
Introduction
High level Brotli compression provides great compression rates, but incurs significant CPU overhead. As a result it's often not feasible to perform high quality Brotli compression for dynamic or even partially dynamic content, and servers compromise the compression rates in order to achieve on-the-fly compression speeds for those payloads.
This post describes a way to improve the Brotli encoder such that on-the-fly compression speeds and high compression rates are both possible for compression payloads with high similarity to previously compressed content.
There are many cases where we'd want to compress dynamic resources that are very similar to static ones we compressed before. In these cases it can be useful to use some information from the past compression.
Brotli has different types of artifacts that it calculates during compression which are stored in the compressed file, such as block splittings, block clusterization, backward references, entropy coding decisions, etc.
High quality Brotli compression (e.g. Brotli level 11) invests a lot of CPU time in finding those ideal artifacts for the file at hand.
Would it help if we’ve already compressed a similar file before and calculated all the artifacts needed?
Executive Summary
The approach explored in this post can benefit cases when we’re trying to compress dynamic content on-the-fly, where the content resembles content available to us ahead of time. Real life examples include delivery of JS bundles subsets (e.g. when parts of the code are already cached on the client), dynamic HTML based on known-in-advance templates, and subsetted WOFF2 fonts.
With this approach we’ve seen 5.3% better compression rates and 39% faster compression speeds when removing 10% of the content, and 3.2% better compression rates and 26% faster compression, when removing 50% of the content.
Read on to see how this was achieved, or skip to the full results below.
Motivation
Currently, high-quality Brotli compression of dynamic content is simply not feasible - compressing the content takes too long (on the order of seconds), and the benefits of compression cannot compensate for that.
At the same time, there are many scenarios where dynamic content is a variation of previously-known static content:
- When serving concatenated JS bundles, the exact composition of the bundle is not always known ahead of time (e.g. due to client-side caching of some chunks). But, all potential bundles can be expressed as a subset of a single superset concatenation of all possible chunks, which is known at build time.
- When serving dynamic HTML content, some of the content may be dynamic (generated on-the-fly, using data typically coming from a database), but large parts of the content are static and dictated by the template. That results in a high degree of similarity between the dynamic content and the original static template.
- When dynamically subsetting WOFF2 based fonts, one could reuse the full font’s compression information in order to achieve high compression speeds without compromising on compression rates. This is possible because the WOFF2 format itself uses Brotli compression.
Background
In this section we’ll describe some basics of Brotli that are relevant to the task. Note that this is not a comprehensive guide to everything Brotli related. There are many other techniques and algorithms used inside Brotli which are out-of-scope for this post.
Brotli calculates different types of artifacts and stores them in the compressed file. Below are the types which we will work with:
1. Backward references
Backward references enable the compression engine to describe a portion of text that was already previously encountered, and that can replace the current part of the text.
A backward reference is described as <copy_length, distance>. There are 2 types of references: a usual backward reference (which is referring to a previously encountered string in the resource itself) and a reference to Brotli’s static dictionary.
Usual backward reference:
Backward reference found at position pos of initial text means that
text[pos : pos + copy_length] = text[pos - distance : pos - distance + copy_length].
So there is no need to save string text[pos : pos + copy_length] in a compressed file but just store backward reference <copy_length, distance> on that position. This reference will point to the part of the text with the same substring.
Reference to the static dictionary:
The idea behind dictionary references is the same as before: standing at position pos find an equal substring. However, instead of pointing to some substring encountered previously in the text, this reference will point to a static dictionary.
A static dictionary is a fixed-in-advance text of the most popular words and is the same for all files. The structure of such a reference is the same <copy_length, distance> where distance describes the offset in the dictionary (need to apply some transformations to distance to get it). To distinguish between these two types of references, dictionary references have a distance that is greater than the maximum possible backward distance for the current position.
Example:
For the text 2foobarchromefoobarapplearch one can find 2 references:
2foobarchromefoobarapplearch
2foobarchromefoobarapplearch
Those references are
- <6, 12> for foobar substring (copy_length=6, distance=12)
- <4, 19> for arch substring (copy_length=4, distance=19)
So we can replace the text by 2foobarchrome<6, 12>apple<4, 19>.
During compression, Brotli finds those equal substrings and stores backward references in the compressed file. During decompression, the engine takes those references and reverts them back to the substring they represent.
The different levels of Brotli have different reference search algorithms, which become more complex and slow as quality level increases.
2. Block splitting
Brotli splits initial text to blocks. These blocks don’t impact backward reference search, but they do impact the Huffman encoding which is later applied to the data.
For each block, Brotli picks a different set of Huffman trees that it applies to symbols inside the block, in order to further compress it. The better block splitting is, the better compression Huffman encoding achieves.
There are 3 types of block splits:
- Block splits for literals
- Block splits for insert and copy lengths
- Block splits for distances
These 3 types are independent of each other.
Block splitting becomes more complex as the quality level grows. Low-quality levels split text to blocks of fixed predefined size sometimes merging close blocks if needed while higher-quality levels try to find homogeneous parts of the text and define them as blocks, as they have similar character distribution statistics, leading to more efficient encoding.
Design
So, we talked about why we want to use past compression artifacts and what artifacts we can use. Now, let’s dive into the gritty details of how we can use them.
Let’s say we have 2 similar files: A and B.
Here we will focus on the case where B was obtained by deleting a text range from file A but this approach could be quite easily generalized for other relationships between A and B.
Assume that we’ve already compressed file A. Would the information from this compression help to compress file B? Turns out it would!
Looking at the backward references for file A, most of them could be reused in file B’s compression.
Ignoring edge cases, there are 3 high-level cases here for a backward reference:
- Reference position and referenced text are both before or after the removed range - in this case, we can just copy it as is.
- Reference position or referenced text are in the removed range - meaning we can ignore that reference.
- Reference position is after the removed range and the referenced text is before it - We need to adjust the reference distance.
We can use a similar approach for block splitting.
General approach
We used the following steps to prototype the reuse of compression artifacts:
- Get high-quality Brotli compressed file A as input.
- Decompress A and save all the necessary information generated by its past compression.
- Delete certain chunks from file A to get file B.
- Change the information collected so it’s suitable for B.
- Using this information compress file B.
It’s worth noting that other than step (5), the above steps are all rather fast to execute.
Step (5) is more computationally intensive but should be fast enough as we use the information from A’s compression in order to avoid re-calculating it for B.
Note that step (3) above is suitable for our proof-of-concept project, but may not be suitable as a production-level API, where the decision which ranges to remove from A needs to be given as input.
Backward references
In Brotli, the backward reference search looks for substring matches for various positions in the file. As we want to reuse backward references, for each position at which Brotli tries to find a match, we will search the backward reference array for past-references that are located at the exact position we’re searching at. If we have found such a reference, we will take it as a match, otherwise we will find a match using the original Brotli match search. For such matches, we would need to cut their copy_length to prevent them intersecting with any other references we want to reuse (as we don’t search for matches at positions that are already covered by previous backward references).
Block splitting
Instead of searching for new block splits we will use the stored ones. However, before taking them as final block splitting we need to check and adjust block lengths as block splitting could be a bit different depending on a backward reference set.
Making high quality block splitting faster
The combination of reusing backward references and block splits with a high quality block splitting algorithm (used by Brotli 10 and 11) gives significant compression rate benefits for all the Brotli levels from 5 to 9. However, high quality block splitting also makes compression about 4 times slower.
As we want an on-the-fly compression, we are ready to sacrifice compression rates a bit in order to achieve significantly better speeds. Thus, we adjusted the high quality block splitting algorithm to reduce the computation time, while taking a small hit to compression rates compared to the original high-quality splitting algorithm.
Results
This section contains the results for the main experiments. The results are listed only for the 2 best options we achieved. If you are interested in other experiments here is a link.
Experiment details:
Experiments were conducted using a dataset of WebBundles generated from HTTP archive.
We are assuming that we have a Brotli-11 compressed bundle and want to get a compression of the original bundle with a deleted [a, b) fragment of different sizes.
We’ve compared 2 different approaches:
Usual approach:
Decompress Brotli-11 compressed bundle,
Delete [a, b) part from it,
Compress it again with some level of Brotli.Our approach:
Decompress Brotli-11 compressed bundle and save info needed,
Delete [a, b) part from it and adjust the information collected,
Compress it with some level of Brotli using this information.
The best results for our use-case were achieved with those two options:
- Brotli 5 with reuse of backward references and block splits for literals and commands with usual block splitting algorithm.
- Brotli 5 with reuse of backward references and block splits for literals and commands with optimized high quality block splitting algorithm.
Here are the results for various removal rates (10%, 30%, 50%, 70%, 90%).
- Rate - compression ratio
- Speed - compression speed in Mb/s (input_size / compression_time)
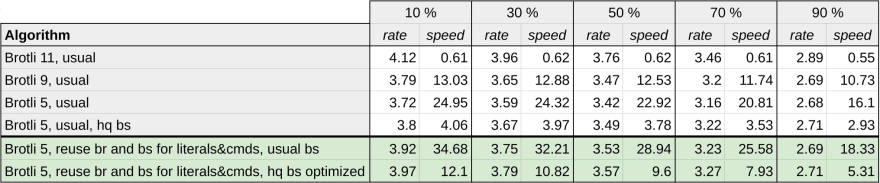
Abbreviations:
- hq bs optimized = block splitting search is performed by a high quality block splitting algorithm used by Brotli 10 and 11. Optimized means that some optimizations have been done to make it faster.
- usual bs = block splitting search is performed by the usual block splitting algorithm used by Brotli level 9 and below.
- br = backward references
- bs for literals&cmds = block splits for literals and insert and copy length
Conclusions:
- The use of backward references and block splits from a first compression greatly increases compression ratio. Moreover, the reuse of artifacts also speeds up the compression.
- Brotli 5 with reuse of backward references and block splits for literals and commands with usual block splitting algorithm enabled us to achieve:
For 10% removal:
5.3% better compression and 1.38 times faster than usual Brotli 5.For 50% removal:
3.2% better compression and 1.26 times faster than usual Brotli 5
- Brotli 5 with reuse of backward references and block splits for literals and commands with optimized high quality block splitting algorithm:
For 10% removal:
6.7% better compression and only 2 times slower than usual Broli 5.For 50% removal:
4.4% better compression and 2.38 times slower than usual Brotli 5.
- Adding hiqh quality block splitting makes compression 2.1% better for usual approach and 1.8% better for approach with reuse of artifacts. However, it’s about 3-5 times slower.
- Optimizations in high quality block splitting allows us to achieve 1.4-2 times faster compression with a drop in compression ratio of 0.25% for Brotli 9 and 0.4% for Brotli 5 which is acceptable.
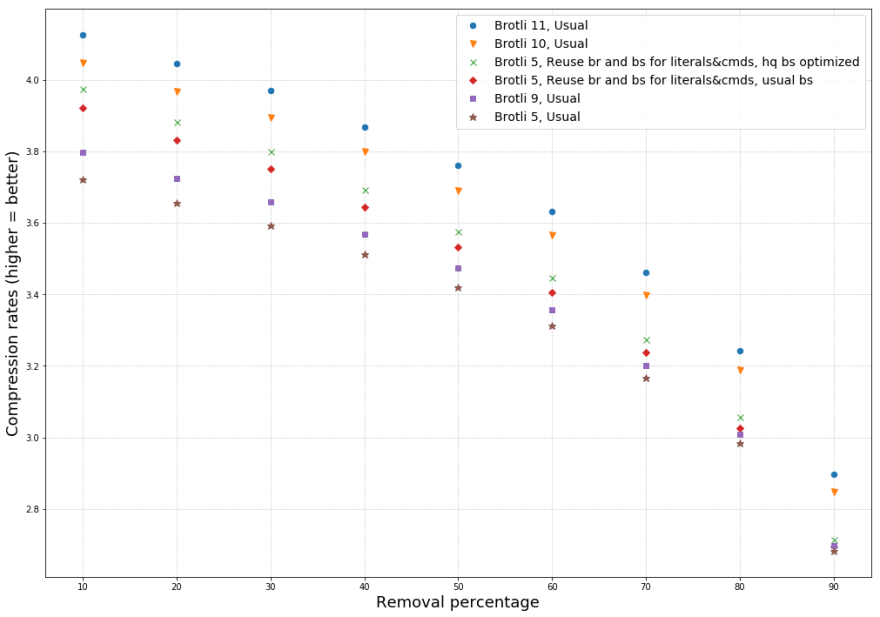
- As removal ratio increases, compression rate decreases for all the algorithms (including usual Brotli). This happens due to the decreasing size of files. However, deleting more content reduces the improvement we will get with our approach, since removing content means there are fewer backward references available for reuse.
To illustrate the above, here are plots for compression rates and compression speeds for the experiments described:

What’s next?
Productization
Note that the described work is only a prototype which needs to be productized and isn’t available in the main Brotli github repo yet. If you’re interested in looking at the prototype code or want to experiment with it, the code is on GitHub.
As part of the productization, we’d need to figure out the API and implement the same approach for insert transformations.
Future research
Similar research could be done for other types of artifacts, though it is less likely that these would produce the level of impact achieved by reusing backward references and block splitting.
As examples, we can collect entropy coding decisions during decoding which can be used in zopflification or histogram clustering to make them faster. Besides, for references to the static dictionary, we can additionally save a dictionary word during decompression, so there will be no need to calculate it in the encoder while checking a reference.
Finally, I want to thank the Chrome and Brotli compression teams and especially Yoav Weiss and Jyrki Alakuijala for such an amazing experience of working together 😃!

Top comments (0)