
s-atmech
s-atmech is an independent Open Source, Deep Learning python library which implements attention mechanism as a RNN(Recurrent Neural Network) Layer as Encoder-Decoder system. We are still in development stage so we have just made use of the Bahdanau Attention, commonly referred to as Additive Attention, refer to this paper. The paper aimed to improve the sequence-to-sequence model in machine translation by aligning the decoder with the relevant input sentences and implementing Attention. The Flow of calculating Attention weights in Bahdanau Attention is shown below:
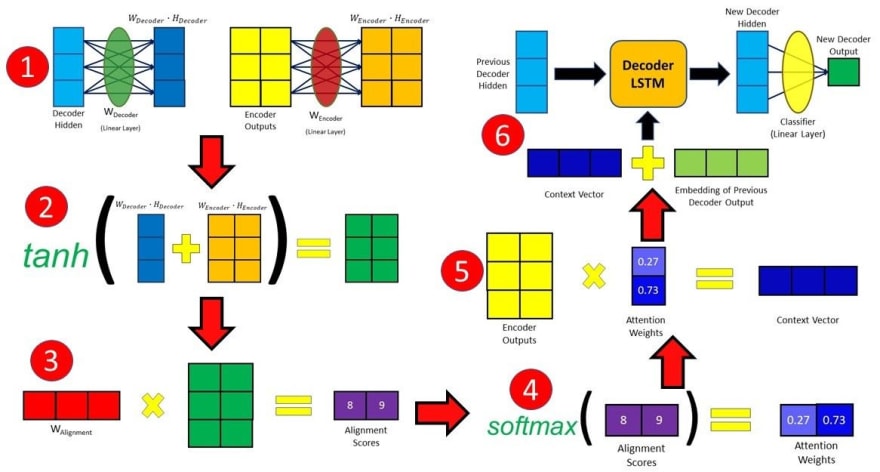
After obtaining all of our encoder outputs, we can start using the decoder to produce outputs. At each time step of the decoder, we have to calculate the alignment score of each encoder output with respect to the decoder input and hidden state at that time step. The alignment score is the essence of the Attention mechanism, as it quantifies the amount of “Attention” the decoder will place on each of the encoder outputs when producing the next output.
The alignment scores for Bahdanau Attention are calculated using the hidden state produced by the decoder in the previous time step and the encoder outputs with the following equation:
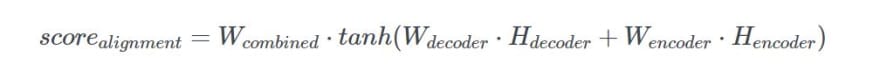
The decoder hidden state and encoder outputs will be passed through their individual Linear layer and have their own individual trainable weights. Thereafter, they will be added together before being passed through a tanhactivation function. The decoder hidden state is added to each encoder output in this case. Lastly, the resultant vector from the previous few steps will undergo matrix multiplication with a trainable vector, obtaining a final alignment score vector which holds a score for each encoder output. After generating the alignment scores vector in the previous step, we can then apply a softmax on this vector to obtain the attention weights. The softmax function will cause the values in the vector to sum up to 1 and each individual value will lie between 0 and 1, therefore representing the weightage each input holds at that time step. After computing the attention weights in the previous step, we can now generate the context vector by doing an element-wise multiplication of the attention weights with the encoder outputs.due to the softmax function in the previous step, if the score of a specific input element is closer to 1 its effect and influence on the decoder output is amplified, whereas if the score is close to 0, its influence is drowned out and nullified. The context vector we produced will then be concatenated with the previous decoder output. It is then fed into the decoder RNN cell to produce a new hidden state and the process repeats itself from step 2. The final output for the time step is obtained by passing the new hidden state through a Linear layer, which acts as a classifier to give the probability scores of the next predicted word. Steps 2 to 4 are repeated until the decoder generates an End Of Sentence token or the output length exceeds a specified maximum length. This above is the entire process how Bhadanau Attention works.
Next in Line:
This is still in alpha stage so we are planning to add a Luong Attention implementation which will be added by 2020. We are also developing a new attention algorithm for our library.
Naming:
s-atmech actually is symbolic name for Sam's Attention Mechanism simple yet catchy! _(^^)/
Installation and Implementation:
To install s-atmech follow the steps:
Install pip:
$ python get-pip.py
Install s-atmech via pip:
$ pip install s-atmech
For upgrade:
$ pip install --upgrade s-atmech
Implementation:
>>> from s-atmech.AttentionLayer import AttentionLayer as atl
Developer Info:
Author: Somyajit Chakraborty
Author-email: somyajitchppr@gmail.com
Team: Bread and Code
Required Libraries:
'numpy',
'pandas',
'tensorflow',
'matplotlib',
'scikit-learn',
'jupyter',
'pillow',
'nltk',
'pyYAML',

Top comments (0)