
We all know, or should know, about SOLID. The question is, do we write C++ according to the SOLID principles?
The reason for creating this tutorial is that despite a lot of great resources and videos on the SOLID principles, I could not find anything that uses C++ for its examples. Naturally, there isn't any fundamental difference in the SOLID principles themselves when writing in C++. The problem is that, as a C++ developer, when you hear people preaching about a certain way of working and you do not find any examples you can directly relate to, then you may feel reluctant and disconnected.
I find the SOLID principles not only compatible with but also, directly or indirectly promoted by the latest C++ core guidelines. Therefore, the goal of this tutorial is to show that the SOLID principles are not only relevant to C++, but also very beneficial for software targeting specialized domains such as embedded systems.
Before moving on to concrete C++ examples on how to write and refactor C++ according to SOLID principles, let's get over the practicalities. What is SOLID?
As I mentioned before there are a lot of great resources online on the principles so I will not expand on this further. Go do your research. I will just quote the Wikipedia introduction on the topic:
SOLID is an acronym for five design principles intended to make software designs more understandable, flexible, and maintainable. They are a subset of many principles promoted by Robert C. Martin. Though they apply to any object-oriented design, the SOLID principles can also form a core philosophy for agile development.
Source: wikipedia.org/wiki/SOLID
In a nutshell, if you work agile, these are probably some principles you want to look into.
Let's have a deeper look into the SOLID principles.
I will be first running a short introduction and then showing code that does not comply with each principle. In the end, I will offer suggestions on how to refactor it.
I do warn you that the examples will not necessarily be "textbook cases" since I often find them hard to relate to. Instead, I will show you examples inspired by real projects.
Single Responsibility principle
A class should have only one reason to change
As the name implies it requires each module, let's say class, to have responsibility for one and only one purpose.
To put it differently, the class should only have one "reason" to change.
By reason, we may for example mean a change in the specification of -a- requirement.
This principle enables you to write software with high cohesion and robustness since it's not going to be influenced as much as your system evolves. Below are some examples.
struct PhotoUploader {
PhotoUploader(Camera& camera, CloudProvider& cloudProvider);
Image getImage();
Image resizeImage(int x, int y, const Image& image);
void uploadImage(Image& image);
};
Have a look at the PhotoUploader class.
It depends on two resources: a Camera and a CloudProvider. The dependencies, combined with the name of the class, which implies that it merely uploads photos, should start making you suspicious.
If we move towards the member functions, we can see that the class has more than one responsibility. It takes pictures as well as resizes the images (which depending on the context you may count as one or two purposes already) and uploading images.
The problem with this class is that as soon as we encounter a change in the way that we upload stuff on the internet, the size of the image, or the way we use the camera, this class has to be refactored.
This was a relatively straight forward example, but let's discuss one with a slightly more subtle violation of the Single Responsibility principle.
const string kPrefix = "user-";
struct UserManager {
UserManager(Database& database) : db{database} {}
void createUser(string username) {
if (!username.startsWith(kPrefix)) {
username = kPrefix + username;
}
db << "insert into users (name) values (?);" << username;
}
string getUsersReport() {
vector<string> users;
db << "select name from users" >> [&users](string user) {
users.push_back(user.erase(0, kPrefix.length()) + ",");
};
return users;
}
};
For the better or the worse, violations of the single responsibility principle are not always going to be so straight forward.
We have UserManager which depends on some kind of Database. It can create users and fetch the users' report.
One could argue, that creating a report may be counted as an additional purpose, but let's be lenient and claim this is considered part of the same responsibility.
My first and weakest objection would be the inclusion of the SQL query into a higher level class. I would argue that the database schema should not be something that modules except the database should be concerned with. But in any case, let's assume that the Database class is a very thin wrapper.
The biggest issue I see is that the UserManager class is responsible for the formatting of the user name both before inserting it into the database but also when extracting it out.
This effectively means that the UserManager class becomes responsible for two things:
- Input and output from the database based on a certain schema
- Formatting strings that get stored in the database
If we get any requirement change in the database schema or the way we are supposed to store names in it, we will have to refactor the class.
Additionally, if we want to reuse UserManager for a different product, we will either be forced to adopt the same schema and username format or rewrite the class!
My solution to this would be to split things up in classes that have a single purpose.
struct DatabaseManager {
virtual ~DatabaseManager() = default;
virtual void addUser(string username) = 0;
virtual vector<string> getAllUsers() = 0;
};
struct MyDatabaseManager : public DatabaseManager {
MyDatabaseManager(Database& database);
void addUser(string username) override;
vector<string> getAllUsers() override;
};
struct UsernameFormatter {
virtual ~UsernameFormatter() = default;
virtual string format(string username) = 0;
virtual string getReadableName(string input) = 0;
};
First, we create the DatabaseManager abstract class. It offers the capability to add and retrieve users. Its concrete implementations most likely will be using the Database itself and be responsible for the SQL queries and the project-specific schemas.
Second, I would add a UsernameFormatter interface. This interface would encapsulate the project-specific way of formatting usernames when importing and exporting from the database.
This would leave us with a UserManager class, that depends on the DatabaseManager and UsernameFormatter interfaces. It is only responsible for handling the high-level user and user report creation.
This would allow the UserManager class to be reused across projects and also be indifferent to changes in the schema and the format of the database contents.
Next up? The Open/closed principle!
Open/closed principle
Software entities should be open for extension, but closed for modification
The open/closed principle is an interesting one, mainly because it evolved through time along with the programming languages. The principle dictates the software modules are open for extension but closed for modification. This allows new functionality to be added without changing existing source code.
In practice, the best way to achieve this with C++ is polymorphism. Particularly, with the use of abstract interfaces, we can extend a class and specialize its behavior without changing the interface specification. This principle allows for reusable and maintainable software.
Let's start by looking at a counterexample. Something you should not do.
enum class SensorModel {
Good,
Better
};
struct DistanceSensor {
DistanceSensor(SensorModel model) : mModel{model} {}
int getDistance() {
switch (mModel) {
case SensorModel::Good :
// Business logic for "Good" model
case SensorModel::Better :
// Business logic for "Better" model
}
}
};
In this snippet we have a DistanceSensor class, that depending on the way we have initialized it, it effectively represents a different sensor.
Unfortunately, our class design does not allow the behavior to be extended unless we modify the source.
For example, if we want to add a new sensor model, we would have to change the DistanceSensor class to accommodate the new functionality.
By defining and implementing an interface, we avoid having to alter that switch statement in a way that can make things quickly very inconvenient for us.
struct DistanceSensor {
virtual ~DistanceSensor() = default;
virtual int getDistance() = 0;
};
struct GoodDistanceSensor : public DistanceSensor {
int getDistance() override {
// Business logic for "Good" model
}
};
struct BetterDistanceSensor : public DistanceSensor {
int getDistance() override {
// Business logic for "Better" model
}
};
We start by defining what we want a DistanceSensor to do in general. Remember, a DistanceSensor is something generic, i.e. it does not have a model, therefore it does not make any sense to have a concrete instance of it.
Therefore we need to define DistanceSensor as a pure abstract class or, an interface, as we would say in other languages such as Java.
Then, we create specializations of the interface, for each of the different DistanceSensor models that we have. Every time we want to add a new sensor, we can create a new child class that implements the DistanceSensor interface, without changing any of the existing classes.
Liskov substitution principle
If
Sis a subtype ofT, then objects of typeTin a program may be replaced with objects of typeSwithout altering any of the desirable properties of that program (e.g. correctness)
This principle requires subclasses to not only satisfy the syntactic expectations but also the behavioral ones, of its parents.
To view things from a different perspective, as a user of a class, I should be able to utilize any of its children that may be passed to me without caring about which particular child I am calling.
This means we have to ensure that the arguments as well as all the return values of the children are consistent.
The code examples illustrate why we must be able to switch or substitute among any of the parent's children, without altering the behavior specified by the parent, in particular, the interface.
struct InertialMeasurementUnit {
virtual ~InertialMeasurementUnit() = default;
virtual int getOrientation() = 0;
};
struct Gyroscope : public InertialMeasurementUnit {
/**
* @return orientation in degrees [0, 360)
*/
int getOrientation() override;
};
struct Accelerometer : public InertialMeasurementUnit {
/**
* @return orientation in degrees [-180, 180)
*/
int getOrientation() override;
};
Here we have an InertialMeasurementUnit. The IMU.
The IMU is something generic but specifies a behavior for every class that specializes it. Particularly, it provides its users with the ability to get the sensor's orientation.
The problem begins when different sensors, that is, the different children that implement the interface, return the orientation in different ranges. For example, we have a Gyroscope that returns an orientation that is always positive, between 0 and 360 degrees, while the Accelerometer provides an output that can be negative. Something between -180 and positive 180.
If we had a class that should be able to use any IMU sensor, that class would read results that should be interpreted differently depending on the underlying sensor.
Naturally, this would cause problems if not addressed. Architecturally, having a class that is supposed to work with any kind of sensor but actually needs to know what kind of sensor it is, is a definite smell.
In practice, you will see the violation of this principle manifesting itself either in bugs or calls to methods that reveal information about the child specializing the interface. For example a getIMUModel() function in the abstract interface.
struct InertialMeasurementUnit {
virtual ~InertialMeasurementUnit() = default;
/**
* Sets the frequency of measurements
* @param frequency (in Hertz)
* @return Whether frequency was valid
*/
virtual bool setFrequency(double frequency) = 0;
};
struct Gyroscope : public InertialMeasurementUnit {
// Valid range [0.5, 10]
bool setFrequency(double frequency) override;
};
struct Accelerometer : public InertialMeasurementUnit {
// Valid range [0.1, 100]
bool setFrequency(double frequency) override;
};
As previously mentioned, the child classes have to be behaviorally consistent not just in the return values, but also in the arguments they receive.
Above, we have an example where we must supply a frequency to a child of the InertialMeasurementUnit class, but different children receive arguments in different ranges. If an invalid argument is supplied, the children may throw an exception, return an error value, or even worse, behave in an undefined manner since the actual sensor would not be able to make sense of the information we pass to it.
There are two ways to solve this. The first one is to ensure that all children behave consistently. We should be able to substitute any of the children and the classes that use them to be valid.
If that is for serious reasons not possible, we should reflect on whether it makes sense to have the particular class hierarchy. We should ask ourselves:
- Does that interface make sense?
- Must we really enforce the particular child-parent relationship?
The second way would be our last resort. We may try to expose as little information about the child as possible:
struct InertialMeasurementUnit {
virtual ~InertialMeasurementUnit() = default;
/**
* Sets the frequency of measurements
* @param frequency (in Hertz)
* @throw std::out_of_range exception if frequency is invalid
*/
virtual void setFrequency(double frequency) = 0;
/**
* Provides the valid measurement range
* @return <minimum frequency, maximum frequency>
*/
virtual pair<double, double> getFrequencyRange() const = 0;
};
Interface segregation principle
No client should be forced to depend on methods it does not use
Moving on, time to contemplate the interface segregation principle.
This principle is rather straightforward and advocates for the creation of small and atomic interfaces.
Specifically, it is better to have many single-purpose interfaces, than a single (or few) multi-purpose ones.
This enables our software to be more reusable and customizable since we don't have to rely upon or implement functionality we don't use.
struct Runtime {
virtual ~Runtime() = default;
virtual void sendViaI2C(vector<byte> bytesToSend) = 0;
virtual vector<byte> readViaI2C(int numberOfBytesToRead) = 0;
virtual void sendViaUART(vector<byte> bytesToSend) = 0;
virtual vector<byte> readViaUART(int numberOfBytesToRead) = 0;
virtual void setPinDirection(int p, PinDirection d) = 0;
virtual void setPin(int pin) = 0;
virtual void clearPin(int pin) = 0;
};
Here's a possible specification of an interface that represents a Hardware Abstraction Layer for an imaginary microcontroller.
The problem is that this interface will get progressively larger as we want to utilize more and more different parts of the hardware layer.
The larger the interface gets, the less maintainable and reusable it becomes. For example, additional work will be required if we wanted to port it to a different system.
To make things worse, having to implement a large interface means that you may have to implement things you don't have any use of.
A very characteristic indication the Interface Segregation principle is violated, are child classes with functions that have an empty implementation. The functions are merely there to satisfy the interface specification, not a meaningful specialization.
struct SerialManager {
virtual ~Manager() = default;
virtual void registerReceiver(function<void(string)> receiver) = 0;
virtual void send(string message) = 0;
virtual void readLine() = 0;
};
struct MySerialManager : public SerialManager {
void registerReceiver(function<void(string)> receiver) override;
void send(string message) override;
void readLine() override;
};
There are more subtle violations of the Interface Segregation principle.
Let's assume the SerialManager interface. It exposes functionality to send, receive and subscribe on keys sent via the serial port.
Then, we have a MySerialManager implementation that exposes the said functionality.
The problem arises if we take into consideration the different objectives of the classes that utilize the interface and the ones that implement it.
Particularly, users of the SerialManager interface just want to communicate over UART and don't really care about reading the stream directly.
That's why we have the MySerialManager class there.
How we want these users to operate is by subscribing on certain keys and then wait for the callback they have registered to be invoked. Additionally, they may opt to send something back.
The problem with exposing the readLine() function to the users of the SerialManager is that the interface relays an ambiguous intent to its users. Specifically, we give the users two possible ways to do things, but in reality, we only want them to use one!
struct SerialClient {
virtual ~SerialClient() = default;
virtual void registerReceiver(function<void(string)> receiver) = 0;
virtual void send(string message) = 0;
}
struct SerialReader {
virtual ~SerialReader() = default;
virtual void readLine() = 0;
};
struct MySerialManager : public SerialClient, public SerialReader {
void registerReceiver(function<void(string)> receiver) override;
void send(string message) override;
void readLine() override;
};
To comply with the Interface Segregation principle, we can break down the old SerialManager interface into two separate ones.
A SerialClient interface that exposes the functionality of a typical client that wants to communicate over UART by subscribing to keys. This is the interface that other classes most likely want to depend on.
Then we have a SerialReader interface that only includes the readLine function. If someone needs to read from serial, they can use that interface.
Here, you should note that the implementation of the MySerialManager does not change. It remains the same. The only difference is it now implements two interfaces instead of a single one.
Dependency of Inversion principle
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g. interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Last but absolutely not least, we have the Dependency Inversion principle.
This is one of my favorite principles and goes hand in hand with Inversion of Control design patterns.
What do the principle's dimensions practically mean?
In traditional layered architectural styles, the higher-level components which implement the system's application logic, depend on lower-level components that contain the domain logic. Let's delve into a simplified case common in embedded Linux systems:
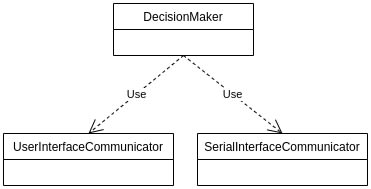
We are building middleware that receives signals from the UI and, depending on the business rules, sends messages over serial.
The components that decide what should happen depending on the received messages are the high-level ones, while the ones responsible for the communication with the UI and the Serial port are the low-level ones.
As expected from a layered architecture, the business or application logic components would be using the communication components.
In this example, we have DecisionMaker which uses, or depends on, the UserInterfaceCommunicator and the SerialInterfaceCommunicator.
The problem is that our application logic is tightly coupled with the domain logic. To put it differently, even if our DecisionMaker operates depending on the business rules, it won't be reusable in different settings for example in different products. That is, unless we use exactly the same implementation for the user interface and the microcontroller that we talk to.
We don't want to be forced to use the same implementation because our product needs to evolve and differentiate. So how do we fix this?

We abstract the essence of the lower-level components in interfaces. Then, we design our higher-level component to depend on those interfaces instead of the implementation.
Now, we can migrate our DecisionMaker to different hardware as long as the interface to talk with the UI and the Serial port remains the same.
This effectively allows us to create new products or new iterations of the same product, without having to excessively rewrite unrelated software. We can respond to changes in the environment or the customer's needs quickly, in an agile manner.
This is how it could look like:
struct AwsCloud {
void uploadToS3Bucket(string filepath) { /* ... */ }
};
struct FileUploader {
FileUploader(AwsCloud& awsCloud);
void scheduleUpload(string filepath);
};
We need to schedule the upload of some files to the cloud, let's say AWS, and thus we create the FileUploader class.
The AwsCloud class handles uploading to the S3 Bucket where the term "S3 bucket" is specific to Amazon's Cloud services.
I see two potential violations of the Dependency Inversion principle:
Our high-level component depends on some lower-level functionality. This is fine.
Unfortunately, we do not depend on an interface, which means that we are coupled to a very specific implementation.
This means, that if we at some point decide to move to a different cloud provider, we will need to reimplement the FileUploader class, which contains logic that should be pretty much independent. Why should the FileUploader care about whether we use Azure, AWS, or Google? It just wants to schedule uploads!
We need to refactor this to decrease coupling.
struct Cloud {
virtual ~Cloud() = default;
virtual void uploadToS3Bucket(string filepath) = 0;
};
struct AwsCloud : public Cloud {
void uploadToS3Bucket(string filepath) override { /* ... */ }
};
struct FileUploader {
FileUploader(Cloud& cloud);
void scheduleUpload(string filepath);
};
A bit better now.
The Cloud interface was now created. It exposes the uploadToS3Bucket function which does the uploading and FileUploader depends on it.
However, this is still problematic. We have an abstraction, the Cloud interface, that... depends on a detail! The S3 Bucket is being mentioned.
This means that if we were to switch to another cloud provider, we would have to either add another function named after the other provider (thus complicating everything and violating other SOLID principles) or use an inaccurate name.
Both alternatives bad. It is not enough to take the header file of a concrete class and create an abstract interface out of it.
We need to carefully determine the purpose, or the capabilities we want to offer. Then, name the functions as well as the abstraction itself appropriately. We must decide names and signatures that do not leak or impose implementation details.
Ideally, our design should be specified like this:
struct Cloud {
virtual ~Cloud() = default;
virtual void upload(string filepath) = 0;
};
struct AwsCloud {
void upload(string filepath) override { /* ... */ }
};
struct FileUploader {
FileUploader(Cloud& cloud);
void scheduleUpload(string filepath);
};
Takeaways

Now that you have some examples of how to apply the SOLID principles in C++, I hope you will go forward and build or refactor your systems. On a technical level, you should be as agile as you claim your team's or company's processes to be.
If you feel what you heard does not apply to you, due to domain constraints or because you use a language that is not object-oriented, such as C, you should know that this may not be true!
From talking and watching some pioneers in the embedded software industry, the spirit of the SOLID principles is indeed applicable when using C as your programming language. It's primarily the semantics that change.
I do encourage you to look more into this yourselves.
That was about it folks. Please don't forget to like and share this tutorial to promote better software.

Top comments (0)