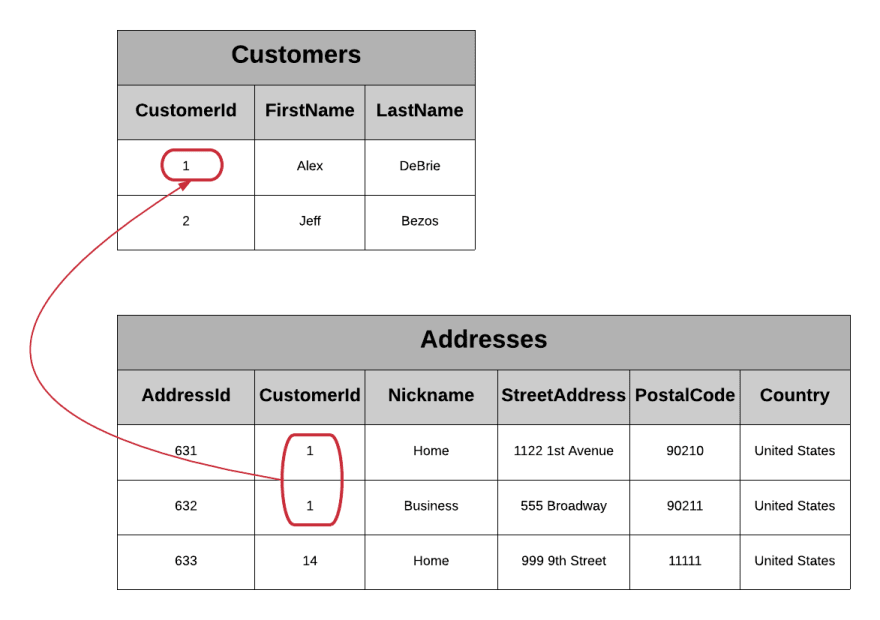
Observe que cada registro na tabela Addresses inclui a CustomerId, que identifica o cliente ao qual esse endereço pertence. Você pode usar a operação JOIN para seguir o ponteiro para o registro e encontrar informações sobre o Cliente.
O DynamoDB funciona de maneira diferente. Como não há junções, precisamos encontrar uma maneira diferente de reunir dados de dois tipos diferentes de entidades. Neste exemplo, podemos adicionar um atributo MailingAddresses ao nosso item Customer. Este atributo é um mapa e contém todos os endereços para o cliente especificado:

Como MailingAddresses contém vários valores, ele não é mais atômico e, portanto, viola os princípios da primeira forma normal.
Há dois fatores a serem considerados ao decidir se devemos lidar com um relacionamento um-para-muitos, desnormalizando com um atributo complexo:
- Você tem algum padrão de acesso com base nos valores do atributo complexo?
Todo o acesso a dados no DynamoDB é feito por chaves primárias e índices secundários. Você não pode usar um atributo complexo como uma lista ou um mapa em uma chave primária. Portanto, você não poderá fazer consultas com base nos valores de um atributo complexo.
No nosso exemplo, não temos padrões de acesso como "Buscar um cliente pelo endereço de correspondência". Todo o uso do atributo MailingAddress será no contexto de um Cliente, como a exibição dos endereços salvos na página de pagamento do pedido. Dadas essas necessidades, é bom salvá-las em um atributo complexo.
- A quantidade de dados no atributo complexo é ilimitada?
Um único item do DynamoDB não pode exceder 400 KB de dados. Se a quantidade de dados contida no seu atributo complexo for potencialmente ilimitada, não será uma boa opção para desnormalizar e manter juntos um único item.
Neste exemplo, é razoável que nosso aplicativo coloque limites no número de endereços para correspondência que um cliente pode armazenar. No máximo 20 endereços devem atender a quase todos os casos de uso e evitar problemas com o limite de 400 KB.
Mas você pode imaginar outros lugares onde o relacionamento um para muitos pode ser ilimitado. Por exemplo, nosso aplicativo de comércio eletrônico tem um conceito de pedidos e itens de pedidos. Como um pedido pode ter um número ilimitado de itens do pedido (você não deseja informar a seus clientes que há um número máximo de itens que eles podem pedir!), Faz sentido dividir os itens do pedido separadamente dos pedidos.
Se a resposta para qualquer uma das perguntas acima for "Sim", a desnormalização com um atributo complexo não será adequada para modelar esse relacionamento um para muitos.
Desnormalização duplicando dados
Na estratégia acima, desnormalizamos nossos dados usando um atributo complexo. Isso violou os princípios da primeira forma normal para modelagem relacional. Nesta estratégia, continuaremos nossa cruzada contra a normalização.
Aqui, violaremos os princípios da segunda forma normal duplicando dados em vários itens.
Em todos os bancos de dados, cada registro é identificado exclusivamente por algum tipo de chave. Em um banco de dados relacional, isso pode ser uma chave primária de incremento automático. No DynamoDB, essa é a chave primária.
Para chegar à segunda forma normal, cada atributo que não é da chave deve depender da chave inteira. Essa é uma maneira confusa de dizer que os dados não devem ser duplicados em vários registros. Se os dados forem duplicados, eles deverão ser puxados para uma tabela separada. Cada registro que usa esses dados deve fazer referência a eles por meio de uma referência de chave estrangeira.
Imagine que temos um aplicativo que contém livros e autores. Cada livro tem um autor e cada autor possui algumas informações biográficas, como nome e ano de nascimento. Em um banco de dados relacional, modelaríamos os dados da seguinte maneira:

Nota: Na realidade, um livro pode ter vários autores. Para simplificação deste exemplo, supomos que cada livro tenha exatamente um autor.
Isso funciona em um banco de dados relacional, pois você pode juntar essas duas tabelas no momento da consulta para incluir as informações do autor ao recuperar detalhes sobre o livro.
Mas não temos associações no DynamoDB. Então, como podemos resolver isso? Podemos ignorar as regras da segunda forma normal e incluir as informações do autor em cada item do livro, como mostrado abaixo.

Observe que existem vários livros que contêm as informações do autor Stephen King. Como essas informações não mudam, podemos armazená-las diretamente no item do livro. Sempre que recuperarmos o livro, também obteremos informações sobre o item do autor principal.
Há duas perguntas principais que você deve fazer ao considerar esta estratégia:
- A informação duplicada é imutável?
- Se os dados mudarem, com que frequência eles mudam e quantos itens incluem as informações duplicadas?
No exemplo acima, duplicamos as informações que provavelmente não serão alteradas. Por ser essencialmente imutável, não há problema em duplicá-lo sem se preocupar com problemas de consistência quando esses dados são alterados.
Mesmo que os dados que você está duplicando sejam alterados, você ainda pode decidir duplicá-los. Os grandes fatores a serem considerados são a frequência com que os dados são alterados e quantos itens incluem as informações duplicadas.
Se os dados forem alterados com pouca frequência e os itens desnormalizados forem lidos com muita frequência, podemos duplicar para economizar dinheiro em todas as leituras subsequentes. Quando os dados duplicados são alterados, você precisa trabalhar para garantir que sejam alterados em todos esses itens.
O que nos leva ao segundo fator - quantos itens contêm os dados duplicados. Se você duplicou os dados apenas em três itens, pode ser fácil encontrar e atualizar esses itens quando os dados forem alterados. Se esses dados são copiados em milhares de itens, pode ser uma tarefa difícil descobrir e atualizar cada um desses itens, e você corre um risco maior de inconsistência dos dados.
Basicamente, você está equilibrando o benefício da duplicação (na forma de leituras mais rápidas) com os custos da atualização dos dados. Os custos da atualização dos dados incluem os dois fatores acima. Se os custos de qualquer um dos fatores acima forem baixos, quase todo benefício valerá a pena. Se os custos são altos, o oposto é verdadeiro.
Chave primária composta + ação da Query API
A próxima estratégia para modelar relacionamentos um para muitos - e provavelmente a maneira mais comum - é usar uma chave primária composta mais a Query API para buscar um objeto e seus subobjetos relacionados.
Um conceito-chave no DynamoDB é a noção de coleções de itens. Coleções de itens são todos os itens em uma tabela ou índice secundário que compartilham a mesma chave de partição. Ao usar a Query API, você pode buscar vários itens em uma única coleção de itens. Isso pode incluir itens de tipos diferentes, o que fornece um comportamento semelhante a junção com desempenho muito melhor.
Vamos usar um dos exemplos acima. Em um aplicativo SaaS, as organizações irão se inscrever em contas. Em seguida, vários usuários pertencerão a uma organização e aproveitarão a assinatura.
Como incluiremos diferentes tipos de itens na mesma tabela, não teremos nomes de atributos significativos para os atributos em nossa chave primária. Ao invés disso, usaremos nomes genéricos de atributo, como PK e SK, para nossa chave primária.
Temos dois tipos de itens em nossa tabela - Organizações e Usuários. Os padrões para os valores PK e SK são os seguintes:
Entidade: Organizações:
- PK: ORG#
- SK: METADATA#
Entidade: Comercial:
- PK: ORG#
- SK: User#
A tabela abaixo mostra alguns itens de exemplo:

Nesta tabela, adicionamos cinco itens - dois itens da organização para Microsoft e Amazon e três itens de usuário para Bill Gates, Satya Nadella e Jeff Bezos.
Destacada em vermelho é a coleção de itens com a chave de partição de ORG#MICROSOFT. Observe como existem dois tipos diferentes de itens nessa coleção. Em verde é o tipo de item da organização nessa coleção de itens e em azul é o tipo de item de usuário nessa coleção de itens.
Esse design de chave primária facilita a solução de quatro padrões de acesso:
-
Recupere uma organização: Use a GetItem API e o nome da organização para fazer uma solicitação para o item com um PK de
ORG#<OrgName>e um SK deMETADATA#<OrgName>. -
Recupere uma organização e todos os usuários dentro da organização: Use a Query API com uma expressão de condição chave de
PK = ORG#<OrgName>. Isso recuperaria a organização e todos os usuários nela, pois todos têm a mesma chave de partição. -
Recupere apenas os usuários dentro de uma organização: Use Query API com uma expressão de condição de chave de
PK = ORG#<OrgName> AND starts_with(SK, "USER#"). O uso da funçãostarts_with()nos permite recuperar apenas os usuários sem buscar também o objeto Organization. -
Recupere um usuário específico: Se você souber o nome da organização e o nome de usuário do usuário, poderá usar a GetItem API com um
PKdeORG#<OrgName>e umSKdeUSER#<Username>para buscar o item de usuário.
Embora todos esses quatro padrões de acesso possam ser úteis, o segundo padrão de acesso - Recuperar uma organização e todos os usuários da organização - é mais interessante para essa discussão sobre relacionamentos um para muitos. Observe como estamos emulando uma operação de junção no SQL, localizando o objeto pai (a Organização) na mesma coleção de itens que os objetos relacionados (os Usuários). Estamos pré-juntando nossos dados, organizando-os juntos no momento da gravação.
Essa é uma maneira bastante comum de modelar relacionamentos um-para-muitos e funcionará para várias situações.
Índice secundário + ação da Query API
Um padrão semelhante para relacionamentos um-para-muitos é usar um índice secundário global e a Query API para buscar muitos itens. Esse padrão é quase o mesmo que o padrão anterior, mas usa um índice secundário em vez das chaves primárias na tabela principal.
Pode ser necessário usar esse padrão em vez do padrão anterior, porque as chaves primárias em sua tabela estão reservadas para outro propósito. Pode ser uma finalidade específica de gravação, como garantir exclusividade em uma propriedade específica, ou pode ser porque você possui dados hierárquicos com vários níveis.
Para a última situação, vamos voltar ao nosso exemplo mais recente. Imagine que no seu aplicativo SaaS, cada usuário possa criar e salvar vários objetos. Se fosse o Google Drive, poderia ser um documento. Se esse fosse o Zendesk, pode ser um ticket. Se fosse Typeform, pode ser um formulário.
Vamos usar o exemplo do Zendesk e seguir com um ticket. Para nossos casos, digamos que cada ticket seja identificado por um ID que seja uma combinação de uma data/hora mais um sufixo de hash aleatório. Além disso, cada ticket pertence a um usuário específico em uma organização.
Se quisermos encontrar todos os tickets que pertencem a um usuário específico, poderíamos tentar intercalá-los com o formato de tabela existente da estratégia anterior, da seguinte maneira:
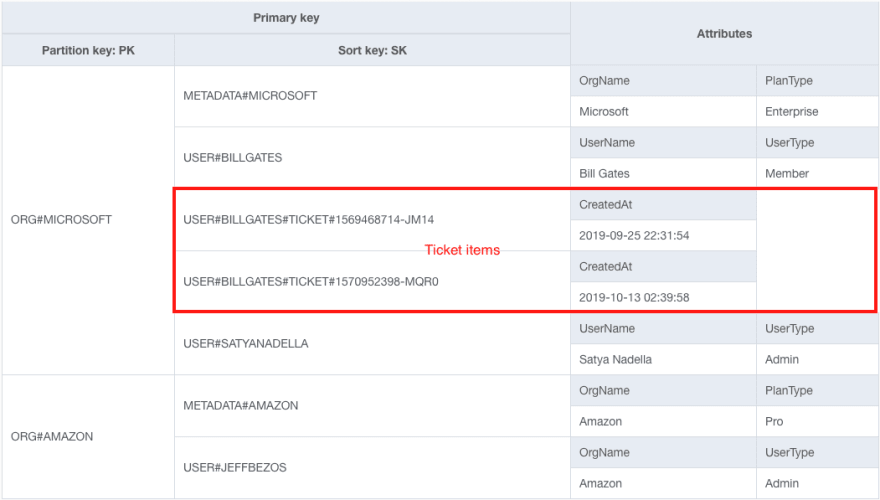
Observe os dois novos itens do ticket destacados em vermelho.
O problema disso é que ele realmente congestiona meus casos de uso anteriores. Se eu quiser recuperar uma organização e todos os seus usuários, também estou recuperando vários tickets. E como é provável que os tickets excedam amplamente o número de usuários, buscarei muitos dados inúteis e farei várias solicitações de paginação para lidar com nosso caso de uso original.
Ao invés disso, vamos tentar algo diferente. Faremos três coisas:
- Modelaremos nossos itens de Ticket para que estejam em uma coleção de itens separados na tabela principal. Os valores
PKeSKnão importam muito aqui, desde que não criemos hot keys ou dois itens com a mesma chave primária. - Crie um índice secundário global chamado
GSI1cujas chaves sãoGSI1PKeGSI1SK. - Para os itens de ticket e usuário, adicione valores para
GSI1PKeGSI1SK. Para ambos os itens, o valor do atributoGSI1PKseráORG#<OrgName>#USER#<UserName>.
Para o item Usuário, o valor GSI1SK será USER#<UserName>.
Para o item Ticket, o valor GSI1SK será TICKET#<TicketId>.
Agora, nossa tabela base é a seguinte:
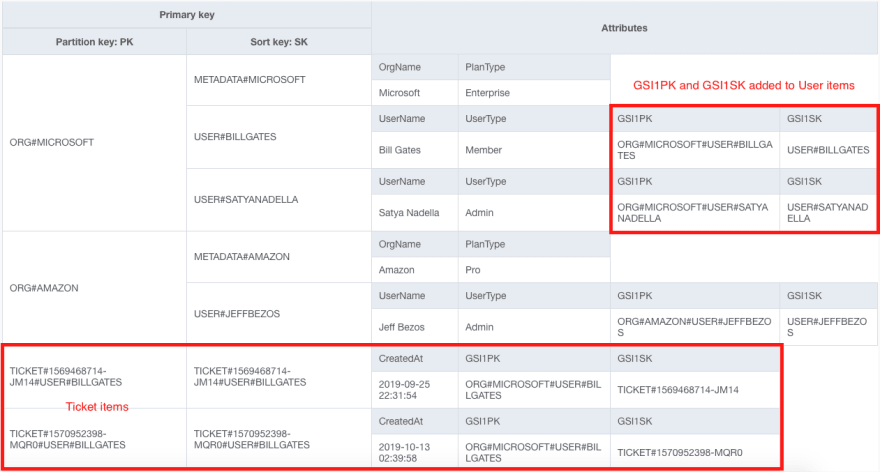
Observe que nossos itens de ticket não são mais intercalados com seus usuários na tabela base. Além disso, os itens Usuário agora têm atributos GSI1PK e GSI1SK adicionais que serão usados para indexação.
Se olharmos para o nosso índice secundário GSI1, vemos o seguinte:

Esse índice secundário possui uma coleção de itens com o item Usuário e todos os itens de ticket do usuário. Isso permite os mesmos padrões de acesso que discutimos na seção anterior.
Uma última nota antes de prosseguir - observe que eu a estruturei para que o item Usuário seja o último item na partição. Isso ocorre porque os tickets são classificados por data e hora. É provável que eu queira buscar um usuário e os tickets mais recentes do usuário, ao invés dos tickets mais antigos. Como tal, eu o ordeno para que o Usuário esteja no final da coleção de itens e posso usar a propriedade ScanIndexForward=False para indicar que o DynamoDB deve começar no final da coleção e ler para trás.
Chaves de classificação compostas com dados hierárquicos
Nas duas últimas estratégias, vimos alguns dados com alguns níveis de hierarquia - uma organização tem usuários, que criam tickets. Mas e se você tiver mais de dois níveis de hierarquia? Você não deseja continuar adicionando índices secundários para permitir níveis arbitrários de busca em toda a sua hierarquia.
Um exemplo comum nesta área é sobre dados baseados em localização. Vamos continuar com o tema do local de trabalho e imaginar que você está acompanhando todos os locais da Starbucks em todo o mundo. Você deseja filtrar os locais da Starbucks em níveis geográficos arbitrários - por país, estado, cidade ou código postal.
Podemos resolver esse problema usando uma chave de classificação composta. Esse termo é um pouco confuso, porque estamos usando uma chave primária composta em nossa tabela. O termo chave de classificação composta significa que agruparemos várias propriedades em nossa chave de classificação para permitir granularidade de pesquisa diferente.
Vamos ver como isso fica em uma tabela. Abaixo estão alguns itens:

Em nossa tabela, a chave da partição é o país em que a Starbucks está localizada. Para a chave de classificação, incluímos Estado, Cidade e CEP, com cada nível separado por a #. Com esse padrão, podemos pesquisar em quatro níveis de granularidade usando apenas nossa chave primária!
Os padrões são:
-
Encontre todos os locais em um determinado país: Use uma Consulta com uma expressão de condição de chave de
PK = <Country>, onde País é o país que você deseja. -
Encontre todos os locais em um determinado país e estado: Use uma consulta com uma expressão de condição de
PK = <Country> AND starts_with(SK, '<State>#'. -
Encontre todos os locais em um determinado país, estado e cidade: Use uma consulta com uma expressão de condição de
PK = <Country> AND starts_with(SK, '<State>#<City>'. -
Encontre todos os locais em um determinado país, estado, cidade e CEP: Use uma consulta com uma expressão de condição de
PK = <Country> AND starts_with(SK, '<State>#<City>#<ZipCode>'.
Esse padrão de chave de classificação composta não funciona em todos os cenários, mas pode ser ótimo na situação certa. Funciona melhor quando:
- Você tem muitos níveis de hierarquia (> 2) e possui padrões de acesso para diferentes níveis dentro da hierarquia.
- Ao pesquisar em um nível específico na hierarquia, você deseja todos os subitens nesse nível, em vez de apenas os itens desse nível.
Por exemplo, lembre-se do exemplo de SaaS ao discutir as estratégias de chave primária e de índice secundário. Ao pesquisar em um nível da hierarquia - encontrar todos os usuários - não desejamos nos aprofundar na hierarquia para encontrar todos os tickets para cada usuário. Nesse caso, uma chave de classificação composta retornará muitos itens estranhos.
Se você quiser uma explicação detalhada deste exemplo, escrevi o exemplo completo da Starbucks no DynamoDBGuide.com.
Conclusão
Nesta postagem, discutimos cinco estratégias diferentes que você pode implementar ao modelar dados em um relacionamento um para muitos com o DynamoDB. As estratégias estão resumidas na tabela abaixo.
Estratégia: Desnormalizar + atributo complexo
- Notas: Bom quando objetos aninhados são limitados e não são acessados diretamente
- Exemplos Relevantes: Endereços de correspondência do usuário
Estratégia: Desnormalizar + duplicar
- Notas: Bom quando dados duplicados são imutáveis ou mudam com pouca frequência
- Exemplos Relevantes: Livros e Autores; Filmes e Funções
Estratégia: Chave primária + Query API
- Notas: Mais comum. Bom para vários padrões de acesso nos dois tipos de entidade
- Exemplos Relevantes: A maioria dos relacionamentos um para muitos
Estratégia: Índice secundário + Query API
- Notas: Semelhante à estratégia de chave primária. Bom quando a chave primária é necessária para outra coisa
- Exemplos Relevantes: A maioria dos relacionamentos um para muitos
Estratégia: Chave de classificação composta
- Notas: Bom para dados muito hierárquicos, nos quais você precisa pesquisar em vários níveis da hierarquia
- Exemplos Relevantes: Locais da Starbucks
Considere suas necessidades ao modelar relacionamentos um para muitos e determine qual estratégia funciona melhor para sua situação.
Se você tiver perguntas ou comentários sobre este tema, sinta-se à vontade para deixar um comentário abaixo ou envie um email diretamente.
Créditos
- How to model one-to-many relationships in DynamoDB, escrito originalmente por Alex DeBrie.

Top comments (0)