In the previous blog we started discussing about the join operations in PostgreSQL, join algorithms are essential for effectively merging data from many tables.
In this blog we will move further and discuss Merge Join and Hash Join which are two popular join algorithms. We will go further talk about their variations.
Merge Join:
This join algorithm is appropriate for equi-joins and natural joins. It makes effective use of the idea of sorting to integrate sorted data from two tables. Let's investigate its runtime variations and sequence.
Runtime Order:
The total sorting cost for the inner and outer tables make up the startup cost of a merge join. O(Outer * log2(Outer) + Inner * log2(Inner)) can be used to represent it. The amount of tuples in each table, Outer and Inner, determine the run cost, which is O(Outer + Inner).
Variations:
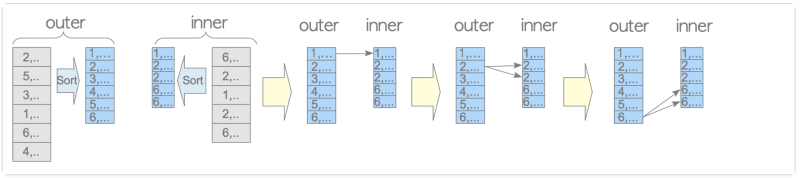
- Merge Join: This is the simplest type of Merge Join. To join the tuples based on the supplied join condition, it runs a merge operation on two sorted tables.
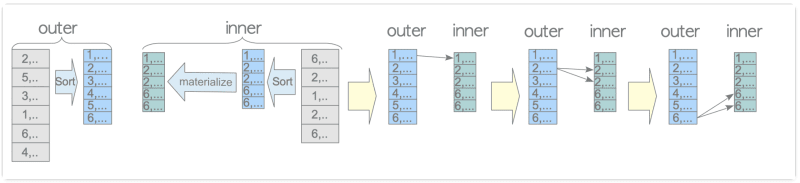
- Materialized Merge Join: In this kind, the inner table is materialized, which increases the effectiveness of inner table scanning. A merge join operation is carried out after the inner table has been sorted and materialized.
- Variations: The merge join in PostgreSQL gives other variations depending on which the outer table's index can be scanned, like the nested loop join.

Hash Join:
Another join method used in PostgreSQL for natural joins and equi-joins is called Hash Join. To effectively merge data from two tables, it uses hash tables. Let’s talk about the variations of hash join and its execution.
Hash Join Execution:
Depending on the size of the tables, Hash Join performs differently. It does a straightforward two-phase in-memory hash join if the inner table's size is 25% or less of work_mem. If not, it employs the hybrid hash join with skew technique.
In-Memory Hash Join:
Using a batch hash table, this technique performs the join operation on work_mem. The process consists of two phases: the build phase, during which the inner table tuples are added to the batch, and the second phase is the probe phase, during which comparison of each outer table tuple is carried out to the inner tuples in the batch for joining.Hybrid Hash Join with Skew:
PostgreSQL makes use of the hybrid hash join with skew technique when the tuples of the inner table cannot fit into a single batch in work_mem. It includes a skew batch, multiple batches, and temporary batch files. In the skew batch, inner table tuples are stored that, depending on the join condition, will be merged with outer table tuples that have high frequency values.
Join Access Paths and Join Nodes:
JoinPath structures in PostgreSQL serve as a representation of join access pathways, and join nodes use these structures to effectively carry out join algorithms. They are Nested Loop Node, MergeJoinNode, and HashJoinNode.

NOTE: Reading previous blog will help in better understanding.
This blog is summary of book The Internals of PostgreSQL written by Hironobu SUZUKI.

Top comments (0)