
If you don’t know how cool Serverless is, take a look at this article and then this post. AWS is clearly the most popular Serverless implementation so it will be the focus here. To be honest, serverless isn’t exactly void of a server since code must run on something, but not having to deal with the common issues of code deployment/execution is a good thing to at least consider.
On to CRUD, which is short for Create/Read/Update/Delete. Let’s consider the fundamental intra-operations related to each business entity, and the inter-operations for relationships between entities. Doing the latter increases complexity but these relationships are too important to ignore.
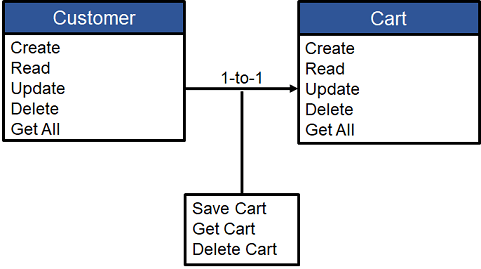
Using the example in the figure above, let’s do a little math to determine how many discrete functions are needed. I count thirteen (13). Now let’s be clear, creating a function in a Java class (for example) is, for the most part, less time consuming than creating a corresponding function as an AWS Lambda function. Let’s assume the difference is minimal, but as the # of functions increases, so will time time along with the difficulty in debugging and monitoring. Checkout dashbird for help in this area
Let’s now grow the domain model a bit so we can continue to better size up the energy involved to create discrete functions for each CRUD operation.
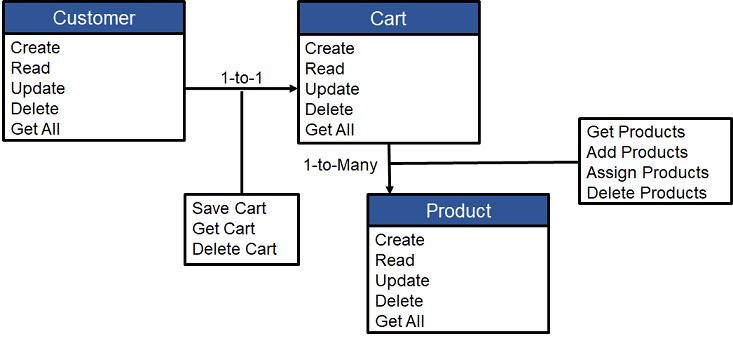
With this small change to the domain model, we can now create a table and equation to better estimate the total number of required discrete CRUD functions.

Imagine if we expand our model to 10 business entities each having one (1) single association and one (1) multi association. We suddenly have 240 (100+60+80) CRUD functions in total.
Doesn’t sound like I am actually making much of a case for CRUD going Serverless but I am getting there. If what makes AWS Lambda valuable is still important to us, let’s assume no matter how many functions we have to write, the additional time to create and manage is near zero to negligible when compared to other development/deployment options.
Serverless and Relational DBs Can Be a Go!
CRUD is associated with persistence operations and these operations are primarily accomplished using either an RDBMS or NoSQL solution. An AWS Lambda function is not only a serverless function but it is a stateless function. This means each function knows nothing about the current state of anything dependent on it or anything it depends on. This is critical when it comes to persistence. If you have ever tried connecting to a database like MySQL, you know the first connection is often the slowest with subsequent connections performing acceptably. Unfortunately, since a serverless function is stateless, each call requiring a database connection is considered a cold call first connection and the performance is unbearable. There are some databases that play nice in a stateless scenario, but if you have already invested in a traditional RDBMS these won’t suffice. Fortunately, there are implementation strategies where the database persistence implementations are abstracted out of the serverless function itself, into a remotely accessed stateful RESTful API. The great part is that API can be accessed by other applications too.
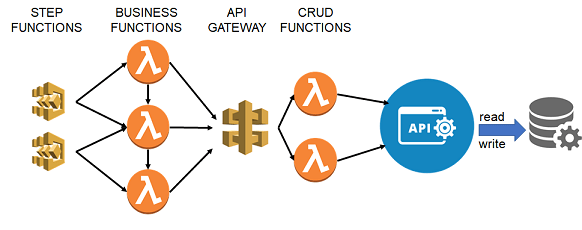
Serverless or otherwise, we more often than not need these CRUD functions. They form the core functionality of most modern application architectures, whether microservices, RESTful APIs, or monolithic.
Creating a Lambda Ecosystem is a Snap!
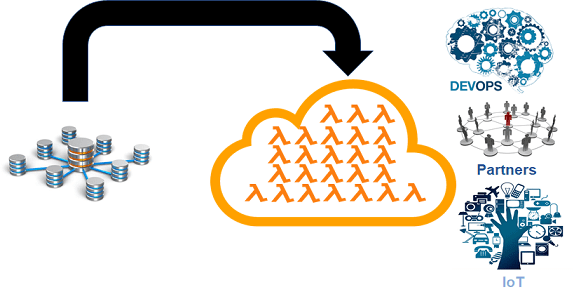
I used a domain model to help illustrate the relationship between entities, operations, and associations. The more complex the domain, the more complex the model and the more CRUD functions. I have worked on projects using UML with a class diagram having in excess of 100 business entities and more than 250 associations. Not visually appealing to look at but it helps to have a single picture to help grasp the scope of an effort. Another reason why I create a domain model is to help illustrate how the details of the model map nicely to what we need in terms of creating a corresponding Lambda function ecosystem. If the model is well defined and understood, and the mapping from the CRUD capabilities can be inferred simply from the model’s entities and associations, and it is understood how each CRUD capability is to be represented as a Lambda function, we have an opportunity to generate it all. No need to write the 100s Lambda functions when they can be quickly generated using a model as input. For this example, I used UML as input to represent a domain model, but I could have just as easily described the model in a JSON file or used database schema notation.
Application Function Refactoring
The latter point of database schema notation being another form of a domain model is very important. If we consider many legacy applications are built on an architecture where a relational database is used to persist data, the schema of that database gives us a very close to perfect representation of that application’s domain model. As stated, if that model can be used to apply as input to then create a corresponding set of Lambda functions, we can consider this a form of refactoring. It might be easier to consider this function refactoring as an easy first step in application refactoring than refactoring an entire application itself.
In Summary
Even though the number of CRUD functions can be large for even a small project, generating them as AWS Lambda functions simplifies things significantly. Feel free to browse this Bitbucket repository to review the output for a sample project generated for CircleCI using Terraform.

Top comments (0)