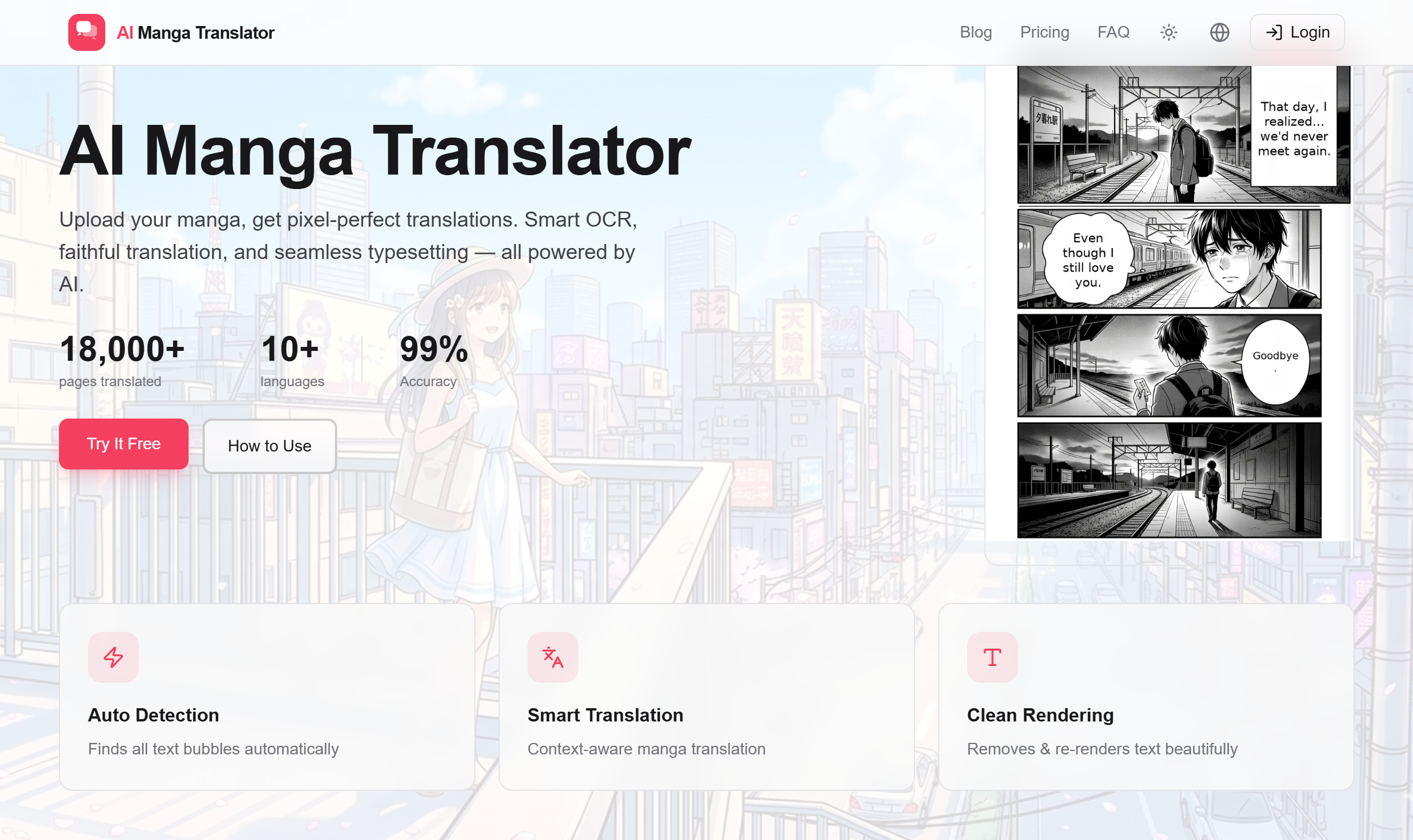
Traditional OCR-then-translate pipelines are failing. Here is why manga localization requires a structural vision approach.
The Problem: Why Most Manga Translators Feel "Broken"
If you’ve experimented with building a manga translator, you’ve likely hit the same wall. You plug in a world-class LLM, but the output still feels awkward, fragmented, or just plain wrong.
Most developers blame the translation model. They’re looking at the wrong end of the pipe.
In real-world usage, as I’ve broken down in my detailed analysis of OCR bottlenecks on Medium, the failure starts long before the LLM sees a single word. It starts with the input quality.
The Computer Vision Nightmare: Manga is Not a Document
Traditional OCR (like Tesseract or generic Cloud APIs) is built for horizontal, clean, black-on-white text. Manga is the exact opposite:
Vertical & Diagonal Text: Japanese text flows in every direction.
Art-Text Overlap: Dialogue is often part of the artwork, distorted for emotional effect.
Complex Layouts: Non-standard reading orders make simple left-to-right scanning useless.
If your OCR misses a single bubble or breaks a vertical sentence into three separate fragments, your LLM is dead on arrival.
The Solution: From OCR to Layout-Aware CV
To build a professional-grade tool like AI Manga Translator, we had to stop treating OCR as a preprocessing step and start treating the page as a *visual entity.
*
](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fwfhp2tkehgymupg7ba7k.png)
Here are the three pillars of a high-performance manga localization architecture:
1. Segment-First Strategy (Panel Segmentation)
Before you detect text, you must detect the Panels. By understanding the physical structure of the page, the AI gains a "Contextual Map." This prevents the system from merging dialogue from two different scenes—a common failure in generic tools.
2. The Contextual Glue
A truly Layout-Aware system uses spatial logic to group text fragments. If a speech bubble is physically split by a character's hair or a panel border, the CV layer must recognize it as a single semantic unit. Without this "glue," you aren't translating a story; you're translating a list of words.
3. Abolishing the OCR-then-Translate Silo
We moved away from the linear "Detect -> Recognize -> Translate" pipeline. Instead, our architecture uses a Context-Aware Feedback Loop. The system uses the surrounding layout and previous panel data to "predict" the most likely text in a noisy background.
Why This Matters for Global Creators
The goal isn't just translation. It's Localization.
Users don’t want to manage a Python pipeline or maintain a GPU cluster just to read their favorite series. They want a frictionless experience where the AI understands the art as much as the language.
By solving the Layout-Aware OCR problem, we’re not just translating words; we’re preserving the artist's intent and making high-quality localization accessible to everyone.
What’s your biggest challenge when dealing with non-standard OCR? Let’s discuss in the comments.
I’m Peter Anderson, building privacy-first tools for the global manga community at [AI Manga Translator](https://ai-manga-translator.com/). Stay shipping!
Korean interface here.

Top comments (0)