Se você já passou horas tentando entender um código mal indentado, ou se já se perdeu em um arquivo gigante cheio de funções e classes, sabe como é importante ter ferramentas que ajudem a navegar e entender o código de forma mais inteligente. E é aí que entra a análise sintática (ou parsing, pra quem gosta de um termo em inglês). Basicamente, ela pega aquele monte de texto que a gente chama de código e transforma em uma estrutura organizada, que o computador (e a gente também!) consegue entender e manipular.
Só que, antigamente, fazer essa análise era meio trabalhoso pois fazíamos uso de ferramentas como ANTLR e Bison que são poderosas, mas exigem um conhecimento técnico bem específico e podem ser lentas, especialmente quando o código está em constante mudança. Imagine ter que esperar o editor reanalisar tudo só porque você adicionou uma vírgula ou um parêntese. Chato, né?
É aí que o Tree-sitter aparece como uma opção mais moderna e descomplicada. Ele foi feito pra ser rápido, fácil de integrar e, o melhor de tudo, tolerante a erros. Isso mesmo: ele consegue entender seu código mesmo se ele estiver incompleto ou cheio de bugs. Além disso, ele faz análise incremental, ou seja, só atualiza o que mudou, sem precisar reprocessar o arquivo inteiro. Isso é um alívio, especialmente quando você está trabalhando em projetos grandes. Neste artigo, vamos explorar o que o Tree-sitter tem de especial, como ele pode ajudar no seu dia a dia e como você pode começar a usá-lo pra deixar sua vida de dev um pouco mais fácil. Vamos lá?

Sumário
O que é o Tree-sitter?
Por que a Análise Sintática é Importante?
Entendendo a Árvore Sintática
Exemplo Prático (Java)
Diferença entre CST e AST (Árvore Sintática Abstrata)
Usando o Tree-sitter na Prática
Usando o Tree-sitter Localmente
Scanners externos
Impacto nos Negócios
Limitações
O que é o Tree-sitter?
O Tree-sitter é basicamente uma biblioteca que ajuda a entender o código que a gente escreve. Ele pega o código-fonte, seja em Java, Python, JavaScript ou outras linguagens, e transforma tudo em uma árvore sintática concreta (CST).
Essa árvore é como um mapa que mostra a estrutura do código, com todos os detalhes: palavras-chave, nomes de variáveis, operadores e até mesmo a hierarquia entre eles. O legal é que ele faz isso de forma super eficiente, o que é ótimo para integrar em editores de código e outras ferramentas de desenvolvimento.
Uma das coisas mais legais do Tree-sitter é a análise incremental. Traduzindo: quando você muda uma linha de código, ele não precisa reprocessar o arquivo inteiro. Ele só atualiza a parte da árvore que foi afetada pela mudança. Isso é ótimo para editores de código, que precisam ser rápidos e responsivos, especialmente quando você está digitando e quer ver o realce de sintaxe ou o dobramento de código funcionando sem travamentos.

Outro ponto forte é que ele é tolerante a erros. Isso significa que, mesmo se o seu código estiver incompleto ou cheio de bugs, o Tree-sitter ainda consegue montar uma árvore sintática e manter as funcionalidades básicas. Claro, ele não substitui ferramentas como compiladores ou linters, que fazem verificações mais profundas, mas já ajuda bastante no dia a dia.
O Tree-sitter é bem flexível. Ele tem bindings em várias linguagens, oficiais para C#, Go, Haskell, Java, JavaScript (Node.js e WebAssembly), Kotlin, Python, Rust e Zig. Sem falar nos bindings terceiros produzidos pela comunidade. E é suportado por editores populares como VS Code, Neovim, Atom e Emacs. Só que, para linguagens menos comuns, pode ser necessário fazer uma configuração extra.
Outra vantagem é que ele é genérico. Dá pra usar gramáticas para definir a estrutura de várias linguagens, mas criar uma gramática do zero pode ser um pouco trabalhoso. Por fim, a árvore sintática concreta (CST) que ele gera preserva até os detalhes, como espaços em branco e comentários. Isso é diferente da Árvore Sintática Abstrata (AST), que ignora esses detalhes. A CST é ótima para ferramentas que precisam manipular o código diretamente, como formatadores e refatoradores, mas pode ser um pouco "exagerada" para tarefas que não dependem desses detalhes.
Além disso, ele também trabalha com multi-language documents. Isto é, ele analisa código de diferentes linguagens que estão misturados em um mesmo arquivo (o que é muito comum em projetos que utilizam frameworks front-end como React, Vue e Angular etc...
Por que a Análise Sintática é Importante?
A análise sintática é tipo o "tradutor" que ajuda o computador (e a gente também!) a entender a estrutura do código. Ela pega aquela sopa de letrinhas que a gente chama de código-fonte e organiza tudo, identificando palavras-chave, variáveis, operadores e como eles se relacionam. Sem ela, ferramentas de desenvolvimento seriam bem menos úteis e a vida do dev, muito mais difícil.
Pensa só: quando você abre um arquivo no VSCode e o editor já começa a colorir as palavras-chave, strings e comentários. Isso não é mágica, é a análise sintática em ação. Ela ajuda a deixar o código mais legível e facilita a identificação de erros de cara. Sem isso, seria como ler um texto sem pontuação ou parágrafos. Confuso, né?
Se você observar bem, ferramentas como IntelliJ IDEA usam análise sintática para permitir que você dobre blocos de código, como funções ou loops, e esconda o que não está usando no momento. Isso é ótimo para navegar em arquivos grandes sem se perder. Além disso, quando você começa a digitar, o editor já sugere nomes de variáveis, métodos ou funções, tecnologia que conhecemos como Intellisense. Tudo isso depende da análise sintática para entender o contexto do que você está escrevendo.
Outra funcionalidade que a gente adora é o "Go to Definition" (Ir para Definição) e o "Find All References" (Encontrar Todas as Referências), presentes em editores como o Visual Studio. Essas features permitem que você pule direto para onde uma função foi declarada ou veja todos os lugares onde ela é usada. Tudo isso é possível graças à análise sintática, que mapeia a estrutura do código.
E não podemos esquecer das ferramentas de linting e formatação, como o ESLint e o Prettier. Elas usam análise sintática para identificar problemas de estilo, corrigir erros comuns e até formatar o código automaticamente. Isso ajuda a manter um padrão consistente no projeto, sem precisar ficar revisando manualmente. O Tree-sitter entra nessa história como uma ferramenta moderna que torna a análise sintática rápida e extremamente eficiente.
Ele é o responsável por habilitar muitas dessas funcionalidades em tempo real em editores como Neovim, VSCode, Atom e Emacs. Ou seja, ele é o cara por trás daquela experiência fluida que a gente tanto gosta ao escrever código.

Entendendo a Árvore Sintática
O que é uma Árvore Sintática?
Imagine que o código que você escreve é como uma frase em um idioma. A árvore sintática é uma maneira de "quebrar" essa frase em partes menores, mostrando como cada pedaço se encaixa. Ela é uma representação em forma de árvore da estrutura do código, seguindo as regras de uma gramática formal. Cada "galho" da árvore (chamado de nó) representa uma parte do código, como uma função, uma variável ou um operador.
Por exemplo, uma declaração de função (um nó interno) pode ter um nome de função (um nó folha), uma lista de parâmetros (outros nós internos e folhas) e um corpo de função (mais nós internos). Os nós folha são os menores elementos, como palavras-chave (if, else, for), nomes de variáveis, operadores (+, -, *), números, strings e até mesmo pontuação (;, ., ,).
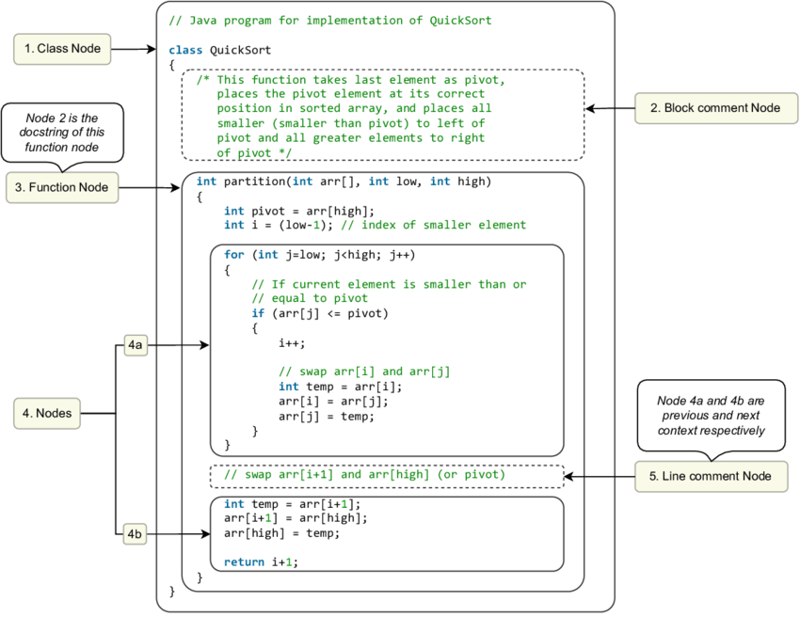
Na imagem acima, você pode ver como classes (1) e funções (3) são extraídas junto com seus comentários (2 e 5). A árvore sintática captura todas essas relações hierárquicas, mostrando como cada parte do código se conecta.
Exemplo Prático (Java)
Vamos dar uma olhada em um exemplo simples em Java:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
Aqui está como o Tree-sitter representaria esse código em uma árvore sintática (CST):
program [0, 0] - [6, 0] // nó raiz
class_declaration [0, 0] - [4, 1] // nó interno
modifiers [0, 0] - [0, 6] // nó interno
public [0, 0] - [0, 6] // nó folha
class [0, 7] - [0, 12] // nó folha
name: identifier [0, 13] - [0, 23] // nó folha
body: class_body [0, 24] - [4, 1] // nó interno
{ [0, 24] - [0, 25] // nó interno
method_declaration [1, 4] - [3, 5] // nó interno
modifiers [1, 4] - [1, 17] // nó interno
public [1, 4] - [1, 10] // nó folha
static [1, 11] - [1, 17] // nó folha
type: void_type [1, 18] - [1, 22] // nó folha
name: identifier [1, 23] - [1, 27] // nó folha
parameters: formal_parameters [1, 27] - [1, 42] // nó interno
( [1, 27] - [1, 28] // nó interno
formal_parameter [1, 28] - [1, 41] // nó interno
type: array_type [1, 28] - [1, 36] // nó interno
element: type_identifier [1, 28] - [1, 34] // nó folha
dimensions: dimensions [1, 34] - [1, 36] // nó interno
[ [1, 34] - [1, 35] // nó interno
] [1, 35] - [1, 36] // nó interno
name: identifier [1, 37] - [1, 41] // nó folha
) [1, 41] - [1, 42] // nó interno
body: block [1, 43] - [3, 5] // nó interno
{ [1, 43] - [1, 44] // nó interno
expression_statement [2, 8] - [2, 44] // nó interno
method_invocation [2, 8] - [2, 43] // nó interno
object: field_access [2, 8] - [2, 18] // nó interno
object: identifier [2, 8] - [2, 14] // nó folha
. [2, 14] - [2, 15] // nó folha
field: identifier [2, 15] - [2, 18] // nó folha
. [2, 18] - [2, 19] // nó folha
name: identifier [2, 19] - [2, 26] // nó folha
arguments: argument_list [2, 26] - [2, 43] // nó interno
( [2, 26] - [2, 27] // nó interno
string_literal [2, 27] - [2, 42] // nó interno
" [2, 27] - [2, 28] // nó folha
string_fragment [2, 28] - [2, 41] // nó interno
" [2, 41] - [2, 42] // nó folha
) [2, 42] - [2, 43] // nó interno
; [2, 43] - [2, 44] // nó folha
} [3, 4] - [3, 5] // nó interno
} [4, 0] - [4, 1] // nó interno
Repare como cada detalhe do código, até mesmo a pontuação e os modificadores, está representado na árvore. Essa é a principal característica da CST: ela preserva todos os detalhes do código original. Isso é super útil para ferramentas que precisam manipular o código diretamente, como formatadores, linters e editores.

Diferença entre CST e AST (Árvore Sintática Abstrata)
Agora, vamos falar sobre a diferença entre a Árvore Sintática Concreta (CST) e a Árvore Sintática Abstrata (AST). Ambas são representações do código, mas servem para propósitos diferentes.
- CST (Concrete Syntax Tree):
- Guarda todos os detalhes do código, incluindo pontuação, espaços em branco e comentários.
- A estrutura da árvore segue exatamente a gramática da linguagem.
- É ótima para ferramentas que precisam mexer diretamente no código, como formatadores e editores.
A CST é como uma "fotografia" do código, mostrando tudo exatamente como está escrito. Aqui está uma definição do livro Compilers: Principles, Techniques, and Tools:
"Uma árvore de análise concreta mostra como o símbolo inicial de uma gramática deriva uma string na linguagem. Isto é, a CST é uma correspondência um-para-um da gramática para uma forma de árvore."
Por exemplo, se você analisar a declaração C return a + 2;, a CST vai mostrar todos os detalhes, incluindo os parênteses e o ponto e vírgula. Mas isso pode ser um pouco "exagerado" para algumas tarefas.
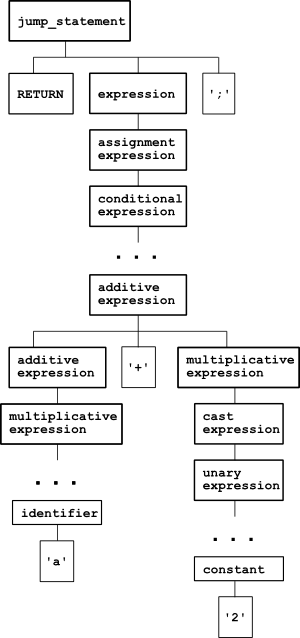
- AST (Abstract Syntax Tree):
- Ignora detalhes "irrelevantes" para o significado do código, como pontuação e espaços em branco.
- A estrutura da árvore é mais simples e focada na semântica do código.
- É usada em compiladores e interpretadores para análise de tipos, otimização e geração de código.
A AST é como um "resumo" do código, mostrando apenas o que é importante para entender o que ele faz. Aqui está uma AST para a declaração return a + 2;, gerada pelo pycparser:
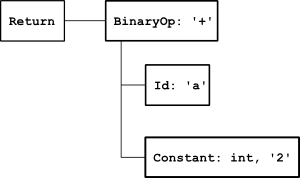
Percebe como a AST é mais simples? Ela não se preocupa com os detalhes sintáticos, como o ponto e vírgula, mas foca no que realmente importa: a estrutura do código. Isso facilita a análise e o processamento posterior, como a geração de código ou a otimização.
Usando o Tree-sitter na Prática
O Tree-sitter Playground é a forma mais rápida e fácil de experimentar o Tree-sitter sem precisar instalar nada. Ele permite que você veja a árvore sintática de qualquer código, teste queries, entenda como as gramáticas do Tree-sitter funcionam e até mesmo brinque com ideias novas. Vamos dar uma olhada em alguns exemplos práticos:
Exemplo 1: Explorando a Estrutura (JavaScript)
- Acesse o Playground: Vá para o Tree-sitter Playground.
-
Selecione a Linguagem: Escolha
JavaScript. - Insira o Código:
function greet(name) {
console.log(`Hello, ${name}!`);
}
- Veja a Árvore Sintática:
Em Tree, você verá algo assim:
program [0, 0] - [3, 0]
function_declaration [0, 0] - [2, 1]
function [0, 0] - [0, 8]
name: identifier [0, 9] - [0, 14]
parameters: formal_parameters [0, 14] - [0, 20]
( [0, 14] - [0, 15]
identifier [0, 15] - [0, 19]
) [0, 19] - [0, 20]
body: statement_block [0, 21] - [2, 1]
{ [0, 21] - [0, 22]
expression_statement [1, 0] - [1, 31]
call_expression [1, 0] - [1, 30]
function: member_expression [1, 0] - [1, 11]
object: identifier [1, 0] - [1, 7]
. [1, 7] - [1, 8]
property: property_identifier [1, 8] - [1, 11]
arguments: arguments [1, 11] - [1, 30]
( [1, 11] - [1, 12]
template_string [1, 12] - [1, 29]
` [1, 12] - [1, 13]
string_fragment [1, 13] - [1, 20]
template_substitution [1, 20] - [1, 27]
${ [1, 20] - [1, 22]
identifier [1, 22] - [1, 26]
} [1, 26] - [1, 27]
string_fragment [1, 27] - [1, 28]
` [1, 28] - [1, 29]
) [1, 29] - [1, 30]
; [1, 30] - [1, 31]
} [2, 0] - [2, 1]
Aqui, você pode ver como cada parte do código é representada na árvore, desde a declaração da função até os detalhes da string template.
- Escreva uma Query:
Habilite o checkbox "Query" e insira o seguinte:
(function_declaration
name: (identifier) @function-name
parameters: (formal_parameters
(identifier) @parameter-name))
- Marque o checkbox Accessibility:
Agora, observe que os nomes greet e name são destacados. Essa query captura o nome da função e os parâmetros. Legal, né?

As queries do Tree-sitter são escritas em uma linguagem baseada em S-expressions (semelhante ao Lisp/Scheme). Elas consistem em padrões que descrevem a estrutura que você deseja encontrar no código. Você pode usar capturas (@nome) para extrair informações específicas dos nós correspondentes.
[!NOTE] O Tree-sitter não se limita a análise e visualização da árvore sintática. Ele oferece um poderoso sistema de queries que permite buscar padrões específicos no código, de forma semelhante a expressões regulares (regex), mas com conhecimento da estrutura sintática. Isso é fundamental para funcionalidades como realce de sintaxe, análise de código e até mesmo refatoração.
Exemplo 2: Usando Queries (Python)
Vamos usar o Playground para encontrar todas as chamadas de função em um código Python.
-
Selecione a Linguagem: Escolha
Python. - Insira o Código:
def my_function(a, b):
print("Sum:", a + b)
another_function(a)
my_function(1, 2)
- Escreva a Query:
Na área "Query", insira:
(call
function: (identifier) @function_name
arguments: (argument_list) @args)
-
call: Procura por nós do tipo "call" (chamadas de função). -
function: (identifier) @function_name: Captura o nome da função. -
arguments: (argument_list) @args: Captura a lista de argumentos.
Essa query vai destacar todas as chamadas de função no código, como print e another_function, junto com seus argumentos.
Exemplo 3: Experimentando com Erros (Qualquer Linguagem)
Agora, vamos brincar com erros de sintaxe. Ainda em Python, insira o seguinte código:
def my_function(a, b):
print("Sum:", a + b)
another_function(a) ???
Agora, escreva a seguinte query na área "Query":
(ERROR) @syntax-error
Observe que o erro é capturado e destacado na árvore sintática:
module [0, 0] - [3, 0]
function_definition [0, 0] - [2, 27]
name: identifier [0, 4] - [0, 15]
parameters: parameters [0, 15] - [0, 21]
identifier [0, 16] - [0, 17]
identifier [0, 19] - [0, 20]
body: block [1, 4] - [2, 27]
expression_statement [1, 4] - [1, 24]
call [1, 4] - [1, 24]
function: identifier [1, 4] - [1, 9]
arguments: argument_list [1, 9] - [1, 24]
string [1, 10] - [1, 16]
string_start [1, 10] - [1, 11]
string_content [1, 11] - [1, 15]
string_end [1, 15] - [1, 16]
binary_operator [1, 18] - [1, 23]
left: identifier [1, 18] - [1, 19]
right: identifier [1, 22] - [1, 23]
ERROR [2, 4] - [2, 27]
call [2, 4] - [2, 23]
function: identifier [2, 4] - [2, 20]
arguments: argument_list [2, 20] - [2, 23]
identifier [2, 21] - [2, 22]
ERROR [2, 24] - [2, 27]
Interessante, não? Com isso, você pode usar o Tree-sitter para detectar erros de sintaxe em qualquer projeto, não apenas em Python.

Usando o Tree-sitter Localmente
Depois de brincar com o Tree-sitter no Playground, é hora de levar a diversão para o seu próprio ambiente. A ferramenta de linha de comando tree-sitter-cli facilita o gerenciamento das gramáticas e a integração do Tree-sitter nos seus projetos. Vamos ver como configurar tudo isso localmente.
Passos para Configuração:
-
Pré-requisitos:
- Antes de começar, certifique-se de ter o Node.js e npm instalados. Se você já tem, pode pular essa parte.
Instale o
tree-sitter-cliglobalmente:
Para começar, instale o tree-sitter-cli globalmente usando o npm. Esse pacote é essencial para gerar parsers e gerenciar gramáticas:
npm install -g tree-sitter-cli
Isso vai deixar o comando tree-sitter disponível no seu terminal.
- Configure o diretório das gramáticas:
Agora, crie um arquivo de configuração para o Tree-sitter. Execute o seguinte comando:
tree-sitter init-config
Isso cria um arquivo chamado config.json no diretório ~/.config/tree-sitter/. Abra esse arquivo e adicione o caminho absoluto para o diretório onde você vai clonar as gramáticas. Por exemplo:
{
"parser-directories": [
"/caminho/absoluto/para/suas_gramaticas" // Linux/macOS/Windows
]
}
Se você estiver no Windows, pode ser algo assim:
{
"parser-directories": [
"D:\\path\\to\\projects\\tree-sitter-python"
]
}
Dica: Use caminhos absolutos para evitar problemas.
- Clone e prepare as gramáticas:
Agora, é hora de baixar e configurar as gramáticas das linguagens que você quer usar. Vamos usar Python como exemplo:
- Navegue até o diretório que você configurou no
config.json. -
Clone o repositório da gramática do Python:
git clone https://github.com/tree-sitter/tree-sitter-python -
Entre no diretório clonado:
cd tree-sitter-python -
Gere o parser e instale as dependências (se houver):
tree-sitter generate npm install # Instala dependências de compilação, se necessário
Repita esses passos para cada linguagem que você quiser usar. Por exemplo, para JavaScript, você faria:
git clone https://github.com/tree-sitter/tree-sitter-javascript
cd tree-sitter-javascript
tree-sitter generate
npm install
- Analisando Arquivos:
Agora que tudo está configurado, você pode começar a usar o Tree-sitter para analisar seus arquivos. Vamos testar com um exemplo simples em Python:
-
Crie um arquivo
teste.pycom o seguinte código:
def add(x, y): return x + y -
Execute o comando para analisar o arquivo e gerar a árvore sintática concreta (CST):
tree-sitter parse /caminho/absoluto/para/teste.py --cst
A saída será algo assim:
0:0 - 1:14 module
0:0 - 1:14 function_definition
0:0 - 0:3 def
0:4 - 0:7 identifier (add)
0:7 - 0:8 (
0:8 - 0:9 identifier (x)
0:9 - 0:10 ,
0:11 - 0:12 identifier (y)
0:12 - 0:13 )
0:13 - 0:14 :
1:4 - 1:10 return
1:11 - 1:12 identifier (x)
1:13 - 1:14 +
1:15 - 1:16 identifier (y)
Aqui, você pode ver como o Tree-sitter quebra o código em uma árvore sintática, mostrando cada parte do código e sua estrutura. Sugiro que explore mais a fundo essa ferramenta, ela é muito poderosa e pode ser usada para criar ferramentas muito úteis.
Scanners externos
Imagina que você queira dividir a forma como o Tree-sitter analisa o código com algum scanner externo. Ele deixa você criar scanners externos em C pra lidar com esses casos. Por exemplo, no Python, a indentação e dedentação são tratadas por um scanner externo. Isso faz com que o Tree-sitter consiga lidar com linguagens que têm regras mais complexas, tipo Python, Ruby, Bash, Yaml e por aí vai...
E olha só, ele ainda tem um sistema de testes integrado que ajuda a validar a gramática e as queries. Você pode criar testes em arquivos de texto na pasta test/corpus/ que geralmente você encontra no repositório da gramática, onde cada teste tem um pedaço de código e a árvore sintática que você espera. Isso é super útil pra garantir que a gramática tá funcionando direitinho e que as queries estão pegando os nós certos. Dá uma olhada no repositório da gramática do Python pra ver como é a estrutura de testes.
Impacto nos Negócios
O Tree-sitter não é apenas uma ferramenta para analisar código; ele é um guardião do seu repositório, capaz de criar regras de alerta e análises dinâmicas que impedem problemas antes que eles cheguem à base de código principal. Vamos explorar como ele pode ser usado para criar fluxos automatizados que bloqueiam merges e PRs (Pull Requests) com base em regras específicas, como falta de dependências, uso indevido de bibliotecas ou violações de padrões de código.
Por exemplo, você já se deparou com um PR que introduziu uma dependência desnecessária ou usou uma biblioteca de forma indevida? Ou pior: um PR que quebrou o build porque faltava uma dependência crítica? Esses problemas são comuns e podem causar atrasos significativos, especialmente em equipes grandes ou distribuídas.
Com o Tree-sitter, você pode criar regras de alerta que analisam o código em tempo real, durante o processo de CI/CD (Integração Contínua/Entrega Contínua). Essas regras podem ser integradas ao GitHub Actions, por exemplo, para bloquear merges ou PRs que não atendam aos critérios definidos.
Imagine que sua equipe está desenvolvendo um projeto em Python e você quer garantir que ninguém use a biblioteca requests de forma indevida (por exemplo, sem tratamento de exceções). Com o Tree-sitter, você pode criar uma query que detecta chamadas para requests.get sem um bloco try-except ao redor. Se essa situação for detectada, o GitHub Actions pode bloquear o merge e notificar o desenvolvedor.
Indicadores que você pode gerar:
- Número de PRs bloqueados por uso indevido de bibliotecas.
- Tempo economizado ao evitar bugs relacionados a dependências.
- Nível de conformidade com as regras de código da equipe.
2. Verificação de Dependências: Garantindo que Nada Falte
Em um cenário hipotético, um desenvolvedor esquece de adicionar uma dependência ao requirements.txt (ou equivalente) e o código quebra em produção. Isso já aconteceu com você? Com o Tree-sitter, você pode evitar esse tipo de problema criando regras que verificam se todas as bibliotecas usadas no código estão declaradas no arquivo de dependências.
Ou algo como: uma equipe que está trabalhando em um projeto Node.js, e um desenvolvedor esqueceu de adicionar uma biblioteca ao package.json. Com o Tree-sitter, você pode criar uma query que detecta chamadas para bibliotecas não listadas no package.json e bloquear o merge até que a dependência seja adicionada.
Indicadores que você pode gerar:
- Número de PRs bloqueados por falta de dependências.
- Tempo economizado ao evitar builds quebrados.
- Nível de conformidade com as regras de dependências.
3. Bloqueando Uso de Bibliotecas Obsoletas ou Inseguras
Uma biblioteca obsoleta ou insegura é introduzida no projeto, e ninguém percebe até que seja tarde demais. Isso pode levar a vulnerabilidades de segurança ou problemas de compatibilidade no futuro. Você pode criar regras que detectam o uso de bibliotecas obsoletas ou inseguras e bloquear o merge até que a biblioteca seja substituída.
Por exemplo, sua equipe está desenvolvendo um projeto em Java, e você quer garantir que ninguém use a biblioteca log4j (famosa por suas vulnerabilidades de segurança). Com o Tree-sitter, você pode criar uma query que detecta importações de log4j e bloquear o merge automaticamente e usando a tecnologia que bem entender, com a linguagem de programação que bem entender.
Indicadores que você pode gerar:
- Número de PRs bloqueados por uso de bibliotecas obsoletas ou inseguras.
- Tempo economizado ao evitar vulnerabilidades de segurança.
- Nível de conformidade com as políticas de segurança da empresa.
4. Garantindo Padrões de Código com Análise Dinâmica
Cada desenvolvedor tem seu estilo de codificação, e isso pode levar a inconsistências no código, especialmente em equipes grandes. Manter um padrão de código é essencial para a manutenção e escalabilidade do projeto. Você pode criar regras que verificam se o código segue os padrões da equipe, como nomenclatura de variáveis, formatação e uso de comentários.
Se o código não seguir as regras, o merge é bloqueado até que as correções sejam feitas. Por exemplo, sua equipe está desenvolvendo um projeto em Python, e você quer garantir que todas as funções tenham docstrings. Com o Tree-sitter, você pode criar uma query que detecta funções sem docstrings e bloquear o merge até que elas sejam adicionadas.
Indicadores que você pode gerar:
- Número de PRs bloqueados por violações de padrões de código.
- Tempo economizado ao evitar revisões manuais.
- Nível de conformidade com os padrões de código da equipe.
5. Integração com GitHub Actions: Automatizando Tudo
Processos manuais de revisão de código são lentos e propensos a erros. Automatizar esses processos é essencial para manter a agilidade e a qualidade do projeto. Com o GitHub Actions, você pode integrar as queries do Tree-sitter ao fluxo de CI/CD, criando um pipeline automatizado que analisa o código em cada PR e bloqueia o merge se problemas forem detectados.
Por exemplo, sua equipe está desenvolvendo um projeto em JavaScript, e você quer garantir que nenhum PR seja mergeado sem passar por uma análise completa do código. Com o Tree-sitter e o GitHub Actions, você pode criar um workflow que executa as queries do Tree-sitter em cada PR e bloqueia o merge se problemas forem detectados.
Indicadores que você pode gerar:
- Número de PRs analisados e bloqueados.
- Tempo economizado ao evitar revisões manuais.
- Nível de conformidade com as regras de código da equipe.
O Tree-sitter não é apenas uma ferramenta para analisar código; ele é um guardião do seu repositório, capaz de criar regras de alerta e análises dinâmicas que impedem problemas antes que eles cheguem à base de código principal. Com integrações como o GitHub Actions, você pode automatizar esses processos, garantindo que cada PR e merge esteja em conformidade com as regras da equipe.

Limitações
Embora o Tree-sitter seja uma ferramenta poderosa, ele tem algumas limitações:
O Tree-sitter pode ter dificuldades com linguagens de programação que possuem gramáticas inerentemente ambíguas. A ambiguidade ocorre quando a mesma sequência de tokens pode ser interpretada de múltiplas maneiras pela gramática. Embora o Tree-sitter tente lidar com isso, pode haver casos em que a árvore sintática gerada não seja a esperada.
Além disso, criar gramáticas para linguagens com sintaxes muito complexas (como C++) pode ser um desafio. A gramática precisa ser cuidadosamente projetada para garantir que o Tree-sitter possa analisar o código de forma eficiente e precisa.
Outra limitação é que o Tree-sitter não lida nativamente com pré-processadores, como o pré-processador do C/C++. Isso significa que ele analisa o código após o pré-processamento. Se o seu código depende fortemente de macros e diretivas de pré-processamento, a árvore sintática gerada pelo Tree-sitter pode não refletir com precisão a estrutura original do código antes do pré-processamento.
Existem workarounds para isso, como executar o pré-processador separadamente e fornecer o código pré-processado para o Tree-sitter, mas isso adiciona complexidade. Além disso, ele entende a estrutura do código, mas não seu significado. Ele não realiza análise semântica (como verificação de tipos ou resolução de símbolos). Para isso, você precisará usar outras ferramentas, como um servidor LSP, em conjunto com o Tree-sitter.
O Tree-sitter, como ferramenta de análise sintática, opera em nível de parsing e lexing. Ou seja, ele divide o código em tokens e os estrutura hierarquicamente. Contudo, o Tree-sitter, em si, não é uma ferramenta completa de análise estática de código.
E embora exista um número crescente de gramáticas disponíveis para o Tree-sitter, nem todas as linguagens de programação são suportadas. Se você precisar analisar uma linguagem que não possui uma gramática, precisará criar uma (o que pode ser trabalhoso) ou usar outra ferramenta. Apesar de mais simples que ferramentas como o ANTLR, aprender a criar queries e a lidar com a API do Tree-sitter, bem como a estrutura da árvore, tem uma certa curva de aprendizado pois, precisa compreender bem como funciona a linguagem de programação scheme.

Referências e Recursos Adicionais
- Site oficial do Tree-sitter: https://tree-sitter.github.io/tree-sitter/
- Repositório do Tree-sitter no GitHub: https://github.com/tree-sitter/tree-sitter
- Criando Parsers (Gramáticas): https://tree-sitter.github.io/tree-sitter/creating-parsers
- Usando Parsers (API): https://tree-sitter.github.io/tree-sitter/using-parsers
- Linguagem de Consulta: https://tree-sitter.github.io/tree-sitter/using-parsers#query-syntax
- Exemplos de gramáticas:
- Integração com Neovim (nvim-treesitter):
- Language Server Protocol (LSP): https://microsoft.github.io/language-server-protocol/

Top comments (0)