
This blog post covers the basics of time-series data and why time-series databases have seen such an explosion in popularity since the category emerged a decade ago. Additionally, we will briefly cover the origin story of QuestDB, why we set out to build a new database from scratch and go through the database design choices and trade-offs.
Time-series data and characteristics of TSDBs
Time-series data is everywhere. Sensors, financial exchanges, servers, and software applications generate streams of events, which need to be analyzed on the fly. Time-series databases (TSDB) emerged as a category to better deal with vasts amount of machine data. These specialized Database Management Systems (DMBS) are now empowering millions of developers to collect, store, process, and analyze data over time. With new time-series forecasting methods and machine learning models, companies are now better equipped to train and refine their models to predict future outcomes more accurately.
Time-Series data explained
Time series is a succession of data points ordered by time. Time-series data is often plotted on a chart where the x-axis is time and the y-axis is a metric that changes over time. For example, stock prices change every microsecond or even nanosecond, and the trend is best presented as time-series data.

Time-series data has always been plentiful in financial services with fast-changing tick price data and in e-commerce/ad-tech to better understand user analytics. With the rise in connected devices, application monitoring, and observability, time-series data is now critical in nearly all fields. We list a couple of examples below:
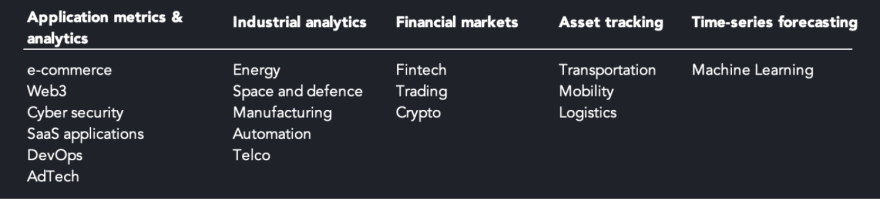
Time-series data has several unique characteristics:
- The amount of data created and processed is large.
- The amount of data flowing from the source is often uninterrupted.
- The volume is also unpredictable and can come with bursts of high volumes of data incoming at irregular intervals. This is very common in financial markets, with spikes of trading volume occurring after events, which are difficult to predict.
- Fresh data needs to be analyzed on the fly. Anomaly detection is a good example.
With the rise of time-series data, time series has been the fastest-growing database category for the past five years according to DB-engines.

Time-series databases design
As use cases and the need for time series analysis are increasing exponentially, so is the amount of raw data itself. To better cope with the ever-growing amount of data, time-series databases emerged a decade ago. They focus on performance with fast ingests to process a higher number of data points. The trade-off is less stringent consistency guarantees, which are typically must-haves for OLTP workloads. It is pretty common for time-series databases not to be ACID compliant.
Unlike traditional databases in which older data entries are typically updated with the most recent data point to show the latest state, time-series databases continuously accumulate data points over time. This way, one can draw insights from the evolution of metrics to conclude meaningful insights from the data. This is why TSDBs are optimized for write operations rather than updates. Once the data is stored in a database, most use cases require querying this data in real-time to uncover insights on the data quickly. DevOps teams will set real-time alerts to detect anomalies in server metrics such as CPU or memory. E-commerce websites need to understand buyers’ behavior to gather new insights and optimize their stock. A fintech company will want to detect fraud as transactions occur.
- Automated partitioning management
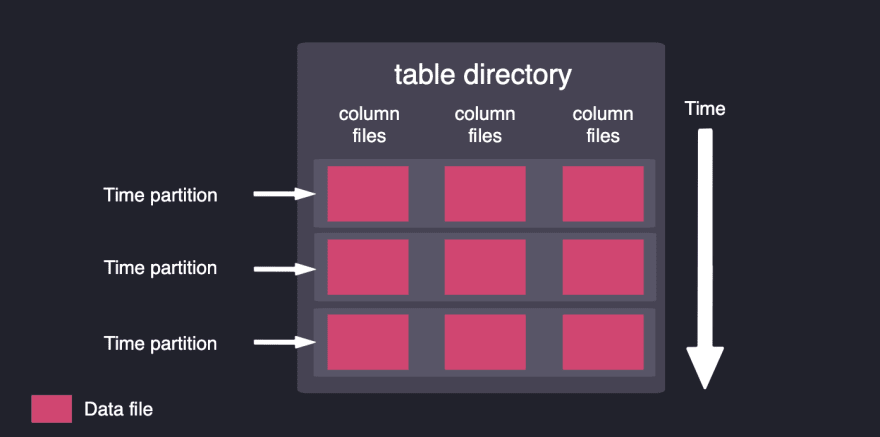
Time partitions are created automatically as data arrives. In QuestDB, data is partitioned by time (hourly, daily, weekly or monthly). Slicing the data by time partitions makes time-based queries more efficient. Time-based queries will only lift the relevant time partitions from the disk rather than lifting the entire dataset. Partitioning also allows having multiple tiers of storage, where older partitions can be mounted into cold storage, which is cheaper and slower.
- Downsampling and interpolation
Representing the data with a lower frequency. For example, shifting from a daily view to a monthly view. In order to facilitate such queries with SQL and make them less verbose, QuestDB built a native extension to ANSI SQL with the keyword SAMPLE BY. This SQL statement slices the dataset by a time interval (15 minutes in our example below) and runs aggregations for that time period. We can optionally fill values for those periods for which we have no results (interpolation, fill with null, default, etc.)

- Interval search
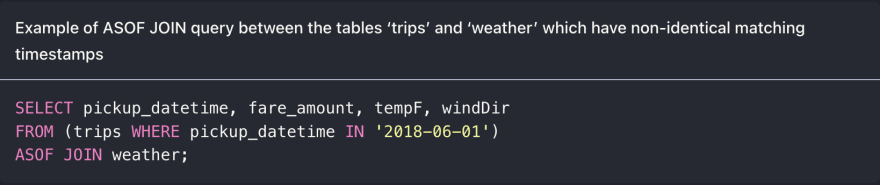
Fast retrieving data over arbitrary intervals. For example, zooming into a specific timeframe preceding a monitoring alert to better understand the underlying cause in real-time. QuestDB’s WHERE filter and IN time modifier for timestamp search is fast and efficient. The SQL query below retrieves all the data points in June 2018 for the column pickup_datetime:

- Time series joins
Align join time-series data from two different tables, which do not have exactly matching timestamps. These are known as ASOF joins, which we have elaborated in the ASOF JOIN section in our documentation. Below, the two tables, trips and weather, each show values for given timestamps. However, the timestamps for each table are not equal. For each timestamp in trips, ASOF finds the nearest timestamp in weather and shows the associated weather value in the result table:
- Most recent first
With time-series data, the most recent data is often more likely to be analyzed. QuestDB’s SQL language extension includes LATEST ON to get the most recent view of a record instantly. As data is ingested in chronological order, QuestDB starts scanning from the bottom and can thus retrieve the data point fast.

- Streaming ingestion protocols
As time-series data is mostly machine data, it is produced and streamed to a database in a continuous fashion. The ability to sustain streamed data rather than in slow batches quickly becomes a must. The InfluxDB line protocol is very efficient and offers a lot of flexibility. For example, you can create new columns on the fly without specifying a schema ahead of time.
Why we set out to build QuestDB
Democratizing time-series data performance
Our CTO worked in electronic trading and had built trading infrastructure for more than 10 years. In 2013, his boss would not allow him to use the only high-performance database suited to deal with time-series data because of its proprietary nature and price.
QuestDB was built with the intention to democratize the performance that was only available for high-end enterprise applications and make the tooling available for every developer around the world leveraging an open-source distribution model. Instead of writing a new querying language from scratch, our CTO decided to facilitate developer adoption via SQL rather than a complex proprietary language.
And this was the origin of QuestDB.
We have heard a large number of companies complaining about the performance limitations of open-source time-series databases. Most of those reuse existing libraries or are an extension of a well-known database that was not designed to process time-series data efficiently in the first place.
Instead, we chose an alternative route, one that took more than 7 years of R&D. Our vision from day 1 was to challenge the norm and build software that uses new approaches and leverages the techniques learned in low-latency trading floors. An important aspect was to study and understand the evolution of hardware to build database software that could extract more performance from CPUs, memory, and modern hard disks.
QuestDB design and performance
QuestDB is built-in zero-GC Java and C++, and every single algorithm in the code base has been written from scratch with the goal of maximizing performance.
QuestDB’s data model (time-based arrays) differs from the LSM-tree or B-tree based storage engines found in InfluxDB or TimescaleDB. It reduces overhead and data duplication while maintaining immediate consistency and persisting data on disk.
This linear data model structure massively optimizes ingestion as it allows the database to slice data extremely efficiently in small chunks and process it all in parallel. QuestDB also saturates the network cards to process messages from several senders in parallel. Our ingestion is append-only, with constant complexity, i.e. O(1); QuestDB does not rely on computationally intense indices to reorder data as it hits the database. Out-of-order ingests are dealt with and re-ordered in memory before being persisted to disk.
QuestDB’s data layout enables CPUs to access data faster. With respect to queries, our codebase leverages modern CPU architecture with SIMD instructions to enable the same operation to be performed on multiple data elements in parallel. We store data in columns and partition it by time in order to lift the minimal amount of data from the disk for a given query.
We didn't get everything right from the start! In 2021, we shipped QuestDB 6.0 to support high performance out-of-order data. A few months ago, we shipped dynamic commits to optimize ingestion throughput and data freshness for reads. We also rewrote our ingestion layer to make it more performant — taking advantage of the latest OS kernel innovations — and released official clients in seven programming languages to improve the developer experience. We are in the middle of decoupling data ingestion from table writers to eliminate table locks when using the Postgres wire protocol. We already have some ideas to make downsampling and aggregation queries even faster.
Additional resources on time-series data and databases
To learn more about time-series data:
Best Time Series Databases
DB-Engines Ranking of Time Series DBMS
Code to the Moon featuring QuestDB
Amazon Timestream - Time series is the new black
Time series on Wikipedia
To learn more about relevant projects:
Visualizing the stock market structure
Prophet: forecasting at scale
A Guide to Time Series Forecasting in Python
The original post was published on QuestDB's blog

Top comments (0)