
Hello World 👋 🌍,
In this article, I will show how easy it can be to do Web Scraping.
I will show how to extract content ( text, HTML, links, images, etc..) form a webpage without writing code.
The only thing you will need to do is to send an HTTP request and specify CSS selectors of elements you want to scrape.
Below you can see an example of a basic request body.
A response can be an array with extracted values or it could be in JSON like format.
For the Demo I’m going to use:
1) Books to scrape — a playground for web scraping.
2) Postman — app for sending HTTP requests.
3) Proxybot — API service helper tool for web scraping.
Let’s get started 👨💻
For people who prefer watching videos, there is a quick video showing how to scrape basic webpages.
The idea is very simple, we just need to:
- Find a page we want to scrape
- Get CSS selector of desired elements
- Send HTTP POST request with a Body containing CSS selectors from step
And now the same steps but just with more details 🔎.
1) Find a page we want to scrape
We will use the ‘Books to Scrape’ (http://books.toscrape.com/) website as our web scraping playground.

The ‘Books to Scrape’ website contains dummy information about various books.
The website is ideal if you want to practice basic web scraping skills.
2) Get CSS selector of desired elements
In order to get CSS for desired elements, we need to open Dev tools of your desired browser and inspect elements.
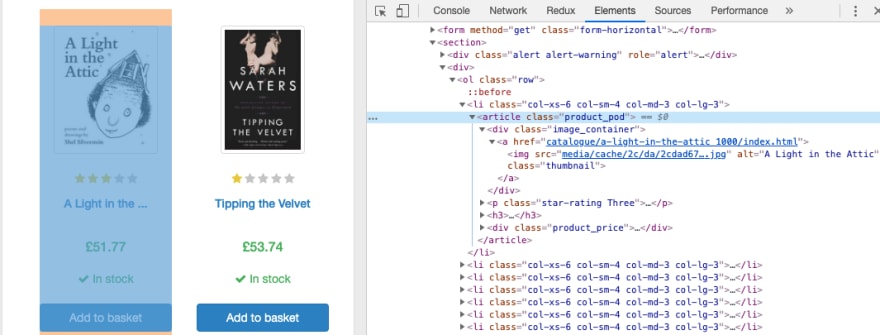
Inspecting a book element gives us the following HTML markup 🕵.
NB! We will use the above HTML for creating request objects.
3) Send HTTP POST request to API service 🚀
In the below example we will extract title and link for all the books found on the page.
Request URL :
https://proxybot.io/api/v1/API_KEY?url=http://books.toscrape.com
Request BODY:
We specify CSS selector for book’s title and request to get its value as text. However, for the link’s value, we need to instruct service to get the value from the href attribute.
The response will contain titles and links of all books on the page.
Response:
This is already super cool!
If you are interested in only specific data then this type of response might be already good enough.
However, I would like to have a formatted response, let's see how we can achieve that.
Request BODY for formatted response:
We need to ask to return “json” and provide an array with selectors in “extract” property.
Additionally, we can specify “as” property which will be used for formatting the response object.
The above request will result in the following response
Formatted response:
Wow! We can specify the format of an object we want to get back! How cool is that?
Congratulations 🥳 Now you know how to scrape websites without coding. As you can see it is pretty simple. I hope this article was interesting and useful.
In case you looking for a proxy providers, here you can find a list with TOP 7 proxy providers in 2021.

Top comments (0)