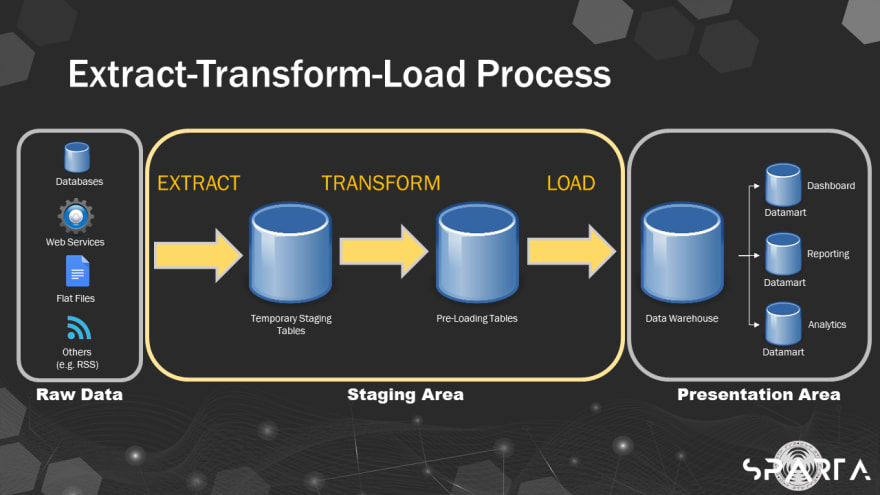
ETL Process (c) Project SPARTA
Extract-transform-load (ETL) is an essential part of Data Value Chain and has been the go-to data pipeline procedure when performing data warehousing due to its advantages such as ease in development and having a schema that matches what businesses need.
ETL basically combines data from multiple data sources into a single, consistent data storage that is loaded into a data warehouse or other target system.
To deliver business requirements accurately through a successful ETL, there are few considerations needed to keep in mind.
What-When-How
Organizations deal with huge amount of data everyday and finding out what exact data is needed is vital in performing extraction and transformation.
Which data is important and will finally end up in the data warehouse?
It's important to know what is needed and what will be needed in the future according to the business requirement. This is to save memory (by also avoiding noise data) and to improve computing performance.
Knowing also when to extract is a key factor. When performing ETL, it should not affect the production environment. Avoid extracting during peak hours as it may slow down the system in the production, affecting user experience, and worst, may cause data loss. Instead, performing batch extraction after office hours is more advisable.
Lastly, an important rule in ETL is to not tap the production database. One must create an indirect route to the source (eg. extracting from dump files created from IT batch run). Also, identifying how to extract involves consultations. This includes reviewing data governance and privacy policies of the organization.
Data Dictionary & Mapping
It is not uncommon to work with a vast number of data just to answer a single business requirement. However, problems may arise if attributes have inconsistencies and the data is not prepared well.
A data dictionary is a centralized repository of metadata and metadata is data about data, as defined by Kelly Bourne in his book "Application Administrators Handbook." It includes data elements with detailed description of its format and relationships.
Keeping a data dictionary that contains a list of fields and definitions of a schema helps not to get lost when working with potentially hundreds of fields with conflicting, ambiguous, and sometimes, analogous names. When working with relational databases with multiple related tables, mapping out and documenting the attributes helps not to get confused.
Business Rules
According to Michael Eisner in his article on ProcessMaker, business rules are directives that define activities and help provide guidelines to organizations. They bring forth efficiency, consistency, predictability, and many other benefits
Knowing business rules especially in transformation phase helps identify which is which and what to do according to the limitations set in the database, since these rules impose some form of constraint on a specific aspect of the database, such as the elements within a field specification for a particular field or the characteristics of a given relationship.
These are some of my notes in Week 1 of Project SPARTA's SP701 "SQL for Data Engineering" course.

Top comments (0)