In our previous post on Using Conductor to Parse Data, we discussed a Netflix Conductor workflow that extracts data from GitHub, transforms it, and then uploads the results to Orbit. This basically describes an ETL (Extract, Transform, Load) process - automated as a Conductor workflow. In this post, we'll go in-depth as to how the workflow is constructed - examining what each task does. This workflow will run daily at midnight GMT, ensuring that the data in our Orbit instance is always up to date with the data on GitHub.
Our workflow looks as follows:

Starting the Workflow
We initiate the workflow with the following input data:
{ "gh_account": "netflix", "gh_repo": "conductor", "star_offset": 3800, "gh_token": "<github_api_key>", "orbit_workspace": "oss-stats", "activity_name": "starredConductor", "orbit_apikey": "<orbit_api_key>"}
The first 4 entries are GitHub parameters:
- GitHub account hosting the repo
- GitHub repo name
- Star offset (there is no reason to get stars 0-3800 - they will be unchanged)
- GitHub API token
The last 3 entries are Orbit parameters:
- The Orbit workspace to upload the data into.
- Every Activity in Orbit has a name.
starredConductoris how we mark when conductor has been starred. - The Orbit API key to authenticate our uploads.
With this data, we can now walk through the workflow. We'll begin with the first two tasks that are used to further setup the workflow:
Workflow Setup Tasks
The first two tasks in our workflow are setup tasks that help to set the stage and successfully complete the workflow:
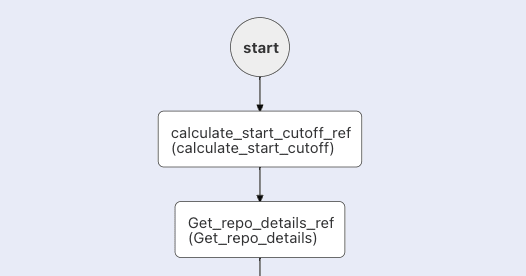
- calculate_start_cutoff is an INLINE task. As this workflow runs every 24 hours, we only want to add "new stars" that have occurred in the last 24 hours. This task uses JavaScript to get the cutoff time of 24 hours previous:
{ "name": "calculate_start_cutoff", "taskReferenceName": "calculate_start_cutoff_ref", "inputParameters": { "evaluatorType": "javascript", "expression": "new Date(Date.now() - 86400 * 1000).toISOString();" }, "type": "INLINE" }
The expression takes the current time, and subtracts the correct number of milliseconds to get the time 24 hours previous.
- Get_repo_details : This is a HTTP Task that polls the GitHub repository. This will give us general information about the repo (in this case netflix/conductor). One of the items is the total number of stars. We use this to understand the upper bound of our stargazer query (start at 3800, end at whatever this value is).
With this data obtained, we can now begin OUR ETL by Extracting and Transforming the data from GitHub.
Extracting data from GitHub

The next section of the workflow extracts the data from GitHub. The main feature of this section is a DO/WHILE loop called get_all_stars. The GitHub API only provides 100 results at a time, so we can utilize a loop to grab more than 100 entries from GitHub. We have our "start" cutoff value from the input JSON, and the end cutoff from the total number of stars, so this loop calculates how many times a query must be made, and then loops through these queries.
Here's how the DO/WHILE completes the calculation:
"inputParameters": { "offset": "${workflow.input.star_offset}", "stargazers": "${Get_repo_details_ref.output.response.body.stargazers_count}" }, "loopCondition": "if ($.get_all_stars_loop_ref['iteration'] < Math.ceil(($.stargazers-$.offset)/100)) { true; } else { false; }",
The input parameters give us the start number (the star_offset input parameter - which in this example is 3800), and the total number of stars (stargazers).
The loop condition will continue as long as there are stargazers to grab. For example, on May 16, 2022, there are 4319 stars for Netflix Conductor. 4319-3800 (the initial offset) is 519. As each GitHub response contains a max of 100 items, so we'll need 5.19 calls to GitHub. The Math.ceil rounds this up to 6 for us.
With this loop mechanism in place, there are three tasks run in each loop:
pagination_calc_ref : The GitHub stars 3800 - 3899 will occur on page 39 of the GitHub results (there is a off-by-one issue where where page 1 consists of entries 1-99). However, the DO/WHILE iterator starts with the value of 1. This INLINE task uses JavaScript to create the GitHub page counter:
parseInt(offset/100) + iterator- loop 1 will start at page 39 in our example.100_stargazers : Using the workflow input data - GitHub owner, repository & API key - along with the pagination calculated in the previous task, we can extract 100 entries from GitHub.
Transforming data from GitHub
- jq_cleanup_stars This task takes the large output from GitHub and simplifies it to only display the values we require for Orbit. We will also format the JSON to match the format that Orbit requires for inputting the data.
To do this, we use the JQ Transform Task. There is a lot going on here, so we will unpack this step by step:
{ "name": "jq_cleanup_stars", "taskReferenceName": "jq_cleanup_stars_ref", "inputParameters": { "activityName": "${workflow.input.activity_name}", "starlist": "${hundred_stargazers_ref.output.response.body}", "queryExpression": "[.starlist[] | select (.starred_at > \"${calculate_start_cutoff_ref.output.result}\") |{occurred_at:.starred_at, title: \"${workflow.input.activity_name}\", member: {github: .user.login}}]" }, "type": "JSON_JQ_TRANSFORM" }
For inputs, we take the activityName (in this case starredConductor), the list of stars starlist from the last task, and then run it through a JQ query.
The queryExpression
Our queryExpression uses the startlist[] array.
The first argument (between the pipes):
select (.starred_at > \"${calculate_start_cutoff_ref.output.result}\")This compares the starred_at value in the GitHub output to the calculated cutoff. This filters the list of GitHub Stars to only those where the star action occurred in the last 24 hours. If the entry is "new", we can continue with the transformation.Now that we have determined that the data fits our timing criteria, we can build the JSON input in the format that Orbit requires:
|{occurred_at:.starred_at, title: \"${workflow.input.activity_name}\", member: {github: .user.login}}]
-
occurred_at: When the activity occurred (GitHub calls this starredAt) -
title: The name of the activity to record in Orbit. -
member.github: The only information we have about the member is their GitHub username, so we add that to the activity.
Once the DO/WHILE loop has completed, we will have all of our newly starred users identified and parsed into a JSON array that Orbit understands for upload.
Additional Transformations
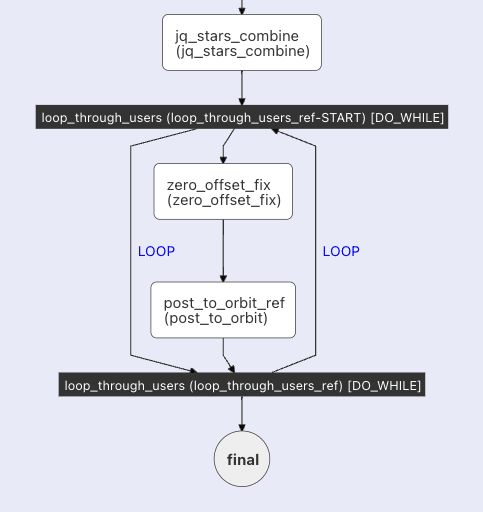
The output of our DO/WHILE is a JSON array of outputs from all of the tasks. This means that in our example data, we have an array of 6 with outputs from all three tasks.
The first task after the loop is jq_stars_combine. This is another JQ transform that combines all of the Orbit formatted input into a single JSON array.:
{ "name": "jq_stars_combine", "taskReferenceName": "jq_stars_combine", "inputParameters": { "bigList": "${get_all_stars_loop_ref.output}", "queryExpression": ".bigList[].jq_cleanup_stars_ref?.resultList?[][]" }, "type": "JSON_JQ_TRANSFORM", "decisionCases": {}, "defaultCase": [], "forkTasks": [], "startDelay": 0, "joinOn": [], "optional": false, "defaultExclusiveJoinTask": [], "asyncComplete": false, "loopOver": [] },
the bigList is the large output from the DO/WHILE list. the JQ query extracts just the results from each iteration of the jq_cleanup_stars_ref and combines them into one JSON array.
Uploading the data to Orbit
If the Orbit API allowed us to upload all of the entries at once, we could go ahead and do that with the output of the last task. But that is not the case, each activity must be uploaded individually.
To accomplish this, another DO/WHILE loop loop_through_users is used to go through all of the entries in jq_stars_combine:
"inputParameters": { "activities": "${jq_stars_combine.output.resultList}" }, "loopCondition": "if ($.loop_through_users_ref['iteration'] < $.activities.length) { true; } else { false; }",
For each activity, 2 tasks are run:
-
zero_offset_fix: The DO/WHILE iterator starts at 1, but the JSON array of activities starts at index zero. To avoid an 'off-by-one' error, we subtract one from the iterator, and extract the entry from the counter using an INLINE task and a little bit of JavaScript.
{ "name": "zero_offset_fix", "taskReferenceName": "zero_offset_fix", "inputParameters": { "iterator": "${loop_through_users_ref.output.iteration}", "jsonList": "${jq_stars_combine.output.resultList}", "evaluatorType": "javascript", "expression": " $.jsonList[$.iterator -1];" }, "type": "INLINE" },
-
post_to_orbit: Now that we have determined which entry will be uploaded to Orbit, this HTTP Task sends the data.
{ "name": "post_to_orbit", "taskReferenceName": "post_to_orbit_ref", "inputParameters": { "http_request": { "uri": "https://app.orbit.love/api/v1/${workflow.input.orbit_workspace}/activities", "method": "POST", "headers": { "Authorization": "Bearer ${workflow.input.orbit_apikey}" }, "body": "${zero_offset_fix.output.result}", "readTimeOut": 2000, "connectionTimeOut": 2000 } }, "type": "HTTP" }
Avoiding Rate limiting
The Orbit API has a rate limit of 120 entries/minute, and if the daily upload is over 120 entries, it would be possible that the last task might get rate limited by Orbit. To avoid being rate limited, we can Extend the task. This means that we create a task in our Conductor instance called post_to_orbit and add two additional parameters:
"rateLimitPerFrequency": 100, "rateLimitFrequencyInSeconds": 60,
This tells Conductor that any calls to the post_to_orbit task - no mater which workflow in our Conductor instance calls the task - must be limited to 100 calls per 60 seconds. This will prevent our workflow form failing because of being rate limited by the Orbit API.
Scheduling the workflow
In the Orkes Cloud (and in the Orkes Playground), there is a function called the Scheduler (This is coming soon to the Open Source Conductor). The Scheduler gives the power to schedule your workflows on an regular interval. The interval chosen for the GitHub to Orbit workflow is 0 0 0 * * ? meaning that the workflows will be run every day at 12:00 AM GMT.
With automatic scheduling of the workflow, the Netflix Conductor Star data is uploaded daily from GitHub to Orbit with no human interaction required!
Conclusion
This workflow is an example of a ETL workflow - we Extract data from GitHub, Transform the data and then Load the data into Orbit. It runs automatically every 24 hours.
Prior to building this workflow, the data had to be pulled manually, updated in a spreadsheet and then uploaded via CSV to Orbit. By automating the process with Netflix Conductor (in the Orkes Cloud), we ensure accurate and regular updating of the "stargazers" of Netflix Conductor in our Orbit data workspace.

Top comments (0)