
One of the goals of a customer data platform is to make the movement of data from any source to any destination easy while guaranteeing correctness, reliability, efficiency, and observability. In that sense, reverse ETL is no different, it's just another data pipeline.
In 2019, RudderStack started as a data infrastructure tool supporting event streaming to multiple destinations, including the data warehouse. From the outset, we made the data warehouse (or data lake/lakehouse 🙂) a first class citizen, supplying automated pipelines that allow companies to centralize all of their customer data in the warehouse. It's important not to overlook the impact of this decision, because placing the storage layer at the center and making all the data accessible is key to unlocking a plethora of use cases. But getting the data into the warehouse is basically only useful for analytics. It's getting it back out that enables brand new use cases, and that's where Reverse ETL comes in.
What is Reverse ETL?
Reverse ETL is a new category enabling the automation of brand new business use cases on top of warehouse data by routing said data to cloud SaaS solutions, or operational systems, where sales, marketing, and customer success teams can activate it.
Building pipelines for Reverse ETL comes with a unique set of technical challenges, and that is what this blog is about. I'll detail our engineering journey, how we built RudderStack Reverse ETL, and how Rudderstack Core helped us solve more than half of the challenges we faced. In a way, building this felt like a natural progression for us to bring the modern data stack full circle.
What is RudderStack Core?
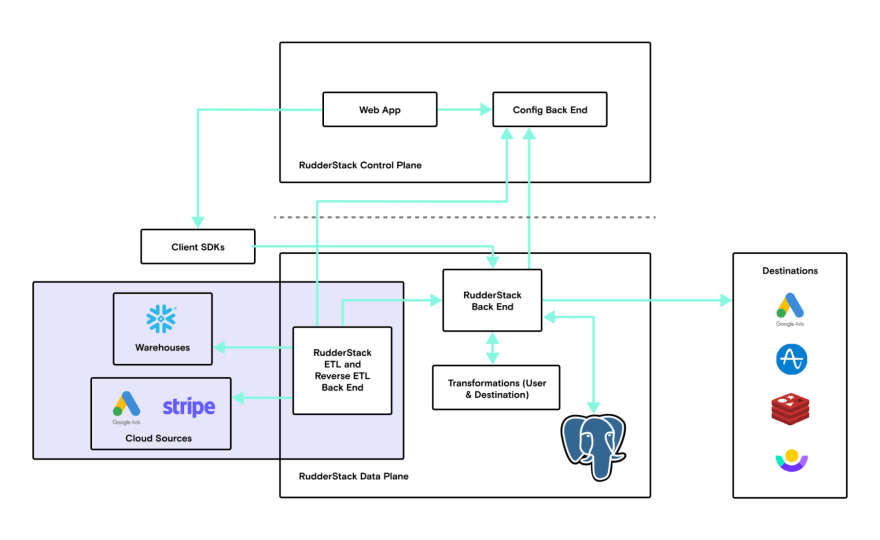
RudderStack Core is the engine that ingests, processes, and delivers data to downstream destinations. Main features:
- Ingest events at scale
- Handle back pressure when destinations are not reachable
- Run user defined JavaScript functions to modify events on the fly
- Generating reports on deliveries and failures
- Guarantees the ordering of events delivered is same as the order in which they are ingested
 \
\
The technical challenges we faced building Reverse ETL
First, I'll give an eagle eye view of the different stages to building Reverse ETL and the challenges associated with them. Along this stroll, I'll explain how RudderStack Core helped us launch it incrementally, making several big hurdles a piece of cake. I must give major kudos to our founding engineers who built this core in a "think big" way. Their foresight drastically reduced the amount of effort we had to put into designing and building engineering solutions for Reverse ETL.
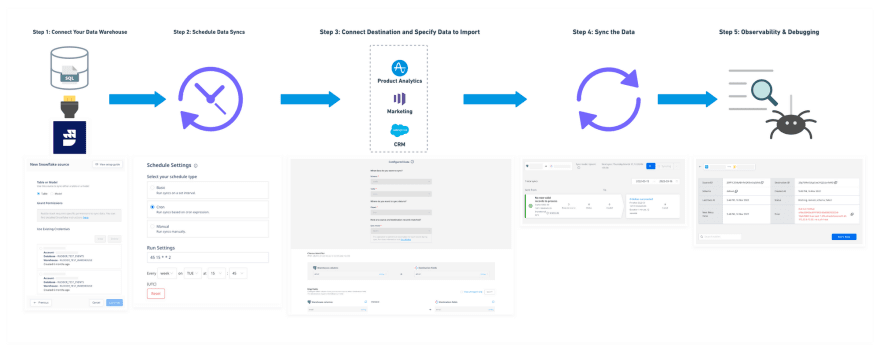
1. Creating a Reverse ETL pipeline
Out of all the steps, this was the easiest one, though it was still a bit tricky.
1.1 Creating a source
Warehouse source creation gets complicated because of credentials and because of the read and write permissions one needs to maintain transient tables for snapshots and evaluating diffs. It's important to ensure the user can easily provide only the necessary permissions for reverse ETL, so the pipeline tool does not end up with access to more tables in the customer's production than needed or with any unnecessary write access.
This is a tricky problem made harder by the differences between warehouses. We asked ourselves a few key questions when building this:
- How can we simplify and streamline the commands and accesses for different warehouses?
- How can we help one validate these credentials when creating a source?
In this instance, our control plane enabled us to reuse and build on existing components. This was crucial because we wanted to make validations in a generic way, so they would be reusable as we continue adding more data warehouse and data lake sources. Our team iterated a lot on how to educate users on which permissions are required and why. Check out our documentation on creating a new role and user in Snowflake for an example. We had to work to ensure only relevant validations and errors would show when setting up a source, and we came up with faster ways to run some validations.
As an example, in our first iteration we used Snowflake queries to verify whether the provided credential allowed us to validate the needed schema for RudderStack, so we could read, write, and manage transient tables to it. These queries were scheduled in the normal queue manner by Snowflake, but for some customers it took minutes for these queries to run. So, we found a better solution from Snowflake where SHOW commands do not require a running warehouse to execute. With this new solution, validations complete within a minute or less for all customers. As we built out the reverse ETL source creation flow, the big wins that we adopted from the existing RudderStack Core platform were:
- Our WebApp React components' modular designs were re-usable in the UI
- We were able to re-use code for managing credentials securely and propagate it to the Reverse ETL system in the data plane
- We were able to deliver faster because RudderStack Core allowed us to focus on the user experience and features vs. building infrastructure from the ground up
1.2 Creating a destination
Every data pipeline needs a source and a destination. When it came to creating destinations for Reverse ETL, RudderStack Core really shined. Enabling existing destination integrations from our Event Stream pipelines was straightforward. We built a simple JSON Mapper for translating table rows into payloads and were able to launch our Reverse ETL pipeline with over 100 destinations out of the box. Today the count is over 150 and growing! We're also incrementally adding these destinations to our Visual Data Mapper. For further reading, here's a blog on how we backfilled data into an analytics tool with Reverse ETL and some User Transformations magic.
2. Managing orchestration
The Orchestrator was critical and one of the more challenging systems to build, especially at the scale RudderStack is running. Reverse ETL works like any batch framework similar to ETL. If you're familiar with tools like Apache Airflow, Prefect, Dagster, or Temporal, you know what I'm talking about---the ability to schedule complex jobs across different servers or nodes using DAGs as a foundation.
Of course, you're probably wondering which framework we used to build out this orchestration layer. We did explore these options, but ultimately decided to build our own orchestrator from scratch for a few key reasons:
- We wanted a solution that would be easily deployed along with a rudder-server instance, in the same sense that rudder-server is easily deployed by open source customers.
- We wanted an orchestrator that could potentially depend on the same Postgres of a rudder-server instance for minimal installation and would be easy to deploy as a standalone service or as separate workers.
- We love Go! And we had fun tackling the challenge of building an orchestrator that suits us. In the long run, this will enable us to modify and iterate based on requirements.
- Building our own orchestrator makes local development, debuggability and testing much easier than using complex tools like Airflow.
- We love open source and would like to contribute a simplified version of RudderStack Orchestrator in the future.
3. Managing snapshots and diffing
Let's consider one simple mode of syncing data: upsert. This means running only updates or new inserts in every scheduled sync. There are two ways to do this:
- Marker column: In this method, you define a marker column like updated_at and use this in a query to find updates/inserts since the previous sync ran. There are multiple issues with this approach. First, you have to educate the user to build that column into every table. Second, many times it's difficult to maintain these marker columns in warehouses (for application databases, this is natural, and many times DBs provide this without any extra developer work).
- Primary key and diffing: In this method, you define a primary key column and have complex logic for diffing.
We went with the second option. One major reason was that we could run the solution on top of the customer's warehouse to avoid introducing another storage component into the system. Also, the compute power and fast query support in modern warehouses were perfect for solving this with queries and maintaining snapshots and diffs to create transient sync tables.
Hubspot table after incremental sync of new rows:

Sync screen in RudderStack:
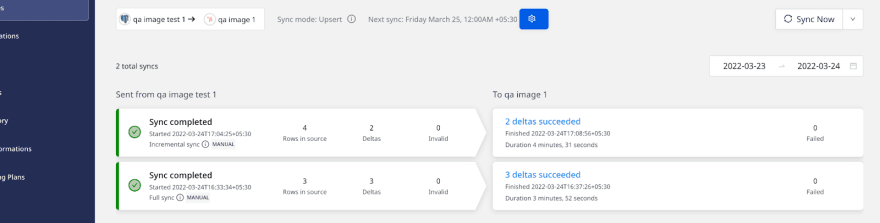
Snapshot table view:
 \
\
Now, you might be thinking: "What's the big deal? It's just creating some queries, running them and syncing data?" I wish, but it's not as simple as it looks. Also, this was one of the challenges RudderStack core couldn't help with. Here are a few of the challenges that emerge when you dig deeper into the problem:
- Diffing needs to be very extensible, not only for the multiple warehouse sources we already support, but also for integrating with future warehouse and data lake sources.
- You have to implement state machine based tasks to handle software or system crashes and any errors that occur across a multitude of dependencies.
- You have to maintain record ordering checkpoints during sync to ensure a higher guarantee of delivering exactly once to destinations.
- You have to support functionality for pausing and resuming syncs.
- You have to handle delivery of records that failed to deliver on the previous sync.
On top of those considerations, there were a number of other interesting problems we found related to memory, choice of CTE vs temporary table, columns data types, structs in BigQuery, and more, but that's another post for another day.
4. Managing syncing, transformations, and delivery to destinations
RudderStack Core significantly shortened the development cycle for syncing, running transformations in the data pipeline, and final delivery to destinations.
In large part, this is because our Reverse ETL and Event Stream pipelines have a lot in common relative to these use cases. In fact, from a source perspective, Reverse ETL pulling from warehouse tables is much simpler than SDK sources, so we were able to have more precise control over ingestion and leverage rudder-server for everything else. Here's what rudder-server took care of:
- Destination transformations (mapping payloads to destination API specs)
- Calling the right APIs for add, update, delete, and batch APIs if supported
- User transformations (custom JavaScript code written by users to modify payloads)
- Managing the rate limits of destination APIs (which vary significantly) and providing a back pressure mechanism for Reverse ETL
- Handling failed events with retries and providing finally failed events back to Reverse ETL
- A mechanism to identify completion of sync tasks
- New integrations and feature enhancements (automatically usable by our Reverse ETL pipeline when deployed to RudderStack Core)
Even though the items above were huge wins from RudderStack Core, there were some other interesting problems we had to solve because we use rudder-server as our engine to deliver events. I won't dive into those now, but here's a sample:
- It's challenging to deliver events to our multi-node rudder-server in a multi-tenant setup
- It's complicated to guarantee event ordering for destinations that require it
- We have to respect the rate limits of different destinations and use back pressure mechanisms, so we don't overwhelm rudder-server, all while maintaining fast sync times
- Acknowledging completion of a sync run with successful delivery of all records to destination
5. Maintaining pipelines with observability, debuggability, and alerting
Any automated data pipeline needs some level of observability, debugging, and alerting, so that data engineers can take action when there are problems and align with business users who are dependent on the data.
This is particularly challenging with systems like Reverse ETL. Here are the main challenges we had to solve:
- Long running processes must account for software crashes, deployments, upgrades, and resource throttling
- The system has dependencies on hundreds of destinations, and those destinations have API upgrades, downtime, configuration changes, etc.
- Because RudderStack doesn't store data, we have to create innovative ways to accomplish things like observability through things like live debuggers, in-process counts (like sending/succeeded/failures), and reasoning for any errors that are critical
Accounting for software crashes, deployments, upgrades, and resource throttling required a thoughtful design for Reverse ETL, here's how we did it:
- State machine: State based systems look simple but are incredibly powerful if designed well. Specifically, if an application crashes, it can resume correctly. Even failed states like failed snapshots can be handled properly by, say, ignoring it for the next snapshot run.
- Granular checkpoint: This helps make sure no duplicate events will be sent to destinations. For example, say we send events in a batch of 500 and then checkpoint. The only possibility would be that one entire batch might get sent again if the system restarted or if it happened during deployment as it was sent to rudder-server, but could not checkpoint. On top of this, rudder-server only has to maintain a minimal batch of data to add dedupe logic on top because it doesn't need to save an identifier for all records for a full sync task.
- Support for handling shutdown and resuming: Graceful shutdown handling is critical for any application, especially for long running stateful tasks. My colleague Leo wrote an amazing blog post about how we designed graceful shutdown in Go, which you should definitely read.
- Auto scale systems: Automatically scaling systems handle tasks that are running in a distributed system, which is necessary for handling scale, both for Reverse ETL side as well as the consumer (rudder-server). At any given time a Reverse ETL task might be running on a single node, but might have to be picked up by another node if the original node crashes for some reason. On the consumer side (rudder-server), data points might be sent to consumers running on multiple nodes. Guaranteeing lesser duplicates, in-progress successfully sent records, and acknowledging completion of sync tasks are really interesting problems at scale.
- Proper metrics and alerts: We added extensive metrics and various alerts, like time taken for each task, number of records processing from extraction to transformation to destination API calls, sync latencies for batches of records, and more.
- Central reporting on top of metrics: Beyond just metrics for Reverse ETL, there is a need for a central reporting system as multiple systems are involved in running the pipeline, from extraction to final destination. We wanted to capture details for all stages to ensure we had full auditability for every pipeline run.
Again, RudderStack Core was a huge help in shipping several of the above components of the system:
- Destinations: when it comes to integrations, maintenance is critical because things must be kept up to date. Many times things fail because of destination API upgrades or different rate limits, not to mention upkeep like adding additional support for new API versions, batch APIs, etc. Because destinations are a part of RudderStack Core, the Reverse ETL team doesn't have to maintain any destination functionality.
- Metrics: rudder-server already included metrics for things like successfully sent counts, failed counts with errors, and more, all of which we were able to use for our Reverse ETL pipelines.
- Live Debugger: Seeing events flow live is incredibly useful for debugging while sync is running, especially because we don't store data in RudderStack. We were able to use the existing Live Debugger infrastructure for Reverse ETL.
Concluding thoughts
Building out our Reverse ETL product was an amazing experience. While there were many fun challenges to solve, I have to reiterate my appreciation for the foresight of our founding engineers. As you can see, without RudderStack Core this would have been a much more challenging and time consuming project.
If you made it this far, thanks for reading, and if you love solving problems like the ones I covered here, come join our team! Check out our open positions here.

Top comments (0)