
This article is derived from the Distributed Data Systems Masterclass event that I had fun doing with Maheedhar Gunturu from AWS and Tim Spann from StreamNative.
Find more about the event here.
What's event streaming
Events are facts or things that happen. In microservices architectures, we can imagine an event affecting a number of services and generating a series of interactions. The continuous flow of events and data is called a stream.
A streaming platform brings these tools together with the purpose of turning data at rest into data that flows through an organization - Ben Stopford, Designing Event-Driven Systems
Streaming platforms such as Apache Kafka and Apache Pulsar manage data streams to transfer them to the right data system or service. Steaming platforms transmit data created by a producer to a consumer, or import data from a data source to export it to another.
This is convenient for use cases such as data migration, real-time analytics or the use of a queriable database.

In this article, we will see how to use a simple producer service in Python to produce messages to a topic in Apache Pulsar. We will use ScyllaDB and create a Sink connector to export the messages to the database.
ScyllaDB and Pulsar for low latency applications
The reason we're using ScyllaDB and Apache Pulsar is to pair to distributed data systems that offer low-latency and high throughput.
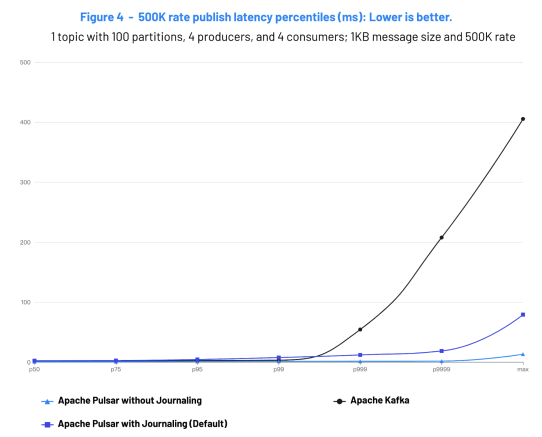
The figure below is extracted from the Kafka vs Pulsar 2022 benchmark and illustrates that at P99 Apache Pulsar operates at a few milliseconds. ScyllaDB is a distributed NoSQL database that uses the Seastar framework to consistently operate at low latency and can handle millions of operations per second.
Built-in Connectors
We explained above that event streaming platforms such as Pulsar and Kafka move data from one place to another. The systems used to import data to the streaming platform are called Sources, and similarly, the systems that the streaming platforms export data to are called Sinks.
As a developer, you could build your own connector if necessary. However, if you don't want to make your own connector and avoid maintaining additional code, Pulsar has out-of-the-box support for many of the most widely used data systems such as PostgreSQL, Kafka, Kinesis, Redis, and so on.
In our example below, we will use the Apache Cassandra Sink connector to pair ScyllaDB and Pulsar.

Pairing ScyllaDB to Pulsar
In this example, we will use the built-in Cassandra Sink connector. Note that ScyllaDB is API compatible with Apache Cassandra. However, unlike the Kafka Connector for ScyllaDB, the Cassandra connector is not shard-aware.
More about the shard-per-core architecture here.
Let's now pair ScyllaDB to Pulsar using the Apache Cassandra Sink connector. We will do that in three steps.
Step 1: Prepare the database
Run the below command to create a local ScyllaDB cluster using Docker:
docker run --name scylla -d scylladb/scylla
Note here that for this example we are creating a one-node cluster. ScyllaDB is a distributed database, and therefore it's recommend that you create at least three nodes for high availability.
The docker run command starts a new Docker instance in the background named scylla that runs the ScyllaDB server.
Run the following command to make sure the cluster is properly running:
docker exec -it scylla nodetool status
Expected output:
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.17.0.2 103.67 KiB 256 100.0% af0e4b2f-84e0-4f0b-bb14-bd5f9070ff26 rack1
Once the cluster running, we'll connect to the database using CQLSH to create a keyspace and a table.
docker exec -it scylla cqlsh
Use the following command to create a keyspace:
CREATE KEYSPACE pulsar_keyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor':1};
Let's use the pulsar_keyspaceand create a table pulsar_table:
CREATE TABLE pulsar_table (key text PRIMARY KEY, col text);
The pulsar_table is pretty simple. It has a key and a col both of type text.
Complete Scylla University for more about ScyllaDB.
Step2: Create a Sink Connector
In this step, we will create a Pulsar instance using Docker and configure the Sink Connector.
Execute the below command to run Pulsar using Docker:
docker run -it \
-p 6650:6650 \
-p 8080:8080 \
--mount source=pulsardata,target=/pulsar/data \
--mount source=pulsarconf,target=/pulsar/conf \
apachepulsar/pulsar:2.7.0 \
bin/pulsar standalone
Run the below command to list the running containers:
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3b027303f6e6 apachepulsar/pulsar:2.7.0 "bin/pulsar standalo…" 11 minutes ago Up 11 minutes 0.0.0.0:6650->6650/tcp, 0.0.0.0:8080->8080/tcp gallant_mahavira
Let's connect to the Pulsar instance using the following command:
docker exec -it <container id> /bin/bash
First, we will need to create the configuration file:
"configs" :
{
"roots": "localhost:9042",
"keyspace": "pulsar_keyspace",
"columnFamily": "pulsar_table",
"keyname": "key",
"columnName": "col"
}
I will be using JSON in this example, but you can also use YAML if you prefer.
configs:
roots: "localhost:9042"
keyspace: "pulsar_keyspace"
columnFamily: "pulsar_table"
keyname: "key"
columnName: "col"
Let's create the JSON file:
touch scylla-sink.json
json="{"configs":{"roots":"localhost:9042","keyspace":"pulsar_keyspace","columnFamily":"pulsar_table","keyname":"key","columnName":"col"}}"
echo $json > scylla-sink.json
Run the following command to create the Sink:
bin/pulsar-admin sinks create \
- tenant public \
- namespace default \
- name scylla-sink \
- sink-type cassandra \
- sink-config-file scylla-sink.yml \
- inputs test_scylla
The above command creates a sink connector that will write all messages to the test_scylla topic to the ScyllaDB cluster we previously created. Note that we are setting the sink-type to cassandra.
Step3: Test with Python
In the code below in the producer.pyfile, we connect to the Pulsar instance using the Client class. We then create a producer for the test_scylla topic and sends 10 messages on that topic:
import pulsar
client = pulsar.Client("pulsar://localhost:6650")
producer = client.create_producer(
"persistent://public/default/test_scylla"
)
for i in range(10):
producer.send(
('Hello-%d' % i).encode('utf-8'),
properties=None,
partition_key="my-key-{}".format(i)
)
client.close()
You can execute the above code using the following command:
python3 producer.py
Let's now have a look at the database:
docker exec -it scylla cqlsh
select * from pulsar_keyspace.pulsar_table;
Expected result:
key | col
---------+---------
my-key-7 | Hello-7
my-key-2 | Hello-2
my-key-8 | Hello-8
my-key-0 | Hello-0
my-key-3 | Hello-3
my-key-1 | Hello-1
my-key-5 | Hello-5
my-key-6 | Hello-6
my-key-4 | Hello-4
my-key-9 | Hello-9
Conclusion
ScyllaDB and Apache Pulsar are distributed data systems that operate at low latency. The example above shows how to use the Cassandra built-in connector for Pulsar to pair it with ScyllaDB as a Sink.
Unlike the ScyllaDB connector for Kafka, the Cassandra built-in connector is not shard-aware. Although the connector is compatible with ScyllaDB, it isn't optimized to efficiently run with ScyllaDB yet.
To be continued …

Top comments (0)