Introduction
First of all, I would like to state that I am not an Oracle DB expert. I am just a regular full-stack developer, that knows his way around in the DB world and can make things work. I've been involved in several projects that were using Oracle DB and I can honestly say that every one of them could've survive on any other open-source DB engine. Every time, it's usage was unjustified and statements like "it's been there forever" and "it is hard to move away from it" just underlined the impossibility of replacement.
Nevertheless, I had to use it, and most of the time it was more of a fight. Things that were essential in every other engine were a nightmare to configure (the simplest ones). If something usable was included, you had to pay extra for it (like the absence of partitioning in the standard edition). Anyway, Oracle DB is still the synonym for "enterprise-ready database solution" so Oracle marketing team is doing their job well!
Database-centric messaging model
The (simplified version of) application that underwent transformation to Kafka can be described with producer/consumer model.

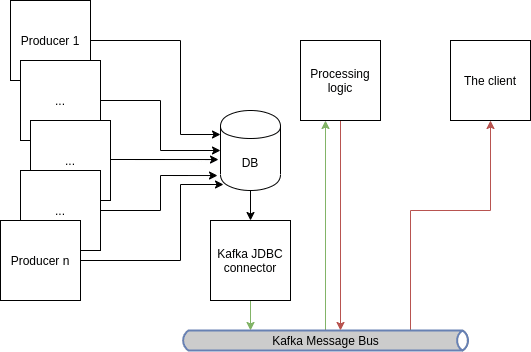
Simply put: There are 1 .. n producers and 1 consumer. The producers are writing data in the database tables, which have ON UPDATE triggers to send information to Oracle Pipe (DBMS_PIPE package). The client then reads information from the pipe and processes it.
Oracle Pipes are low-level mechanism to communicate between two (or more) sessions in similar scenarios as above. They work similarly as UNIX pipes, with all of their limitations, and are actually quite fast. This solution has one very important problem - it does not scale. Imagine that there will be 1 .. gazillion producers, you can probably add some extra power and RAM, but you still have a single bottleneck to maintain - database.
Enter Kafka
Apache Kafka needs no introduction, since it already has a steady place in a world of high-load/high-availability solutions. It is a streaming platform that enables you to build scalable distributed applications with not much effort. If you don't have experience with Kafka, this post is everything you need to know to understand it.
Kafka somehow fits naturally into our use-case. There already are producers and consumers, so we could just take them, wire it all together using Kafka and skip the DB part! In simple world, yes, that would be the case. But our application has important business logic related to calculation and messaging melted in the database, remember?
Until we are in an ideal world, where database is purely a storage facility, Kafka has a tool that could help us to transition to pure producer-consumer Kafka solution.
Kafka JDBC Source Connector
Using kafka-connect API, we can create a (source) connector for the database, that would read the changes in tables that were previously processed in database triggers and PL/SQL procedures. These changes would then be sent to intermediate component, that would do the computation itself.
You can use either JDBC-based or log-based solution, but since the latter one would cost more money (licenses for tools like Oracle GoldenGate or XStream), we will use JDBC-based one. Setting up JDBC source connector is relatively easy, here's a good article that describes it in a succint way. If you don't want to read the article, here's what it does:
- Polls specific table (either based on query or just the table name)
- When change is made, it's JSON representation is sent to Kafka
There are certain caveats and limitations which I will list for future reference:
- you can specific the mode in which the updates will be checked. I've used
timestamp, which is using comparison of timestamp column values. In order to set this up, timestamp column must be:- present in the table (duh)
- not null (nullability can be enabled, but what's the point of having that?)
- updated on each change either in the application or in the database trigger (since Oracle does not natively support
ON UPDATE TIMESTAMP) - using correct timezone (which can be configured in the connector settings)
- JDBC connector will use polling, so polling timeout must be fine-tuned in a way that it does not swamp the database. Also, the query used to fetch data must be executed fast.
- Database triggers have the ability to compare old and new date (e.g. before and after update). This would not be possible with JDBC connector, so you need to keep this in mind.
- You would probably also need to format the result in the query, for instance
number(*)(unbounded numeric type) will be transformed to a byte array. It can be easily solved by casting it specific value, e.g.number(12).
What's really great about this solution is how easily it scales up. The processing logic module can be spun up several times within the same Kafka group, which means the load will be distributed amongst consumers "the Kafka way". This would practically off-load the pressure on the database and enable us to scale up the processing part.

The implementation of processing logic can be done using kafka-streams or Kafka's Producer/Consumer API, depending on the nature of transformations. I haven't exposed too many details, which was on purpose, so if you have more questions feel free to leave a comment and contact me!

Top comments (0)