
Amazon Redshift is a columnar, fully managed cloud data warehouse service in AWS eco system. It used in executing complex, analytical queries on large volume of data sets via MPP (Massive Parallel Processing) architecture. The volume of data can be Giga bytes of Peta bytes.
Important Key features for Redshift:
- It supports virtually unlimited concurrent users for different workloads, such as BI/dashboard reporting, data ingestion, and adhoc data analysis.
- It also monitors user workloads and uses machine learning (ML) to find ways to improve the physical layout of data to further optimize query speeds.
- Amazon Redshift supports industry-leading security to protect your data in transit and at rest. It is compliant with SOC1, SOC2, SOC3, and PCI DSS Level 1 requirements.
- Both structure and semi structure data can be processed, analysed using Amazon redshift. It supports ORC, Parquet, JSON, CSV, Avro format files.
- Amazon Redshift is a fully managed service, user do not worry about tasks such as installing, patching, or updating software and only focus on resources on generating business value rather than maintaining infrastructure.
- It flexibly manages workload priorities so that short, fast-running queries won't get stuck in queues behind long-running queries.
- It Monitors user workloads and uses sophisticated algorithms to find ways to improve the physical layout of data to optimize query speeds
- Amazon redshift has the flexibility to connect different BI tools like QuickSight, Tableau, Power BI and Analytical tools like Jupyter notebook.
- It is fault tolerant which helped in enhance the reliability of your data warehouse cluster with features such as continuous monitoring of cluster health and automatic re-replication of data from failed drives and node replacement as necessary.
- Using Amazon Redshift Spectrum, user can efficiently query and retrieve structured and semi-structured data from files in Amazon Simple Storage Service (Amazon S3) and no need to load the data into Amazon Redshift tables.
- AWS data exchange can be used along with AWS Redshift to load and query third party data sources.
- Amazon Redshift ML can be used to create, train, and apply ML models with standard SQL.
- Redshift integrates well with AWS services to move, transform and load data quickly and reliably (for example: S3, Dyanmo DB, EMR, EC2, Data Pipeline etc )
In this blog, we are going to discuss the below problem statement.
Problem Statement: One of the leading financial companies is planning to use AWS Redshift for their data warehouse. They must align with below compliance requirements.
- Track all audit logs of Redshift cluster There are 3 types of audit logs available in Redshift.
- Connection log – Logs authentication attempts, connections, and disconnections.
- User log – Logs information about changes to database user definitions.
-
User activity log – Logs each query before it's run on the database.
The connection and user logs are useful for security checks, it provides detail on which user is connecting to Redshift cluster, User IP address, connection time etc. The user activity log is useful primarily for troubleshooting purposes. It tracks information about the types of queries that both the users and the system perform in the database. The user activity logs captured the all user activity details like query fired by user, user id and record time details.
Note: ( From Aws documentation)
The connection log, user log, and user activity log are enabled together by using the AWS Management Console, the Amazon Redshift API Reference, or the AWS Command Line Interface (AWS CLI). For the user activity log, you must also enable the enable_user_activity_logging database parameter. If you enable only the audit logging feature, but not the associated parameter, the database audit logs log information for only the connection log and user log, but not for the user activity log. The enable_user_activity_logging parameter is not enabled (false) by default. You can set it to true to enable the user activity log. In this demo we are enable the logging from AWS management console and not considered the user activity log as we are not created in custom parameter group.
- Need to store audit logs securely i.e encryption at rest.
- Need to store audit logs for specific time. Retention policy for the audit log is 6 months.
- A details analytics reports needs to derive from Audit log on Monthly basis.
Let’s jump into the lab.
Step -1: Create Redshift IAM role which will have access to have access to S3.
- Login to AWS Management Console. Search IAM in the aws search bar. Click on IAM
- Click on Roles.
- Click create role.
- Select Trusted entity type as AWS services
- Under Use case tab, search for Redshift and click Next
- In the permission policy, search of S3 and select Amazon S3 full access (Note – It is NOT best practice to give full permission in IAM, for our demo we selected full permission, in prod workloads, better to follow least privilege principles) and click Next.
- Give the name of the role, description and click create role


Step -2: Create and configure a Redshift cluster
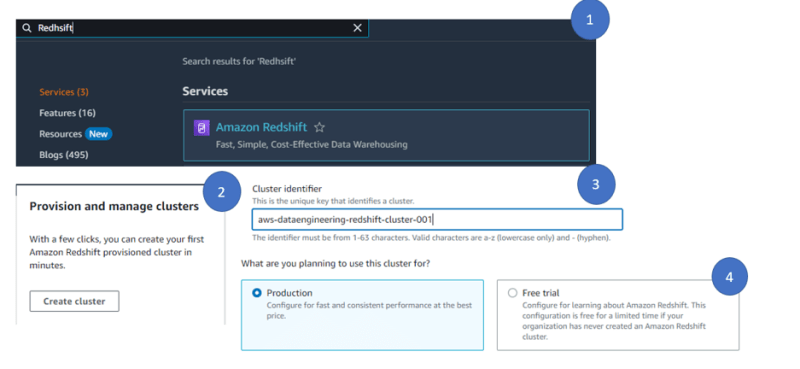
- To create a Redshift Cluster, search Redshift in the aws console search bar.
- Click on create cluster
- Give the name of the cluster under cluster identifier.
- We selected the production option to have more configuration, however you can choose free tier eligible as well for demo.
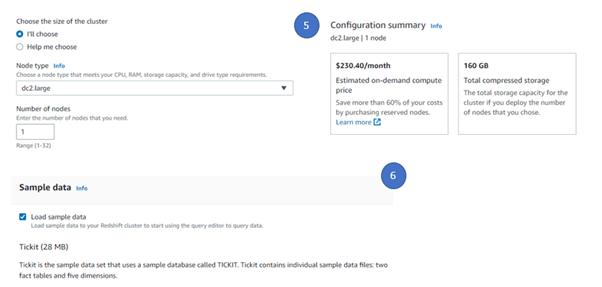
- Select “I’II” option to select the cluster type. This will enable to configure the cluster customize approach. We selected the Node type as dc2.large ( Note – This is NOT under free tier and there will be some cost involved in this case). For our demo purpose, we select the number of nodes as 1 but in real production cases number of nodes will always be greater than 1 to have a master and slave configuration.
- Select the sample data so that by default Redshift will load sample data for you, this will enable to run some sample query and see the results quickly.
- Under Database configuration, give the admin user and password. This user credentials are required to login Redshift cluster and set up other users afterwards.
- Under Associated IAM role, select Associate IAM role, select the IAM role which we created in step-1 and click on Associate IAM role.

- Additional configurations, select the default option. We will configure the audit logging once the cluster is created. Click create cluster to create the cluster

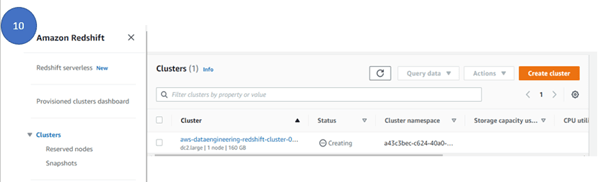
- To see the cluster creation status, click on the cluster on the left panel, click cluster and under cluster, you can see the cluster is under creating status.
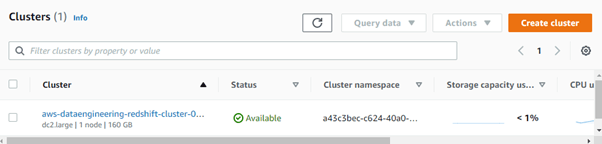
- Once the cluster is configured correctly, you can see the cluster status changed to Available.
- To enable the audit logging, select the cluster, Go to the properties tab and under database configuration, select edit audit logging. Select turn on and select the bucket and prefix where you want to store your audit logs and click save changes.

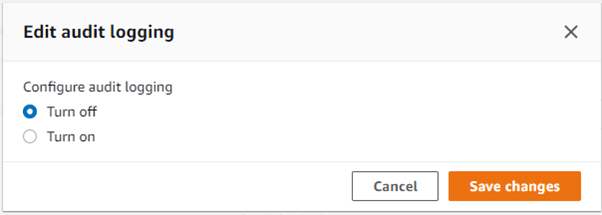
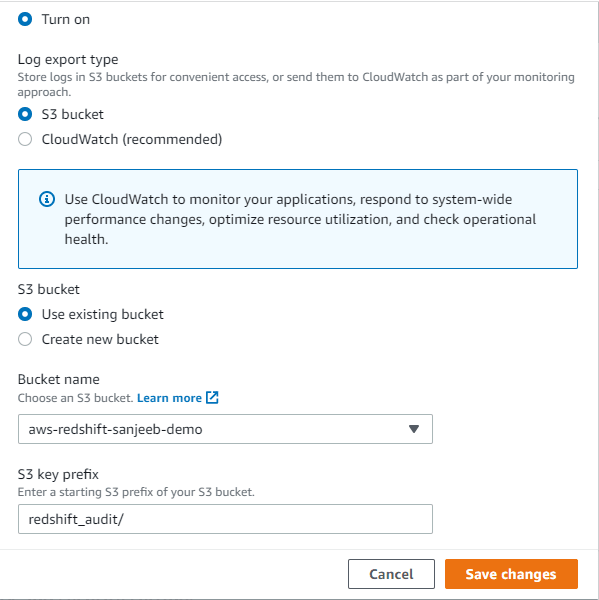
- Once you have enabled the audit logging, you can see the details under database configuration.

- To connect Redshift cluster and run queries, you can install client tool and download the redshift driver from aws redshift console or there is a query editor available in Redshift console and you can connect directly to Redshift database from the query editor. Click on the Query editor v2, it will open a new tab where you can get an query editor to run some sample query.

- Since we have already selected to load some sample data during the creation of Redshift cluster, select the Redshift cluster, select dev database, select public, select Tables and double click any table to have the select statement in the execute command window. Run the sql statement and see the result.

- Once you performed some actions like selecting some record, check the table count, you can see analyze the audit log file which is generated under s3.

- To see the log file, you can download the file locally and open it any editor, one sample snapshot for connection log is

Step -3: Define a Life cycle rule on S3 bucket (audit log) and remove files older than 6 months.
- To ensure all our audit logs are stored in encrypted at rest, The S3 bucket is encrypted by default (This is a new feature introduced by AWS recently, no action is required from user side). You can see it by navigating to the bucket, click properties, check the default encryption.

- To ensure old log files are deleted automatically after 6 months, we will define a S3 life cycle management rule which will delete the files which are created 6 months back. To do the same, navigate to S3 bucket, click on Management, click on Create a life cycle rule.

- 1. Give the life cycle rule name, for our case it is remove-6month-old-file
- 2. Since we created a separate S3 bucket to store the audit logs, select apply to all objects in the bucket and Acknowledge the rule.
- 3. Life cycle rule actions, select Permanently delete noncurrent versions of objects and Delete expired object delete markers or incomplete multipart uploads
- 4. Under Permanently delete noncurrent version, give the value as 180 days.
- 5. Under Delete expired object delete markers or incomplete multipart uploads, checked both the options and put 180 days for the files which are not downloaded completely.


The final step is to terminate your Redshift cluster after your POC . To delete the cluster, select cluster and under action, select delete.
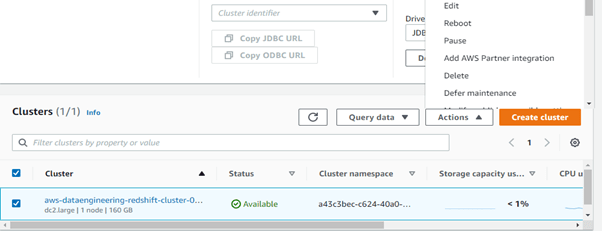
Note
If you do not want to take snapshot, unchecked the create final snap shot option and put the details on the confirmation and click on the delete cluster. It will delete your cluster. Once the cluster is deleted, you can not see the cluster in the cluster list of redshift console.
Reference Material:

Top comments (0)