Source control is the backbone of any DevOps setup. In fact, source control is also the backbone of any software development endeavor. It’s not a question of why SCM, it’s a question of which one?
The next question is how best to use it. As a company that started from a very low developer count a few years back, we had a certain set of processes which were ideal for the situation at that time. Now with around 30 odd developers, we found ourselves soon outgrowing the same ideal processes. This was reflected in many instances of botched deployment (luckily only on Staging), overwritten code and merge conflicts. We then began tweaking our processes and in due course, we have become many times more efficient.
This post chronicles that scaling a journey from a small team that used a simple strategy to the present system where all these people are working together without stepping on each other's metaphorical toes. It also details the branching policy we set up and delves into how we created our testing and DevOps processes around the new branching model.
An oversimplified overview
Before I jump into explanations on our older and present processes and git strategy, I would like to show you a customer’s view of pCloudy just for reference.

At a very high level, pCloudy is a cloud based SAAS that hosts physical mobile phones and tablets which you can access through your browser and can use for your mobile apps testing needs.
A very basic view of our cloud architecture is as follows.
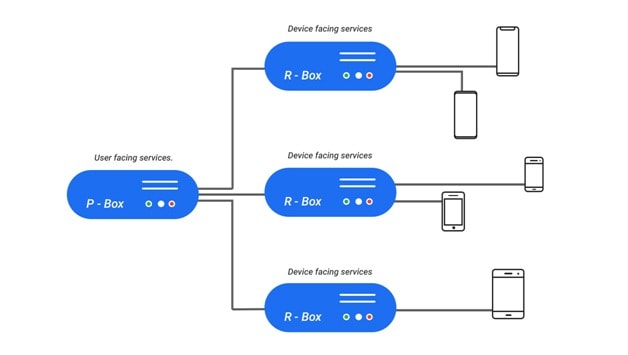
We have a bunch of services running on the cloud which together we call as the pBox (pCloudy’s Box of services). We also have some physical machines to which the phones and tablets on our cloud are connected. We call them the rBoxes (remote box, this one is an actual physical box). Mind you this is a heavily oversimplified view. I have glossed over some of the complexity and oversimplified some details here, else I will end up spending the next several blogs explaining only this. But this simpler representation will help you understand our overall cloud better.
We have a Dev cloud and a Staging cloud in the architecture mentioned above. These are for our internal development and testing respectively. Both these clouds are replicas of the production public cloud. The difference is mostly only in scale.
Teething problems
Now that you have a basic idea of our processes and our architecture, let us dig deeper. I will start by explaining the process that we followed when we were a smaller company and had very few developers. At that time almost all developers worked on different software components independently. Each component had a repo in git. Thus there usually was only one person handling code per repo. This was a very good scenario since every developer knew all the changes happening in their repo inside out and in most cases you could be sure, your changes would work on production once you have tested on your machine, not that I advocate direct deployments to production. That was a simpler time, and our setups were simpler. At that time, the only strategy regarding source control was that we needed to use one. Primarily because no need was felt for more sophistication. (and the resulting complexity).
But as our headcount increased we ran into issues. Being able to constantly keep increasing headcount is an indicator of success, but that comes with its own set of problems. The primary one being managing the code’s journey from the developer’s computer to the cloud. Our major architectural blocks and software components more or less remained the same, but most components now have multiple people working on it, one of them usually being a new employee. This person is not only new to the team, but also has no idea of the nuances of the process that we used to follow before they joined. More people also meant more points of failure.
So what did we do? We did small tweaks. And kept doing those tweaks. And never stopped.
Evolution over Revolution
So why small tweaks? Why not bigger changes? Well, as a matter of philosophy, our approach is to avoid disruptive big bang changes in a running system unless it is unavoidable.
What we realized early on is that a copy-paste job of what worked elsewhere may not work here. Every company is different. And so are the constraints that each team works under. I am not claiming that our problems are more difficult, just that they are different. For similar reasons, we do not directly start implementing a process just because it showed results elsewhere. I will give examples of this as we go ahead in this series. But for now, it was clear that while we are not going to reinvent the wheel, we are also not going to be very successful taking someone else’s wheel and fitting it on our vehicle without much thought.
Like a lot of startups, when we started up, our goal was to make the most awesome product that we could make and not be an Agile/DevOps champion. Starting out with any other goal, in my opinion, is neither smart nor would it have taken us far. Because the product is the reason for us to exist. Also while there is a lot of data and material on Agile and good DevOps, what really matters is how you take each principle and implement it for your team in such a way that your team’s and business productivity is more than it was before it was implemented. If this condition is not met, then either you have not done your implementation right, or your team is not yet ready for that.
So we did small tweaks? Many of them over time. Till the needs are met. And we will keep doing them if our needs change.
Our Tweaks
Most of our tweaks were in the following few areas.
Git branching model.
Approval of code review.
Mapping branches to environments.
Let me now explain in a bit of detail
As I said before earlier we did not have any standard branching model. And since there were fewer people working, deployment was not much of a hassle. But as our team strength increased, problems started cropping up. Especially when more than one developer worked on the same files in the same repo.
The main problem we saw was developers were inadvertently overwriting code written by other developers. This usually was because someone pushed their code into the repo without first checking if someone else had also done the same. This is a human problem. It is very easy to make this mistake. Humans forget stuff. Briefly, we experimented with a checklist to be followed by developers before pushing code into the source control. But the results were not conclusive.
So we pivoted. We forced standardization of our git branching model. This change was bigger than a simple tweak. It was a relatively big change but we went ahead because it was not avoidable. And previous lack of a standard process had the potential to hurt us in the future. Now two years later, this looks like a no brainer. But we did spend a lot of time deliberating over this before finally choosing git-flow. We derived our branching model from that. You can find detailed explanations of the model here, here and here. But let me summarize below what git flow is and why we chose it.
Git Flow
This diagram here is a good summary of what git-flow looks like.

Essentially what Git flow provides is what I call a “Staged Promotion” of code. You have various git branches (usually Master, Develop and multiple Feature branches). Depending on what stage of development your particular feature is in, your code will reside in a different branch. Your feature (or bug fix, or enhancement) starts its life in a feature branch, a branch created specifically for that feature. A developer does their development there and once they are satisfied of the feature’s completion, the code is pushed to the Develop through a pull request. The pull request then gets reviewed and merged. This fulfills an important goal. When you push code to the any Branch, you do that through a pull request and that forces a code review. Your work cannot progress without it. This, in my opinion, is the biggest advantage of a “Pull-request” based process. You can do as many changes here as needed, the only thing to note is that your code gets deployed from git and not through random copying or modification of individual files. This is the branch where code from all other developers get integrated and verification happens. Once verified, the code is deployed and pushed to master.
This allows for a stage by stage verification of code with the code getting promoted after every stage is complete. Also because of the fact that promoting the code needs pull requests, code review is built into the process.
Git Flow with our approach
Our process is derived from git-flow but is not exactly the same. We have more branches, (Features, Dev, Staging, Master) more or less to make sure that our Dev and Staging clouds are used properly. In our case, development starts on a feature branch and when the developer is satisfied with his work on his machine, he sends a pull request to the Develop Branch. Once the pull request is approved, the code gets deployed on the Dev Cloud from the Dev branch.
Once you have seen that your code is working properly, you push it to the test branch in the same manner to enable formal verification of the setup. The code on the test branch gets deployed on the Staging environment. Here your code gets extensively tested before it is declared pass or fail.
If it passes, then you have permission to send a pull request to the master. The code in master corresponds to what we have in production. If it fails, then it goes back to the dev branch or his feature branch for the developer. The developer fixes the code and then starts the same process again. This ensures that we break the code as less as possible and if we ever do, it is usually because the process hasn’t been followed.
Now the next question is what happens to the code that is deployed to the test branch and the Staging cloud after tests fail. We periodically reset the internal clouds from master. This unpromoted code gets automatically discarded during such a reset. This is crucial, else you will have code in your Develop or Staging environments that you never intend to push to production.
So this was overall our Git Branching strategy. But before I finish this blog, I would like to leave with a set of other insights that we gained while perfecting this part of our devops.
bInsights
Never get a human to look for mismatched brackets: I have lost count of the number of times we have had failures in Staging and sometimes Production too because of simple errors like mismatched brackets or missing commas in a json structure or something that looks equally trivial. And this has led us to wonder how something like this was missed in so many code reviews. And then the coin dropped, we realized that errors like this are indeed difficult for the human eye to see. So we settled for the next best thing. Static Analyzers for the code. And after we used one, we began to wonder how did we ever live without one till now. There are literally hundreds of them in the market. We chose CodeFactor, partly because it integrates with github and you see all the defects directly in your pull requests and partly because it works with many languages.
Small is beautiful: At least with check-ins and pull requests, we have discovered that smaller but numerous check-ins and pull requests are the way to go. It is far easier to review smaller deltas. It is also far easier to revert if there are problems. Also smaller changes are easier to test and certify.
Code Review works best in person: Granted, github (and others) gives you a very sophisticated UI where you can see the code delta in a diff-view and also allows you do have a conversation about the code and the changes. But I have seen that the best review happens in person. Face time is the best, if you have a query about a a review comment on your pull request, it is always better to just walk up to the person in question and clarify rather than lazily type a one line response. At best you will receive another response which may or may not finish the clarification, and at worst you will end up with a long chain of back and forth after which you give us and have a face to face conv. Sometimes your reviewer may even ignore because they have more pressing things to do, in all these cases it is your loss.
So that’s all I have for today. Feel free to respond through comments. I would love to continue the conversation. Keep watching this space, there will be more blogs from me about the insights and learnings we gained doing DevOps in a startup.

Top comments (0)