
Introduction
Before diving deep into the actual topic, it's really important to make yourself familiar with the below terminologies.
What is a Processor ?
A core or processor is a complex logic in the CPU which can execute a set of instructions known as a program. A Processor is a hardware entity that runs the actual Process.
What is a Process ?
In reality we won't be running our programs directly on the CPU core. This responsibility is handed over to the Operating system. Operating system writes your program instructions to the core or processor through something called Process.
A Process is a logical instance of your program which is managed by the operating system. There will be thousands of processes scheduled by the Operating system based on the priority of the program. Irrespective of the core or processor count an Operating system can have an arbitrary number of logical processes but only one process instruction gets executed per processor at any point of time.
What is a Thread ?
A thread is a path of execution within a process. A process can contain multiple threads. All programs have at least one thread that gets created when the program is started, but a program can start more threads to perform work in parallel.
What is Concurrency ?
Concurrency is a way to handle multiple tasks at once by efficiently utilizing the available resources. Even though it deals with multiple tasks simultaneously, it could only execute one non-blocking task(execution state) at any point of time. The remaining tasks either be in a blocked state, yet to start, completed, hold or any other states.
As you can see in the below snapshot it looks like we are executing multiple tasks simultaneously, but the truth is we are deprioritizing the tasks by wait time or blocked state. So that program could perform other important tasks during the same time and come back to the place where it left once it got the response. This is known as Concurrency.
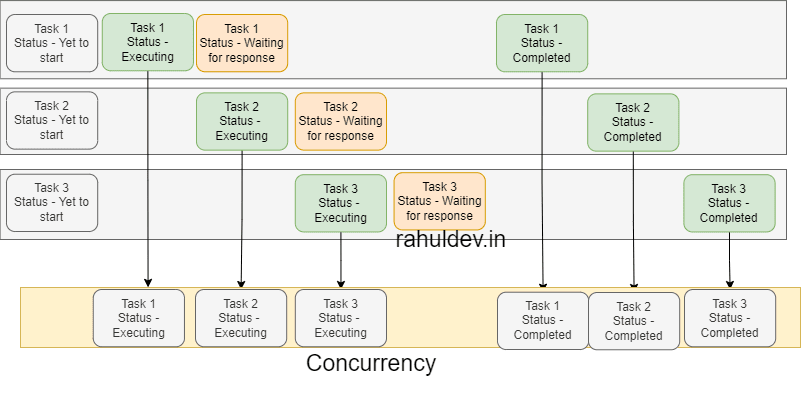
Assume that you have created a program in any of your favorite programming languages that supports concurrency. As well as this program has 3 arbitrary tasks. Initially all the tasks are in default state(yet to start).
Assume that all the 3 tasks have some preprocessing and network calls involved in it, So it takes arbitrary time to get the response from the external systems.
Once you run the program, you will see that task 1 is in execution state since it has some preprocessing involved. We also know that it has network calls involved so it's waiting(blocked state) for the response from external systems. Mean time task 2 starts executing its preprocessing layer and enters into the waiting state again due to network calls. Now there are 2 tasks in the blocked state so your program starts executing task 3 and it's preprocessing layers. Now even task 3 enters into a blocked state. Once any of the previous blocked states got the response then its respective task got completed.
For some reason if 2 or more tasks in a blocked state get the response at the same time, then your program picks the task randomly and fulfills it one after another.
What is Parallelism ?
Parallelism is all about executing multiple jobs independently in parallel at the same given time. Unlike concurrency it doesn't care about the task status, So it executes all tasks at once in parallel. To perform these independent actions it consumes additional resources.
As you can see in the below snapshot all the 3 tasks started it's execution, waited and finished respective tasks at the same time. But overall speed wise it took less time compared to concurrency. In Terms of resource usage it still has a bandwidth to accommodate other tasks while all the tasks have been in idle state. With parallelism we were able to get things done faster, but weren't able to utilize the resources better.
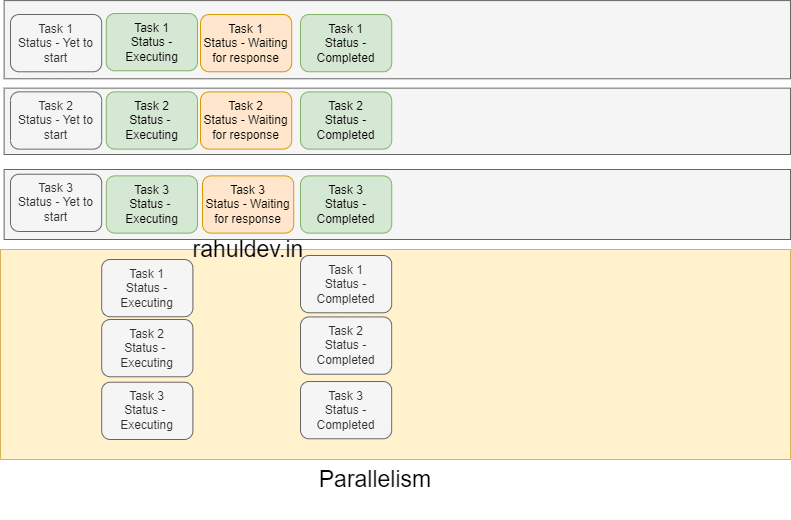
If you have a system with multiple cores, then you could definitely take advantage of Parallelism.
What is Goroutine ?
A goroutine is a lightweight thread managed by the Go runtime. A thread could have thousands of goroutines due to its less compute intensiveness. The main difference between goroutine and thread is Goroutine does not have a Local Storage as a result goroutines are cheaper to implement than threads, so goroutines are much faster in terms of boot time.
If you're new to goroutines then click here for deeper understanding
Implement Parallelism in Go
Refer to the code snippet below.
It has a variable named threadProfile which will be used for tracking the number of threads being created at runtime. Here in Go, threads are the way to implement parallelism.
runtime.GOMAXPROCS(runtime.NumCPU()) is used to set the number of cores your application can use. If you don't set this variable by default it uses all the available cores. Usually it's defined in init method.
runtime.LockOSThread() will call this function to prevent goroutines from reusing the existing threads by locking and unlocking the thread. It's a trick to see parallelism in action, because Go scheduler by default reuses the threads in non-blocked state.
We have added log statements to see the count of threads before and after executions.
You can execute the above snippet using the go run parallelism.go command. You will get the similar output as below.

For the count := 10 we can see that approximately 10 new threads are being created. It clearly shows that this program is executed in parallel by locking the threads. We locked the threads to force this to happen for demo purposes.
Implement Concurrency in Go
Refer to the code snippet below.
It has almost similar variables and functions as defined above. Only major change is that we removed the lock methods, because we want to see the default behavior of goroutines.
You can execute the above snippet using the go run concurrency.go command. If you get the similar output as below then you have successfully executed the program in concurrency mode. From the output you can understand that even for count:=10 all the 10 goroutines are accommodated in the same number of available threads without even creating a new thread.

Now you have seen concurrency in action, but do you know Go automatically creates the required number of threads dynamically ?.
Let's see both concurrency and parallelism in action by updating count:=1000(1000 goroutines). You will get the similar output as below.

If you watch the output closely you will find a new thread being created based on the demand.
Summary
To get the best performance out of the box it's suggested to combine Concurrency and Parallelism in any language of your choice. In Go it's handled internally, but in other languages you need to explicitly define the details (node.js - clusters and async await , python - gunicorn and async await(FastAPI)).
If you love this article, then definitely you will also enjoy learning Advanced Singleton design pattern implementation in Go
Awesome 🔥, you have successfully completed this tutorial. I would 💝 to hear your feedback and comments on the great things you're gonna build with this. If you are struck somewhere feel free to comment. I am always available.
If you feel this article is helpful for others then please consider a like.
Please find the complete code at github

Top comments (0)